 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA multi-source data power load forecasting method using attention mechanism-based parallel cnn-gru
Sep 26, 2024



Accurate power load forecasting is crucial for improving energy efficiency and ensuring power supply quality. Considering the power load forecasting problem involves not only dynamic factors like historical load variations but also static factors such as climate conditions that remain constant over specific periods. From the model-agnostic perspective, this paper proposes a parallel structure network to extract important information from both dynamic and static data. Firstly, based on complexity learning theory, it is demonstrated that models integrated through parallel structures exhibit superior generalization abilities compared to individual base learners. Additionally, the higher the independence between base learners, the stronger the generalization ability of the parallel structure model. This suggests that the structure of machine learning models inherently contains significant information. Building on this theoretical foundation, a parallel convolutional neural network (CNN)-gate recurrent unit (GRU) attention model (PCGA) is employed to address the power load forecasting issue, aiming to effectively integrate the influences of dynamic and static features. The CNN module is responsible for capturing spatial characteristics from static data, while the GRU module captures long-term dependencies in dynamic time series data. The attention layer is designed to focus on key information from the spatial-temporal features extracted by the parallel CNN-GRU. To substantiate the advantages of the parallel structure model in extracting and integrating multi-source information, a series of experiments are conducted.
Domain Adaptation for Industrial Time-series Forecasting via Counterfactual Inference
Jul 19, 2024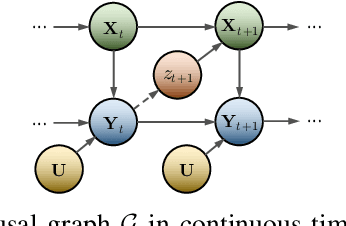
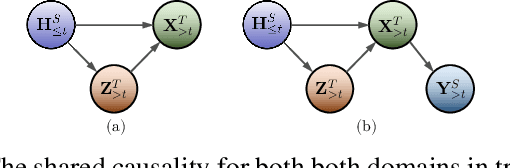
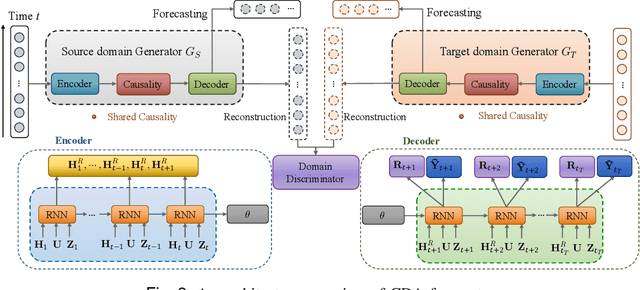
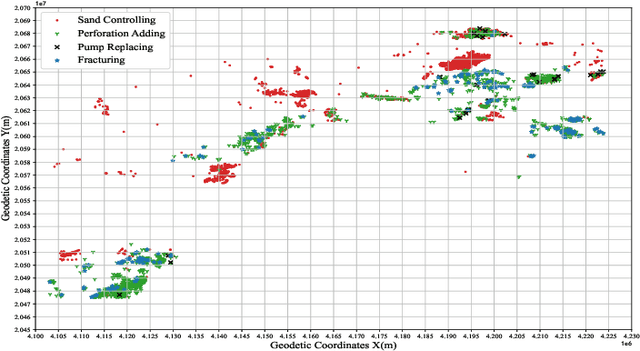
Industrial time-series, as a structural data responds to production process information, can be utilized to perform data-driven decision-making for effective monitoring of industrial production process. However, there are some challenges for time-series forecasting in industry, e.g., predicting few-shot caused by data shortage, and decision-confusing caused by unknown treatment policy. To cope with the problems, we propose a novel causal domain adaptation framework, Causal Domain Adaptation (CDA) forecaster to improve the performance on the interested domain with limited data (target). Firstly, we analyze the causality existing along with treatments, and thus ensure the shared causality over time. Subsequently, we propose an answer-based attention mechanism to achieve domain-invariant representation by the shared causality in both domains. Then, a novel domain-adaptation is built to model treatments and outcomes jointly training on source and target domain. The main insights are that our designed answer-based attention mechanism allows the target domain to leverage the existed causality in source time-series even with different treatments, and our forecaster can predict the counterfactual outcome of industrial time-series, meaning a guidance in production process. Compared with commonly baselines, our method on real-world and synthetic oilfield datasets demonstrates the effectiveness in across-domain prediction and the practicality in guiding production process
Domain adaption and physical constrains transfer learning for shale gas production
Dec 18, 2023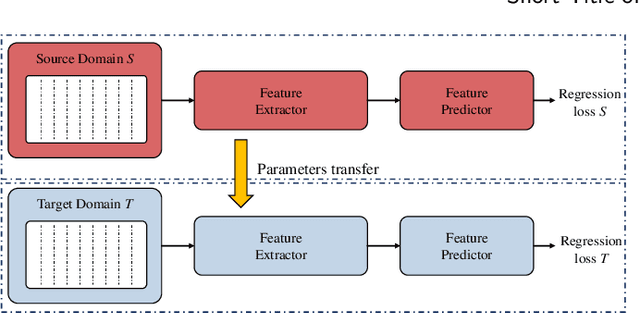
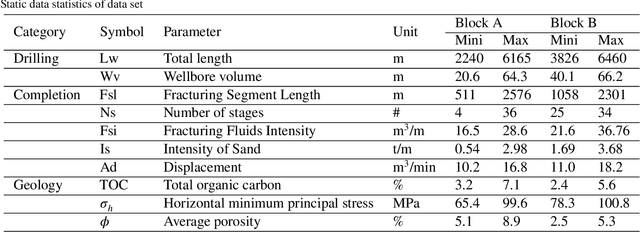
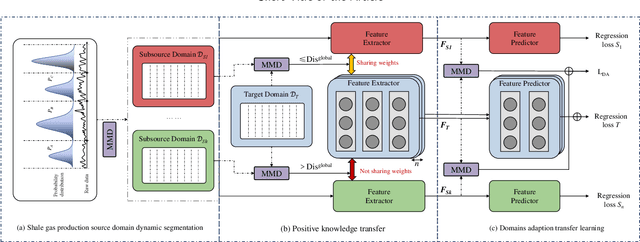
Effective prediction of shale gas production is crucial for strategic reservoir development. However, in new shale gas blocks, two main challenges are encountered: (1) the occurrence of negative transfer due to insufficient data, and (2) the limited interpretability of deep learning (DL) models. To tackle these problems, we propose a novel transfer learning methodology that utilizes domain adaptation and physical constraints. This methodology effectively employs historical data from the source domain to reduce negative transfer from the data distribution perspective, while also using physical constraints to build a robust and reliable prediction model that integrates various types of data. The methodology starts by dividing the production data from the source domain into multiple subdomains, thereby enhancing data diversity. It then uses Maximum Mean Discrepancy (MMD) and global average distance measures to decide on the feasibility of transfer. Through domain adaptation, we integrate all transferable knowledge, resulting in a more comprehensive target model. Lastly, by incorporating drilling, completion, and geological data as physical constraints, we develop a hybrid model. This model, a combination of a multi-layer perceptron (MLP) and a Transformer (Transformer-MLP), is designed to maximize interpretability. Experimental validation in China's southwestern region confirms the method's effectiveness.
Ensemble Interpretation: A Unified Method for Interpretable Machine Learning
Dec 11, 2023To address the issues of stability and fidelity in interpretable learning, a novel interpretable methodology, ensemble interpretation, is presented in this paper which integrates multi-perspective explanation of various interpretation methods. On one hand, we define a unified paradigm to describe the common mechanism of different interpretation methods, and then integrate the multiple interpretation results to achieve more stable explanation. On the other hand, a supervised evaluation method based on prior knowledge is proposed to evaluate the explaining performance of an interpretation method. The experiment results show that the ensemble interpretation is more stable and more consistent with human experience and cognition. As an application, we use the ensemble interpretation for feature selection, and then the generalization performance of the corresponding learning model is significantly improved.
Has China caught up to the US in AI research? An exploration of mimetic isomorphism as a model for late industrializers
Jul 11, 2023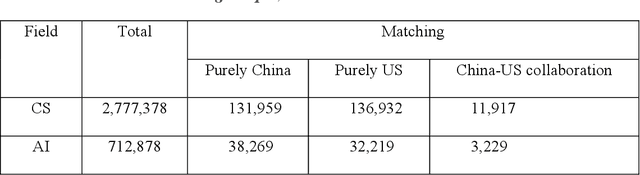

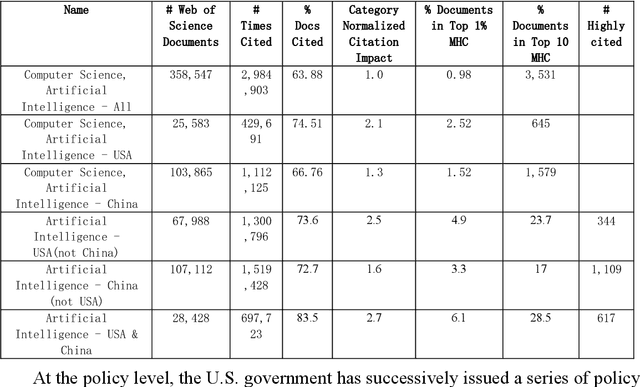

Artificial Intelligence (AI), a cornerstone of 21st-century technology, has seen remarkable growth in China. In this paper, we examine China's AI development process, demonstrating that it is characterized by rapid learning and differentiation, surpassing the export-oriented growth propelled by Foreign Direct Investment seen in earlier Asian industrializers. Our data indicates that China currently leads the USA in the volume of AI-related research papers. However, when we delve into the quality of these papers based on specific metrics, the USA retains a slight edge. Nevertheless, the pace and scale of China's AI development remain noteworthy. We attribute China's accelerated AI progress to several factors, including global trends favoring open access to algorithms and research papers, contributions from China's broad diaspora and returnees, and relatively lax data protection policies. In the vein of our research, we have developed a novel measure for gauging China's imitation of US research. Our analysis shows that by 2018, the time lag between China and the USA in addressing AI research topics had evaporated. This finding suggests that China has effectively bridged a significant knowledge gap and could potentially be setting out on an independent research trajectory. While this study compares China and the USA exclusively, it's important to note that research collaborations between these two nations have resulted in more highly cited work than those produced by either country independently. This underscores the power of international cooperation in driving scientific progress in AI.
Prediction of single well production rate in water-flooding oil fields driven by the fusion of static, temporal and spatial information
Feb 22, 2023It is very difficult to forecast the production rate of oil wells as the output of a single well is sensitive to various uncertain factors, which implicitly or explicitly show the influence of the static, temporal and spatial properties on the oil well production. In this study, a novel machine learning model is constructed to fuse the static geological information, dynamic well production history, and spatial information of the adjacent water injection wells. There are 3 basic modules in this stacking model, which are regarded as the encoders to extract the features from different types of data. One is Multi-Layer Perceptron, which is to analyze the static geological properties of the reservoir that might influence the well production rate. The other two are both LSTMs, which have the input in the form of two matrices rather than vectors, standing for the temporal and the spatial information of the target well. The difference of the two modules is that in the spatial information processing module we take into consideration the time delay of water flooding response, from the injection well to the target well. In addition, we use Symbolic Transfer Entropy to prove the superiorities of the stacking model from the perspective of Causality Discovery. It is proved theoretically and practically that the presented model can make full use of the model structure to integrate the characteristics of the data and the experts' knowledge into the process of machine learning, greatly improving the accuracy and generalization ability of prediction.
Interpretability and causal discovery of the machine learning models to predict the production of CBM wells after hydraulic fracturing
Dec 21, 2022



Machine learning approaches are widely studied in the production prediction of CBM wells after hydraulic fracturing, but merely used in practice due to the low generalization ability and the lack of interpretability. A novel methodology is proposed in this article to discover the latent causality from observed data, which is aimed at finding an indirect way to interpret the machine learning results. Based on the theory of causal discovery, a causal graph is derived with explicit input, output, treatment and confounding variables. Then, SHAP is employed to analyze the influence of the factors on the production capability, which indirectly interprets the machine learning models. The proposed method can capture the underlying nonlinear relationship between the factors and the output, which remedies the limitation of the traditional machine learning routines based on the correlation analysis of factors. The experiment on the data of CBM shows that the detected relationship between the production and the geological/engineering factors by the presented method, is coincident with the actual physical mechanism. Meanwhile, compared with traditional methods, the interpretable machine learning models have better performance in forecasting production capability, averaging 20% improvement in accuracy.