 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnvBridge: Bridging Diverse Environments with Cross-Environment Knowledge Transfer for Embodied AI
Oct 22, 2024



In recent years, Large Language Models (LLMs) have demonstrated high reasoning capabilities, drawing attention for their applications as agents in various decision-making processes. One notably promising application of LLM agents is robotic manipulation. Recent research has shown that LLMs can generate text planning or control code for robots, providing substantial flexibility and interaction capabilities. However, these methods still face challenges in terms of flexibility and applicability across different environments, limiting their ability to adapt autonomously. Current approaches typically fall into two categories: those relying on environment-specific policy training, which restricts their transferability, and those generating code actions based on fixed prompts, which leads to diminished performance when confronted with new environments. These limitations significantly constrain the generalizability of agents in robotic manipulation. To address these limitations, we propose a novel method called EnvBridge. This approach involves the retention and transfer of successful robot control codes from source environments to target environments. EnvBridge enhances the agent's adaptability and performance across diverse settings by leveraging insights from multiple environments. Notably, our approach alleviates environmental constraints, offering a more flexible and generalizable solution for robotic manipulation tasks. We validated the effectiveness of our method using robotic manipulation benchmarks: RLBench, MetaWorld, and CALVIN. Our experiments demonstrate that LLM agents can successfully leverage diverse knowledge sources to solve complex tasks. Consequently, our approach significantly enhances the adaptability and robustness of robotic manipulation agents in planning across diverse environments.
RAP: Retrieval-Augmented Planning with Contextual Memory for Multimodal LLM Agents
Feb 06, 2024



Owing to recent advancements, Large Language Models (LLMs) can now be deployed as agents for increasingly complex decision-making applications in areas including robotics, gaming, and API integration. However, reflecting past experiences in current decision-making processes, an innate human behavior, continues to pose significant challenges. Addressing this, we propose Retrieval-Augmented Planning (RAP) framework, designed to dynamically leverage past experiences corresponding to the current situation and context, thereby enhancing agents' planning capabilities. RAP distinguishes itself by being versatile: it excels in both text-only and multimodal environments, making it suitable for a wide range of tasks. Empirical evaluations demonstrate RAP's effectiveness, where it achieves SOTA performance in textual scenarios and notably enhances multimodal LLM agents' performance for embodied tasks. These results highlight RAP's potential in advancing the functionality and applicability of LLM agents in complex, real-world applications.
Multi-View Dreaming: Multi-View World Model with Contrastive Learning
Mar 15, 2022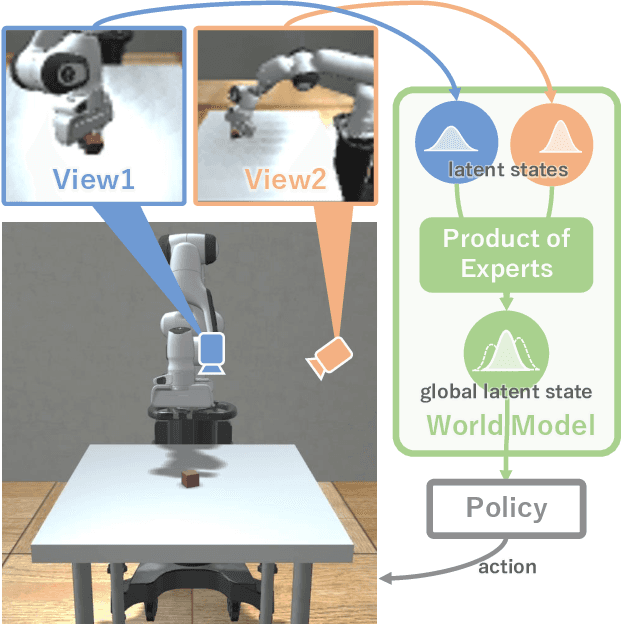
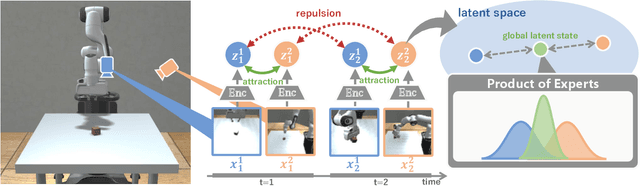
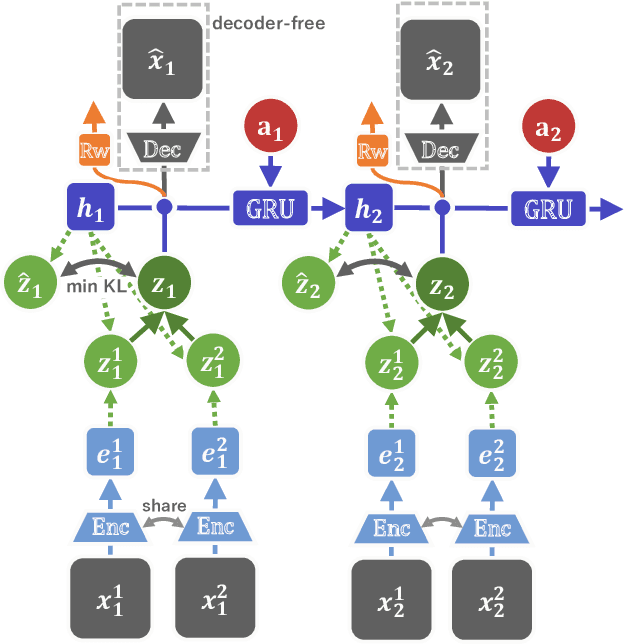
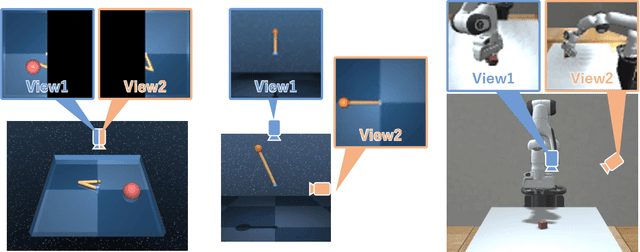
In this paper, we propose Multi-View Dreaming, a novel reinforcement learning agent for integrated recognition and control from multi-view observations by extending Dreaming. Most current reinforcement learning method assumes a single-view observation space, and this imposes limitations on the observed data, such as lack of spatial information and occlusions. This makes obtaining ideal observational information from the environment difficult and is a bottleneck for real-world robotics applications. In this paper, we use contrastive learning to train a shared latent space between different viewpoints, and show how the Products of Experts approach can be used to integrate and control the probability distributions of latent states for multiple viewpoints. We also propose Multi-View DreamingV2, a variant of Multi-View Dreaming that uses a categorical distribution to model the latent state instead of the Gaussian distribution. Experiments show that the proposed method outperforms simple extensions of existing methods in a realistic robot control task.
Integration of Imitation Learning using GAIL and Reinforcement Learning using Task-achievement Rewards via Probabilistic Generative Model
Jul 03, 2019
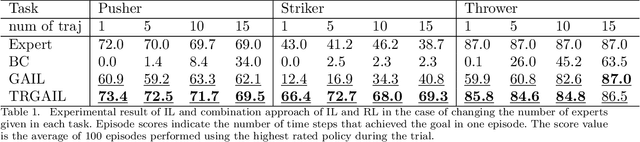
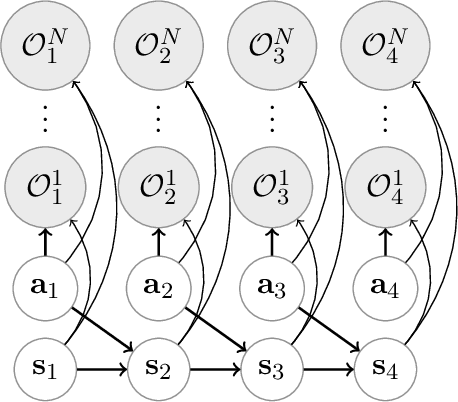
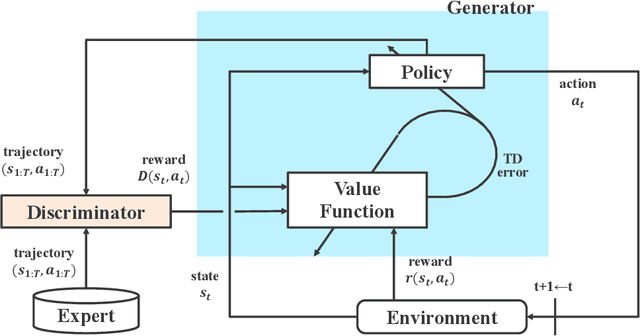
Integration of reinforcement learning and imitation learning is an important problem that has been studied for a long time in the field of intelligent robotics. Reinforcement learning optimizes policies to maximize the cumulative reward, whereas imitation learning attempts to extract general knowledge about the trajectories demonstrated by experts, i.e., demonstrators. Because each of them has their own drawbacks, methods combining them and compensating for each set of drawbacks have been explored thus far. However, many of the methods are heuristic and do not have a solid theoretical basis. In this paper, we present a new theory for integrating reinforcement and imitation learning by extending the probabilistic generative model framework for reinforcement learning, {\it plan by inference}. We develop a new probabilistic graphical model for reinforcement learning with multiple types of rewards and a probabilistic graphical model for Markov decision processes with multiple optimality emissions (pMDP-MO). Furthermore, we demonstrate that the integrated learning method of reinforcement learning and imitation learning can be formulated as a probabilistic inference of policies on pMDP-MO by considering the output of the discriminator in generative adversarial imitation learning as an additional optimal emission observation. We adapt the generative adversarial imitation learning and task-achievement reward to our proposed framework, achieving significantly better performance than agents trained with reinforcement learning or imitation learning alone. Experiments demonstrate that our framework successfully integrates imitation and reinforcement learning even when the number of demonstrators is only a few.