 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAAT: Think and Act from Arbitrary Texts in Text2Motion
Apr 23, 2024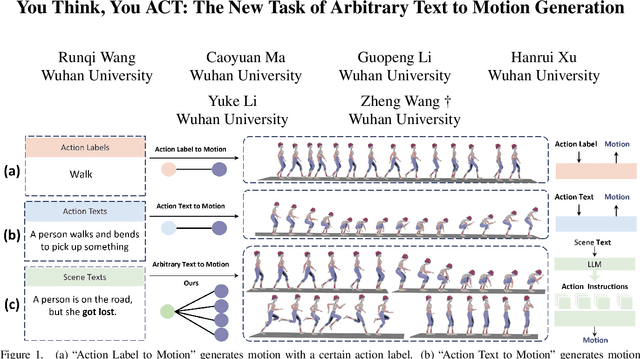

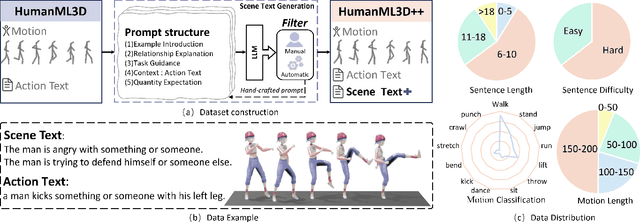

Text2Motion aims to generate human motions from texts. Existing datasets rely on the assumption that texts include action labels (such as "walk, bend, and pick up"), which is not flexible for practical scenarios. This paper redefines this problem with a more realistic assumption that the texts are arbitrary. Specifically, arbitrary texts include existing action texts composed of action labels (e.g., A person walks and bends to pick up something), and introduce scene texts without explicit action labels (e.g., A person notices his wallet on the ground ahead). To bridge the gaps between this realistic setting and existing datasets, we expand the action texts on the HumanML3D dataset to more scene texts, thereby creating a new HumanML3D++ dataset including arbitrary texts. In this challenging dataset, we benchmark existing state-of-the-art methods and propose a novel two-stage framework to extract action labels from arbitrary texts by the Large Language Model (LLM) and then generate motions from action labels. Extensive experiments are conducted under different application scenarios to validate the effectiveness of the proposed framework on existing and proposed datasets. The results indicate that Text2Motion in this realistic setting is very challenging, fostering new research in this practical direction. Our dataset and code will be released.