 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafeWork-R1: Coevolving Safety and Intelligence under the AI-45$^{\circ}$ Law
Jul 24, 2025



We introduce SafeWork-R1, a cutting-edge multimodal reasoning model that demonstrates the coevolution of capabilities and safety. It is developed by our proposed SafeLadder framework, which incorporates large-scale, progressive, safety-oriented reinforcement learning post-training, supported by a suite of multi-principled verifiers. Unlike previous alignment methods such as RLHF that simply learn human preferences, SafeLadder enables SafeWork-R1 to develop intrinsic safety reasoning and self-reflection abilities, giving rise to safety `aha' moments. Notably, SafeWork-R1 achieves an average improvement of $46.54\%$ over its base model Qwen2.5-VL-72B on safety-related benchmarks without compromising general capabilities, and delivers state-of-the-art safety performance compared to leading proprietary models such as GPT-4.1 and Claude Opus 4. To further bolster its reliability, we implement two distinct inference-time intervention methods and a deliberative search mechanism, enforcing step-level verification. Finally, we further develop SafeWork-R1-InternVL3-78B, SafeWork-R1-DeepSeek-70B, and SafeWork-R1-Qwen2.5VL-7B. All resulting models demonstrate that safety and capability can co-evolve synergistically, highlighting the generalizability of our framework in building robust, reliable, and trustworthy general-purpose AI.
Behave Your Motion: Habit-preserved Cross-category Animal Motion Transfer
Jul 10, 2025Animal motion embodies species-specific behavioral habits, making the transfer of motion across categories a critical yet complex task for applications in animation and virtual reality. Existing motion transfer methods, primarily focused on human motion, emphasize skeletal alignment (motion retargeting) or stylistic consistency (motion style transfer), often neglecting the preservation of distinct habitual behaviors in animals. To bridge this gap, we propose a novel habit-preserved motion transfer framework for cross-category animal motion. Built upon a generative framework, our model introduces a habit-preservation module with category-specific habit encoder, allowing it to learn motion priors that capture distinctive habitual characteristics. Furthermore, we integrate a large language model (LLM) to facilitate the motion transfer to previously unobserved species. To evaluate the effectiveness of our approach, we introduce the DeformingThings4D-skl dataset, a quadruped dataset with skeletal bindings, and conduct extensive experiments and quantitative analyses, which validate the superiority of our proposed model.
Leader and Follower: Interactive Motion Generation under Trajectory Constraints
Feb 17, 2025



With the rapid advancement of game and film production, generating interactive motion from texts has garnered significant attention due to its potential to revolutionize content creation processes. In many practical applications, there is a need to impose strict constraints on the motion range or trajectory of virtual characters. However, existing methods that rely solely on textual input face substantial challenges in accurately capturing the user's intent, particularly in specifying the desired trajectory. As a result, the generated motions often lack plausibility and accuracy. Moreover, existing trajectory - based methods for customized motion generation rely on retraining for single - actor scenarios, which limits flexibility and adaptability to different datasets, as well as interactivity in two-actor motions. To generate interactive motion following specified trajectories, this paper decouples complex motion into a Leader - Follower dynamic, inspired by role allocation in partner dancing. Based on this framework, this paper explores the motion range refinement process in interactive motion generation and proposes a training-free approach, integrating a Pace Controller and a Kinematic Synchronization Adapter. The framework enhances the ability of existing models to generate motion that adheres to trajectory by controlling the leader's movement and correcting the follower's motion to align with the leader. Experimental results show that the proposed approach, by better leveraging trajectory information, outperforms existing methods in both realism and accuracy.
Causal Deciphering and Inpainting in Spatio-Temporal Dynamics via Diffusion Model
Sep 29, 2024



Spatio-temporal (ST) prediction has garnered a De facto attention in earth sciences, such as meteorological prediction, human mobility perception. However, the scarcity of data coupled with the high expenses involved in sensor deployment results in notable data imbalances. Furthermore, models that are excessively customized and devoid of causal connections further undermine the generalizability and interpretability. To this end, we establish a causal framework for ST predictions, termed CaPaint, which targets to identify causal regions in data and endow model with causal reasoning ability in a two-stage process. Going beyond this process, we utilize the back-door adjustment to specifically address the sub-regions identified as non-causal in the upstream phase. Specifically, we employ a novel image inpainting technique. By using a fine-tuned unconditional Diffusion Probabilistic Model (DDPM) as the generative prior, we in-fill the masks defined as environmental parts, offering the possibility of reliable extrapolation for potential data distributions. CaPaint overcomes the high complexity dilemma of optimal ST causal discovery models by reducing the data generation complexity from exponential to quasi-linear levels. Extensive experiments conducted on five real-world ST benchmarks demonstrate that integrating the CaPaint concept allows models to achieve improvements ranging from 4.3% to 77.3%. Moreover, compared to traditional mainstream ST augmenters, CaPaint underscores the potential of diffusion models in ST enhancement, offering a novel paradigm for this field. Our project is available at https://anonymous.4open.science/r/12345-DFCC.
TAAT: Think and Act from Arbitrary Texts in Text2Motion
Apr 23, 2024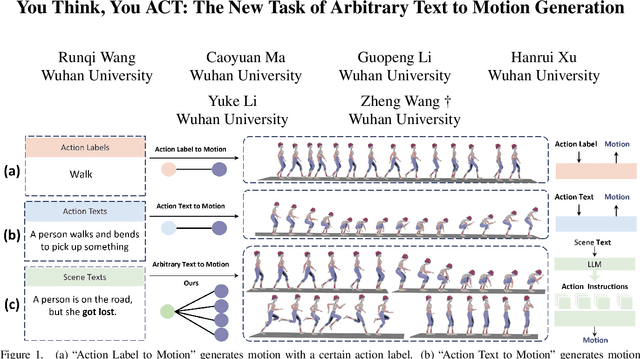

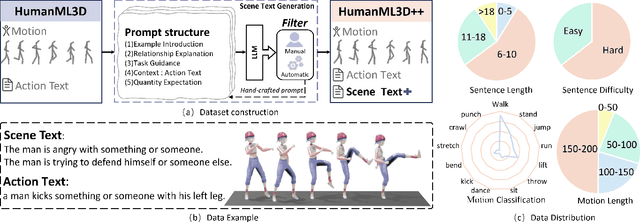

Text2Motion aims to generate human motions from texts. Existing datasets rely on the assumption that texts include action labels (such as "walk, bend, and pick up"), which is not flexible for practical scenarios. This paper redefines this problem with a more realistic assumption that the texts are arbitrary. Specifically, arbitrary texts include existing action texts composed of action labels (e.g., A person walks and bends to pick up something), and introduce scene texts without explicit action labels (e.g., A person notices his wallet on the ground ahead). To bridge the gaps between this realistic setting and existing datasets, we expand the action texts on the HumanML3D dataset to more scene texts, thereby creating a new HumanML3D++ dataset including arbitrary texts. In this challenging dataset, we benchmark existing state-of-the-art methods and propose a novel two-stage framework to extract action labels from arbitrary texts by the Large Language Model (LLM) and then generate motions from action labels. Extensive experiments are conducted under different application scenarios to validate the effectiveness of the proposed framework on existing and proposed datasets. The results indicate that Text2Motion in this realistic setting is very challenging, fostering new research in this practical direction. Our dataset and code will be released.
HumanNeRF-SE: A Simple yet Effective Approach to Animate HumanNeRF with Diverse Poses
Dec 04, 2023We present HumanNeRF-SE, which can synthesize diverse novel pose images with simple input. Previous HumanNeRF studies require large neural networks to fit the human appearance and prior knowledge. Subsequent methods build upon this approach with some improvements. Instead, we reconstruct this approach, combining explicit and implicit human representations with both general and specific mapping processes. Our key insight is that explicit shape can filter the information used to fit implicit representation, and frozen general mapping combined with point-specific mapping can effectively avoid overfitting and improve pose generalization performance. Our explicit and implicit human represent combination architecture is extremely effective. This is reflected in our model's ability to synthesize images under arbitrary poses with few-shot input and increase the speed of synthesizing images by 15 times through a reduction in computational complexity without using any existing acceleration modules. Compared to the state-of-the-art HumanNeRF studies, HumanNeRF-SE achieves better performance with fewer learnable parameters and less training time (see Figure 1).
Improving Stack Overflow question title generation with copying enhanced CodeBERT model and bi-modal information
Sep 27, 2021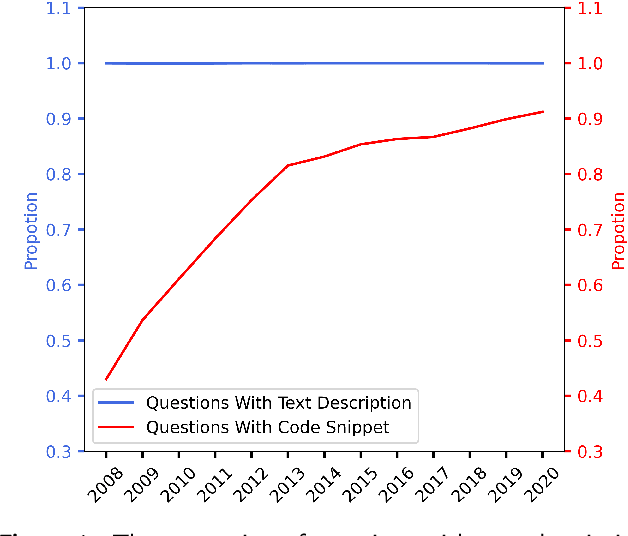
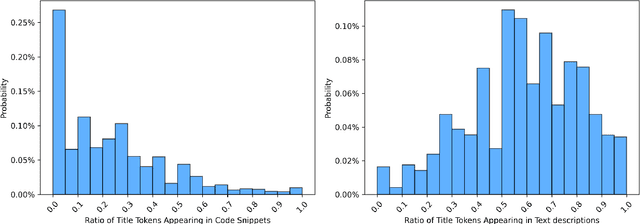
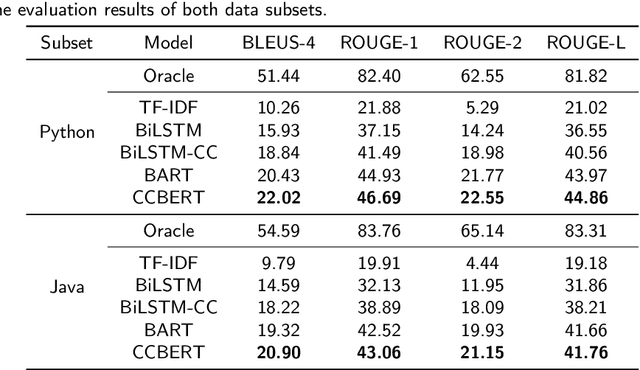
Context: Stack Overflow is very helpful for software developers who are seeking answers to programming problems. Previous studies have shown that a growing number of questions are of low-quality and thus obtain less attention from potential answerers. Gao et al. proposed a LSTM-based model (i.e., BiLSTM-CC) to automatically generate question titles from the code snippets to improve the question quality. However, only using the code snippets in question body cannot provide sufficient information for title generation, and LSTMs cannot capture the long-range dependencies between tokens. Objective: We propose CCBERT, a deep learning based novel model to enhance the performance of question title generation by making full use of the bi-modal information of the entire question body. Methods: CCBERT follows the encoder-decoder paradigm, and uses CodeBERT to encode the question body into hidden representations, a stacked Transformer decoder to generate predicted tokens, and an additional copy attention layer to refine the output distribution. Both the encoder and decoder perform the multi-head self-attention operation to better capture the long-range dependencies. We build a dataset containing more than 120,000 high-quality questions filtered from the data officially published by Stack Overflow to verify the effectiveness of the CCBERT model. Results: CCBERT achieves a better performance on the dataset, and especially outperforms BiLSTM-CC and a multi-purpose pre-trained model (BART) by 14% and 4% on average, respectively. Experiments on both code-only and low-resource datasets also show the superiority of CCBERT with less performance degradation, which are 40% and 13.5% for BiLSTM-CC, while 24% and 5% for CCBERT, respectively.