 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical knowledge guided fault intensity diagnosis of complex industrial systems
Aug 17, 2025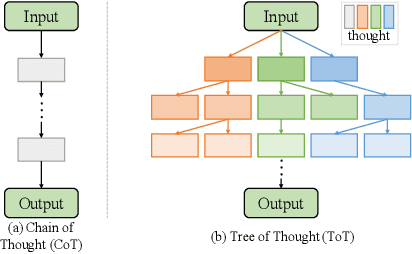
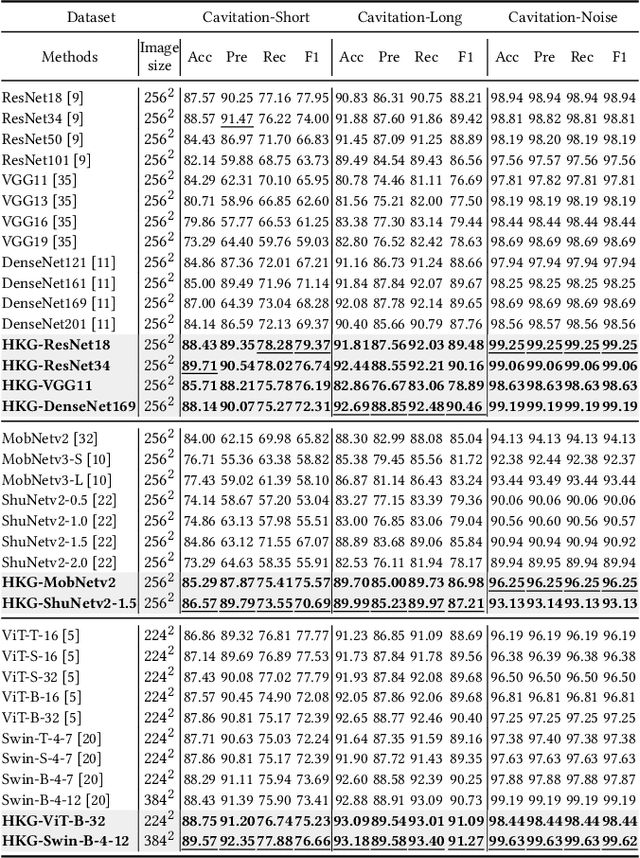
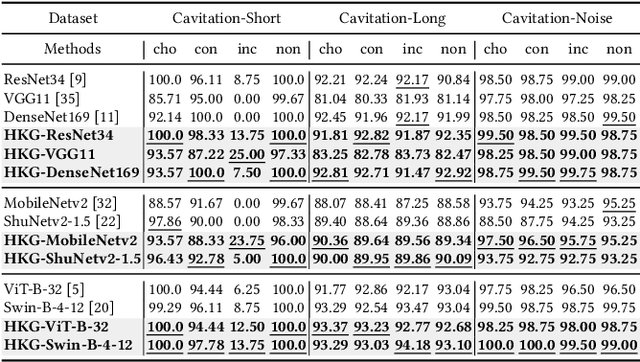
Fault intensity diagnosis (FID) plays a pivotal role in monitoring and maintaining mechanical devices within complex industrial systems. As current FID methods are based on chain of thought without considering dependencies among target classes. To capture and explore dependencies, we propose a hierarchical knowledge guided fault intensity diagnosis framework (HKG) inspired by the tree of thought, which is amenable to any representation learning methods. The HKG uses graph convolutional networks to map the hierarchical topological graph of class representations into a set of interdependent global hierarchical classifiers, where each node is denoted by word embeddings of a class. These global hierarchical classifiers are applied to learned deep features extracted by representation learning, allowing the entire model to be end-to-end learnable. In addition, we develop a re-weighted hierarchical knowledge correlation matrix (Re-HKCM) scheme by embedding inter-class hierarchical knowledge into a data-driven statistical correlation matrix (SCM) which effectively guides the information sharing of nodes in graphical convolutional neural networks and avoids over-smoothing issues. The Re-HKCM is derived from the SCM through a series of mathematical transformations. Extensive experiments are performed on four real-world datasets from different industrial domains (three cavitation datasets from SAMSON AG and one existing publicly) for FID, all showing superior results and outperform recent state-of-the-art FID methods.
* 12 pages
GRU-TV: Time- and velocity-aware GRU for patient representation on multivariate clinical time-series data
May 04, 2022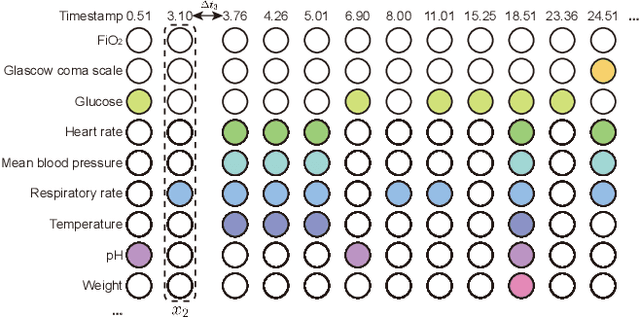
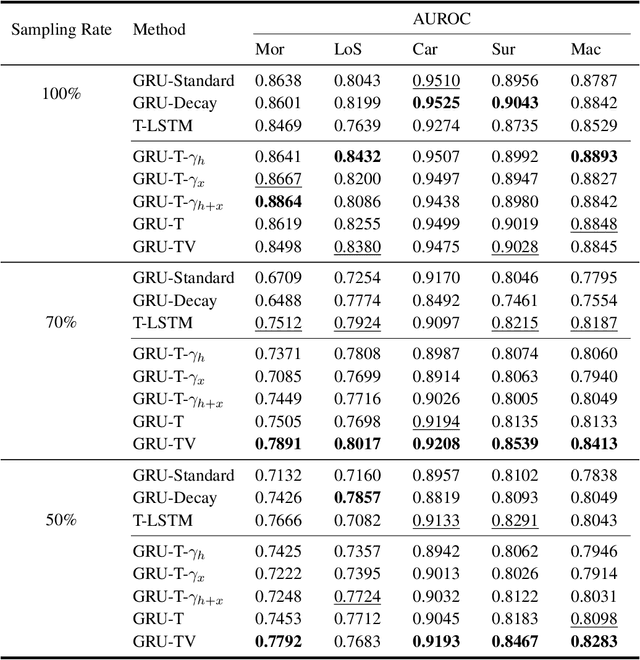
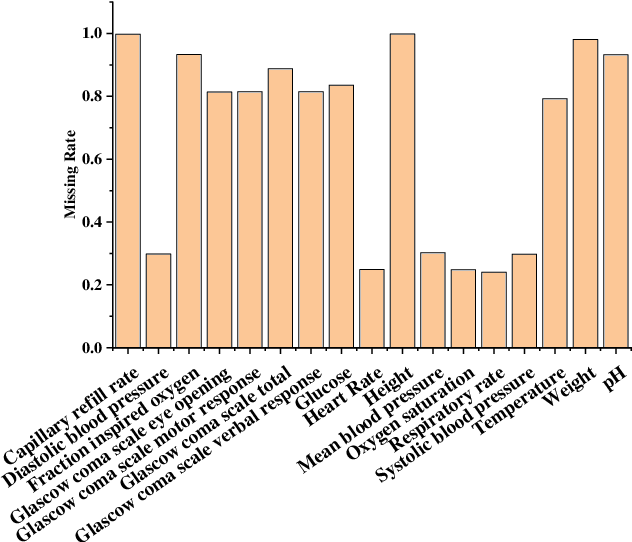
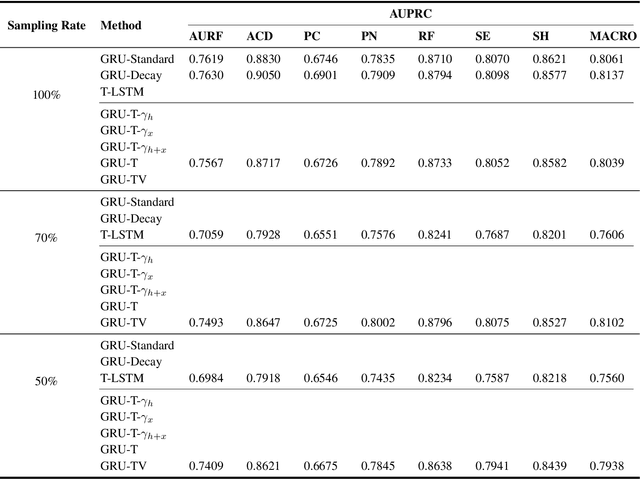
Electronic health records (EHRs) provide a rich repository to track a patient's health status. EHRs seek to fully document the patient's physiological status, and include data that is is high dimensional, heterogeneous, and multimodal. The significant differences in the sampling frequency of clinical variables can result in high missing rates and uneven time intervals between adjacent records in the multivariate clinical time-series data extracted from EHRs. Current studies using clinical time-series data for patient characterization view the patient's physiological status as a discrete process described by sporadically collected values, while the dynamics in patient's physiological status are time-continuous. In addition, recurrent neural networks (RNNs) models widely used for patient representation learning lack the perception of time intervals and velocity, which limits the ability of the model to represent the physiological status of the patient. In this paper, we propose an improved gated recurrent unit (GRU), namely time- and velocity-aware GRU (GRU-TV), for patient representation learning of clinical multivariate time-series data in a time-continuous manner. In proposed GRU-TV, the neural ordinary differential equations (ODEs) and velocity perception mechanism are used to perceive the time interval between records in the time-series data and changing rate of the patient's physiological status, respectively. Experimental results on two real-world clinical EHR datasets(PhysioNet2012, MIMIC-III) show that GRU-TV achieve state-of-the-art performance in computer aided diagnosis (CAD) tasks, and is more advantageous in processing sampled data.
Adaptively Lighting up Facial Expression Crucial Regions via Local Non-Local Joint Network
Mar 26, 2022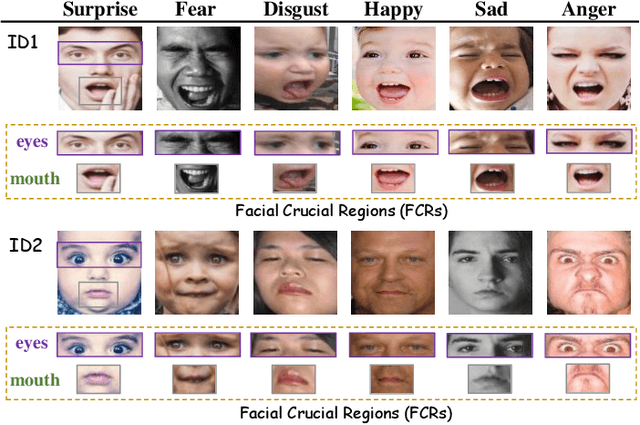
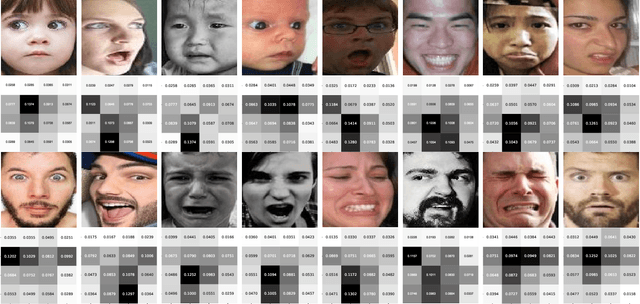
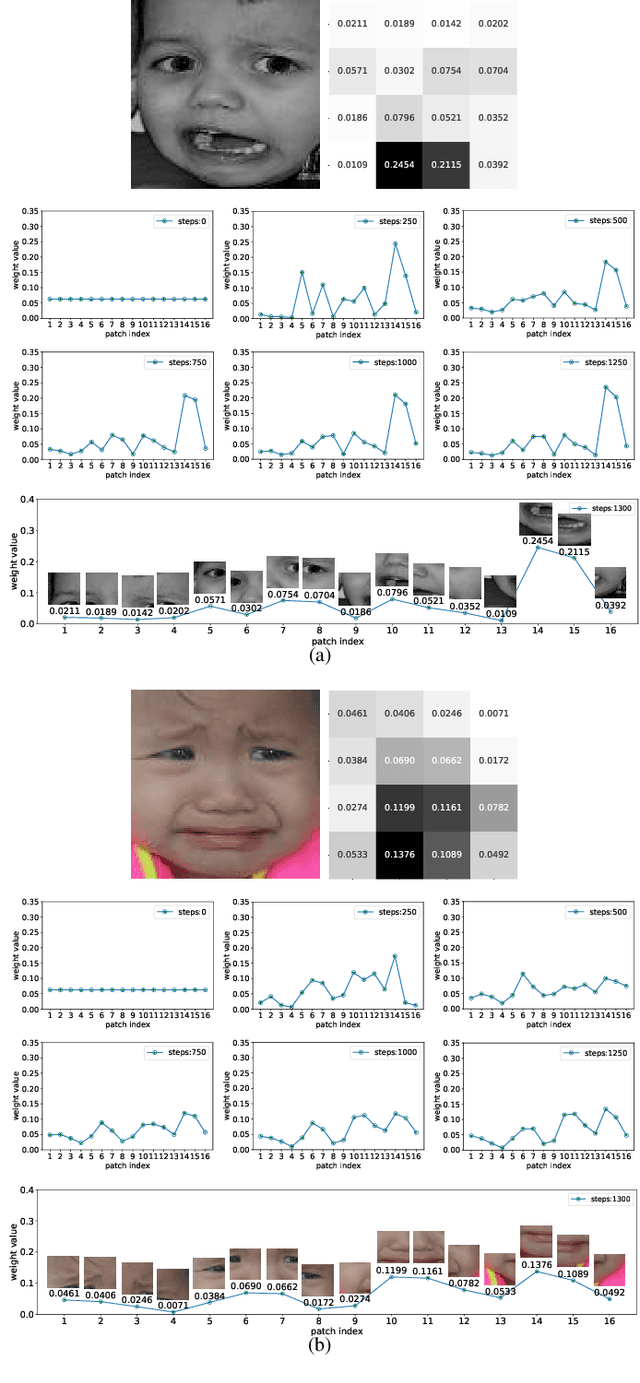
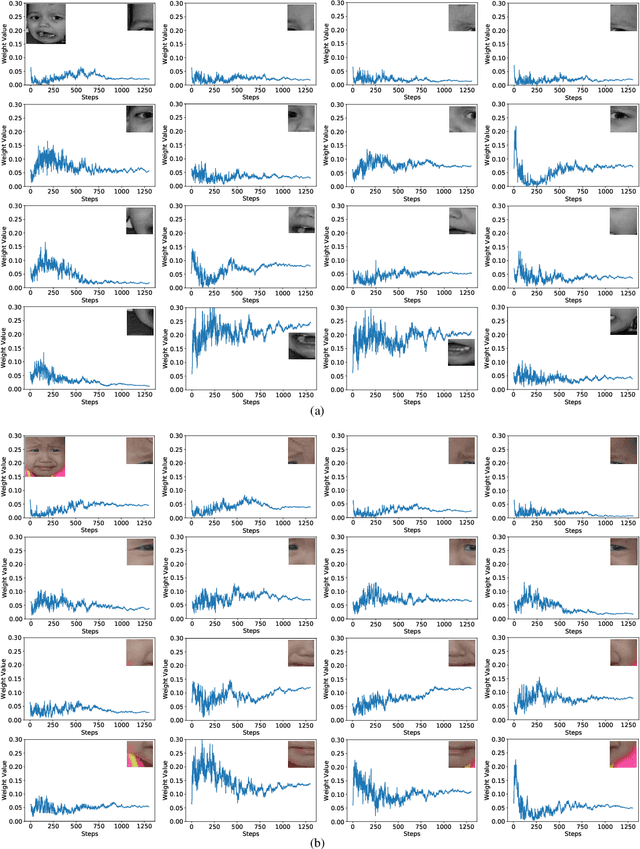
Facial expression recognition (FER) is still one challenging research due to the small inter-class discrepancy in the facial expression data. In view of the significance of facial crucial regions for FER, many existing researches utilize the prior information from some annotated crucial points to improve the performance of FER. However, it is complicated and time-consuming to manually annotate facial crucial points, especially for vast wild expression images. Based on this, a local non-local joint network is proposed to adaptively light up the facial crucial regions in feature learning of FER in this paper. In the proposed method, two parts are constructed based on facial local and non-local information respectively, where an ensemble of multiple local networks are proposed to extract local features corresponding to multiple facial local regions and a non-local attention network is addressed to explore the significance of each local region. Especially, the attention weights obtained by the non-local network is fed into the local part to achieve the interactive feedback between the facial global and local information. Interestingly, the non-local weights corresponding to local regions are gradually updated and higher weights are given to more crucial regions. Moreover, U-Net is employed to extract the integrated features of deep semantic information and low hierarchical detail information of expression images. Finally, experimental results illustrate that the proposed method achieves more competitive performance compared with several state-of-the art methods on five benchmark datasets. Noticeably, the analyses of the non-local weights corresponding to local regions demonstrate that the proposed method can automatically enhance some crucial regions in the process of feature learning without any facial landmark information.
SMTNet: Hierarchical cavitation intensity recognition based on sub-main transfer network
Mar 23, 2022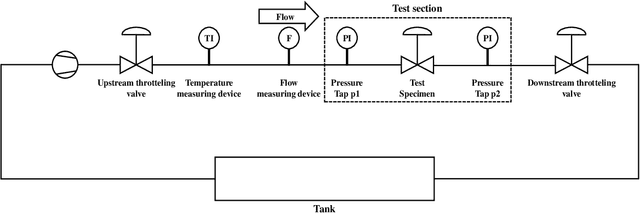

With the rapid development of smart manufacturing, data-driven machinery health management has been of growing attention. In situations where some classes are more difficult to be distinguished compared to others and where classes might be organised in a hierarchy of categories, current DL methods can not work well. In this study, a novel hierarchical cavitation intensity recognition framework using Sub-Main Transfer Network, termed SMTNet, is proposed to classify acoustic signals of valve cavitation. SMTNet model outputs multiple predictions ordered from coarse to fine along a network corresponding to a hierarchy of target cavitation states. Firstly, a data augmentation method based on Sliding Window with Fast Fourier Transform (Swin-FFT) is developed to solve few-shot problem. Secondly, a 1-D double hierarchical residual block (1-D DHRB) is presented to capture sensitive features of the frequency domain valve acoustic signals. Thirdly, hierarchical multi-label tree is proposed to assist the embedding of the semantic structure of target cavitation states into SMTNet. Fourthly, experience filtering mechanism is proposed to fully learn a prior knowledge of cavitation detection model. Finally, SMTNet has been evaluated on two cavitation datasets without noise (Dataset 1 and Dataset 2), and one cavitation dataset with real noise (Dataset 3) provided by SAMSON AG (Frankfurt). The prediction accurcies of SMTNet for cavitation intensity recognition are as high as 95.32%, 97.16% and 100%, respectively. At the same time, the testing accuracies of SMTNet for cavitation detection are as high as 97.02%, 97.64% and 100%. In addition, SMTNet has also been tested for different frequencies of samples and has achieved excellent results of the highest frequency of samples of mobile phones.
A multi-task learning for cavitation detection and cavitation intensity recognition of valve acoustic signals
Mar 01, 2022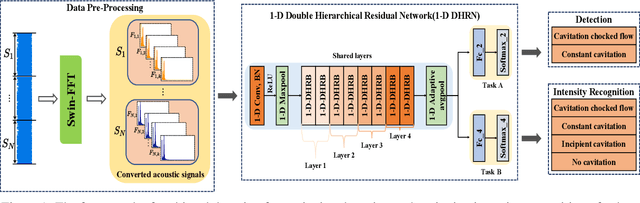

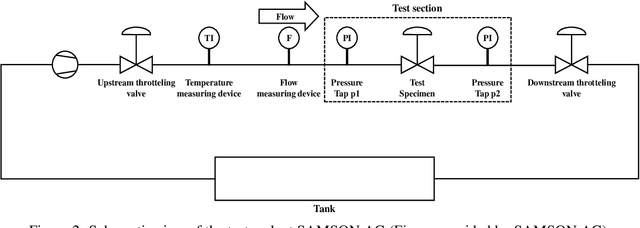

With the rapid development of smart manufacturing, data-driven machinery health management has received a growing attention. As one of the most popular methods in machinery health management, deep learning (DL) has achieved remarkable successes. However, due to the issues of limited samples and poor separability of different cavitation states of acoustic signals, which greatly hinder the eventual performance of DL modes for cavitation intensity recognition and cavitation detection. In this work, a novel multi-task learning framework for simultaneous cavitation detection and cavitation intensity recognition framework using 1-D double hierarchical residual networks (1-D DHRN) is proposed for analyzing valves acoustic signals. Firstly, a data augmentation method based on sliding window with fast Fourier transform (Swin-FFT) is developed to alleviate the small-sample issue confronted in this study. Secondly, a 1-D double hierarchical residual block (1-D DHRB) is constructed to capture sensitive features from the frequency domain acoustic signals of valve. Then, a new structure of 1-D DHRN is proposed. Finally, the devised 1-D DHRN is evaluated on two datasets of valve acoustic signals without noise (Dataset 1 and Dataset 2) and one dataset of valve acoustic signals with realistic surrounding noise (Dataset 3) provided by SAMSON AG (Frankfurt). Our method has achieved state-of-the-art results. The prediction accurcies of 1-D DHRN for cavitation intensitys recognition are as high as 93.75%, 94.31% and 100%, which indicates that 1-D DHRN outperforms other DL models and conventional methods. At the same time, the testing accuracies of 1-D DHRN for cavitation detection are as high as 97.02%, 97.64% and 100%. In addition, 1-D DHRN has also been tested for different frequencies of samples and shows excellent results for frequency of samples that mobile phones can accommodate.
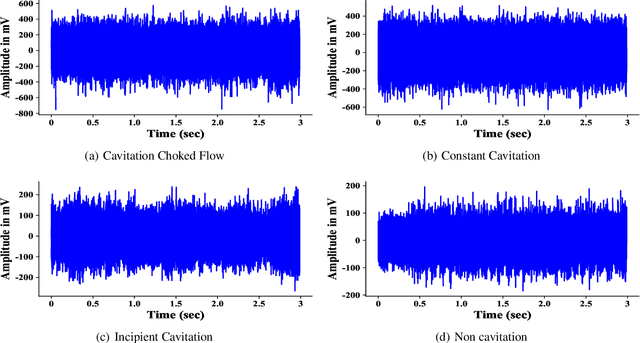
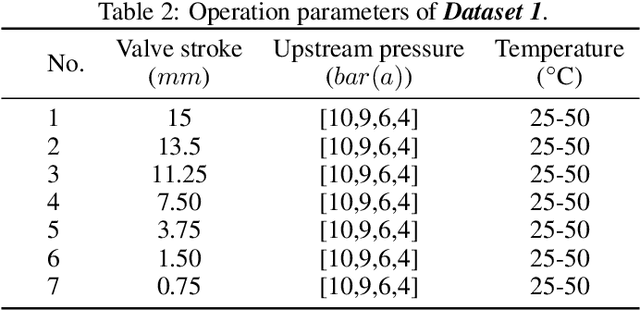
An acoustic signal cavitation detection framework based on XGBoost with adaptive selection feature engineering
Mar 01, 2022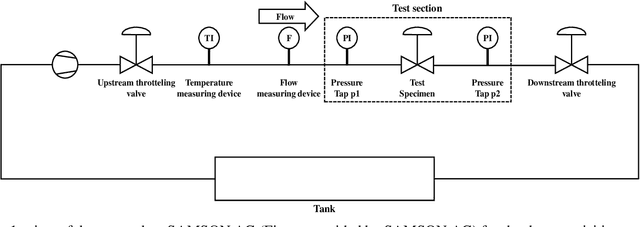
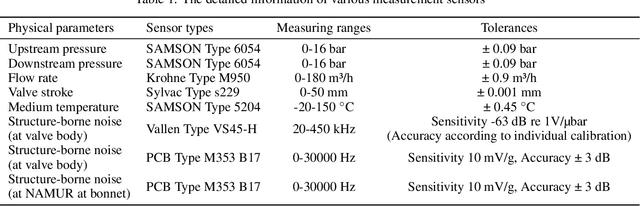
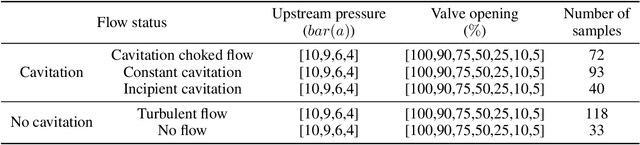
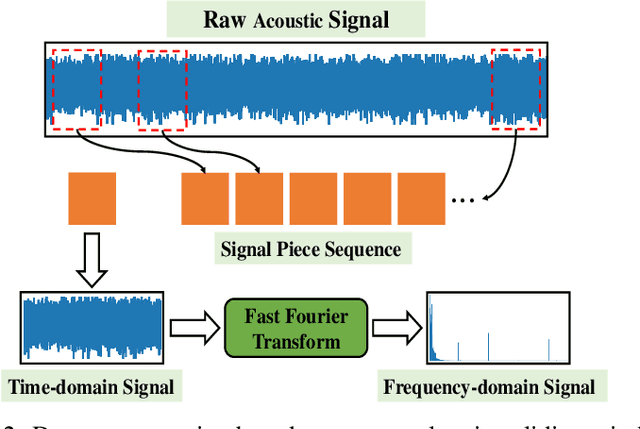
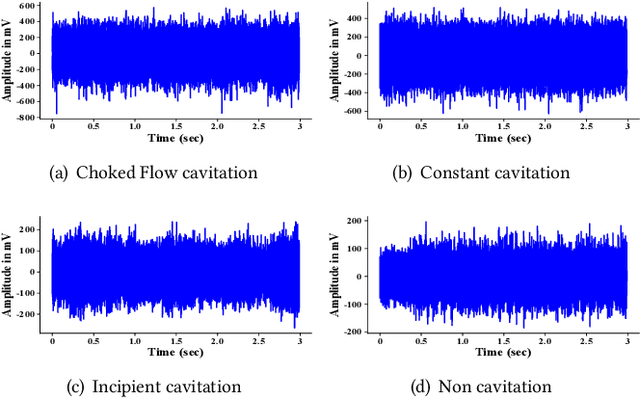
Valves are widely used in industrial and domestic pipeline systems. However, during their operation, they may suffer from the occurrence of the cavitation, which can cause loud noise, vibration and damage to the internal components of the valve. Therefore, monitoring the flow status inside valves is significantly beneficial to prevent the additional cost induced by cavitation. In this paper, a novel acoustic signal cavitation detection framework--based on XGBoost with adaptive selection feature engineering--is proposed. Firstly, a data augmentation method with non-overlapping sliding window (NOSW) is developed to solve small-sample problem involved in this study. Then, the each segmented piece of time-domain acoustic signal is transformed by fast Fourier transform (FFT) and its statistical features are extracted to be the input to the adaptive selection feature engineering (ASFE) procedure, where the adaptive feature aggregation and feature crosses are performed. Finally, with the selected features the XGBoost algorithm is trained for cavitation detection and tested on valve acoustic signal data provided by Samson AG (Frankfurt). Our method has achieved state-of-the-art results. The prediction performance on the binary classification (cavitation and no-cavitation) and the four-class classification (cavitation choked flow, constant cavitation, incipient cavitation and no-cavitation) are satisfactory and outperform the traditional XGBoost by 4.67% and 11.11% increase of the accuracy.
Regional-Local Adversarially Learned One-Class Classifier Anomalous Sound Detection in Global Long-Term Space
Feb 26, 2022

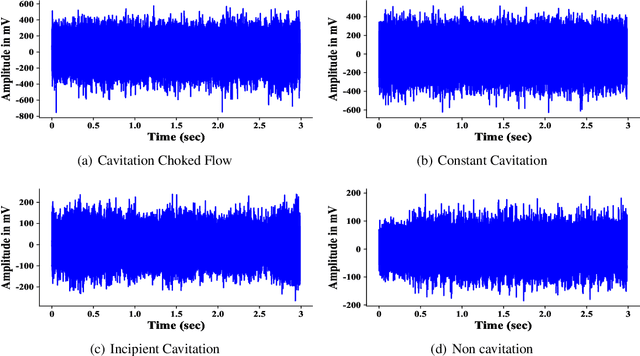

Anomalous sound detection (ASD) is one of the most significant tasks of mechanical equipment monitoring and maintaining in complex industrial systems. In practice, it is vital to precisely identify abnormal status of the working mechanical system, which can further facilitate the failure troubleshooting. In this paper, we propose a multi-pattern adversarial learning one-class classification framework, which allows us to use both the generator and the discriminator of an adversarial model for efficient ASD. The core idea is learning to reconstruct the normal patterns of acoustic data through two different patterns of auto-encoding generators, which succeeds in extending the fundamental role of a discriminator from identifying real and fake data to distinguishing between regional and local pattern reconstructions. Furthermore, we present a global filter layer for long-term interactions in the frequency domain space, which directly learns from the original data without introducing any human priors. Extensive experiments performed on four real-world datasets from different industrial domains (three cavitation datasets provided by SAMSON AG, and one existing publicly) for anomaly detection show superior results, and outperform recent state-of-the-art ASD methods.
Label Distribution Amendment with Emotional Semantic Correlations for Facial Expression Recognition
Jul 23, 2021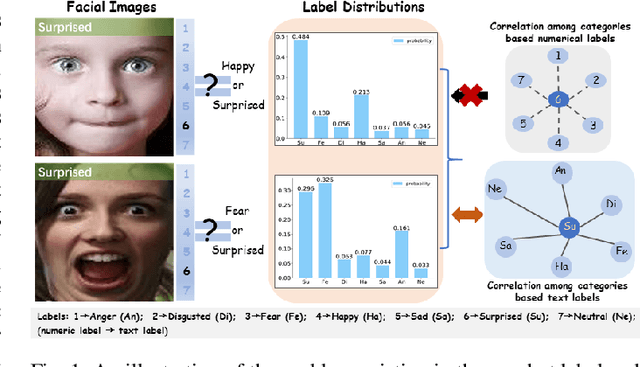
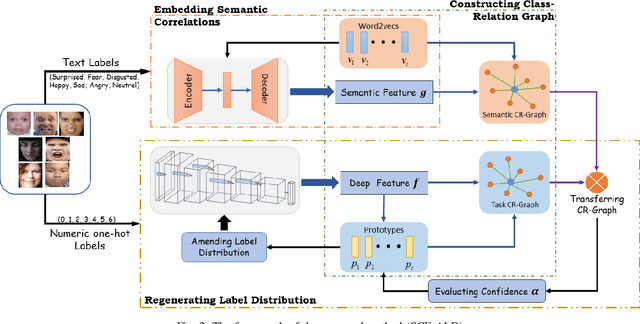
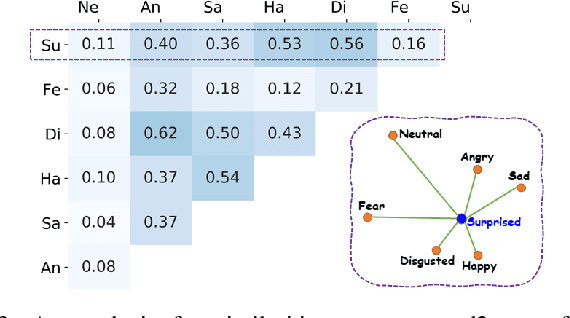
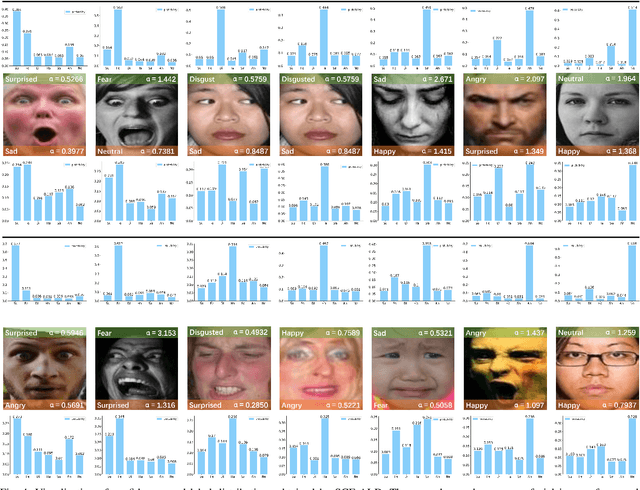
By utilizing label distribution learning, a probability distribution is assigned for a facial image to express a compound emotion, which effectively improves the problem of label uncertainties and noises occurred in one-hot labels. In practice, it is observed that correlations among emotions are inherently different, such as surprised and happy emotions are more possibly synchronized than surprised and neutral. It indicates the correlation may be crucial for obtaining a reliable label distribution. Based on this, we propose a new method that amends the label distribution of each facial image by leveraging correlations among expressions in the semantic space. Inspired by inherently diverse correlations among word2vecs, the topological information among facial expressions is firstly explored in the semantic space, and each image is embedded into the semantic space. Specially, a class-relation graph is constructed to transfer the semantic correlation among expressions into the task space. By comparing semantic and task class-relation graphs of each image, the confidence of its label distribution is evaluated. Based on the confidence, the label distribution is amended by enhancing samples with higher confidence and weakening samples with lower confidence. Experimental results demonstrate the proposed method is more effective than compared state-of-the-art methods.
Complex Scene Classification of PolSAR Imagery based on a Self-paced Learning Approach
Mar 18, 2019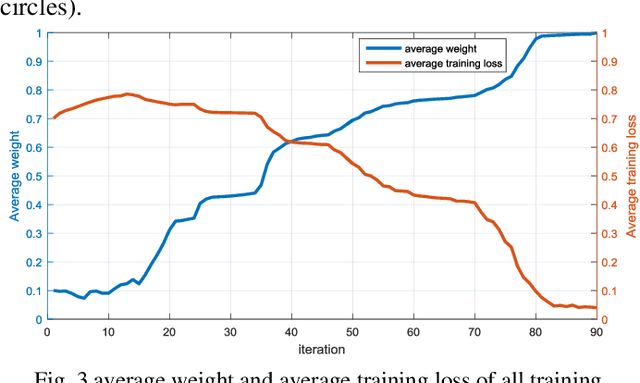
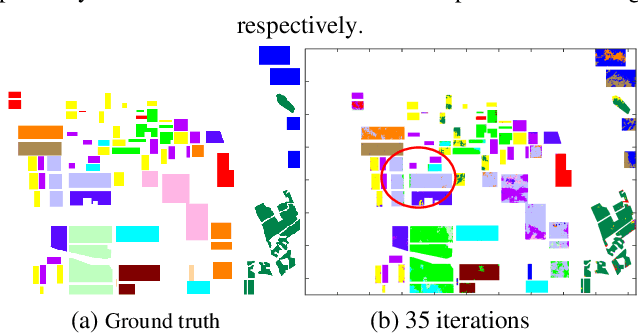
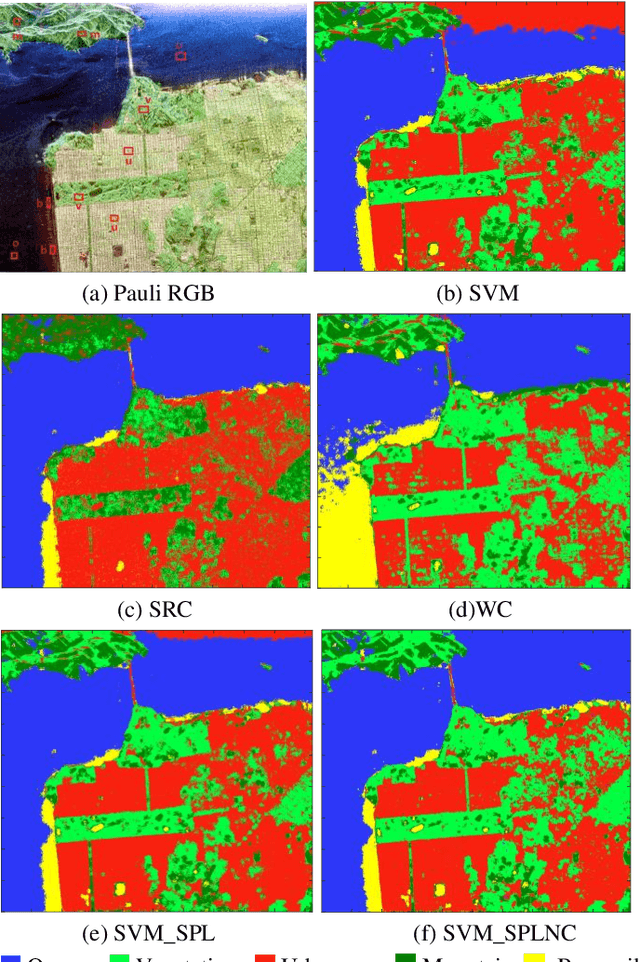
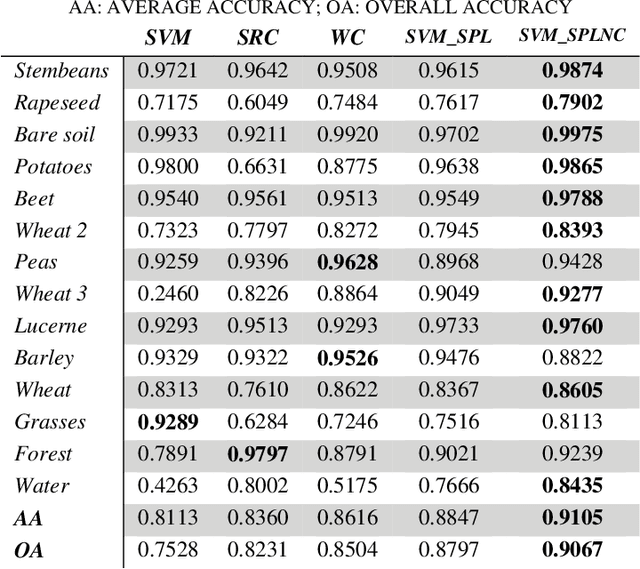
Existing polarimetric synthetic aperture radar (PolSAR) image classification methods cannot achieve satisfactory performance on complex scenes characterized by several types of land cover with significant levels of noise or similar scattering properties across land cover types. Hence, we propose a supervised classification method aimed at constructing a classifier based on self-paced learning (SPL). SPL has been demonstrated to be effective at dealing with complex data while providing classifier. In this paper, a novel Support Vector Machine (SVM) algorithm based on SPL with neighborhood constraints (SVM_SPLNC) is proposed. The proposed method leverages the easiest samples first to obtain an initial parameter vector. Then, more complex samples are gradually incorporated to update the parameter vector iteratively. Moreover, neighborhood constraints are introduced during the training process to further improve performance. Experimental results on three real PolSAR images show that the proposed method performs well on complex scenes.