 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeynmanBench: Benchmarking Multimodal LLMs on Diagrammatic Physics Reasoning
Apr 04, 2026Breakthroughs in frontier theory often depend on the combination of concrete diagrammatic notations with rigorous logic. While multimodal large language models (MLLMs) show promise in general scientific tasks, current benchmarks often focus on local information extraction rather than the global structural logic inherent in formal scientific notations. In this work, we introduce FeynmanBench, the first benchmark centered on Feynman diagram tasks. It is designed to evaluate AI's capacity for multistep diagrammatic reasoning, which requires satisfying conservation laws and symmetry constraints, identifying graph topology, converting between diagrammatic and algebraic representations, and constructing scattering amplitudes under specific conventions and gauges. To support large-scale and reproducible evaluation, we developed an automated pipeline producing diverse Feynman diagrams along with verifiable topological annotations and amplitude results. Our database spans the electromagnetic, weak, and strong interactions of the Standard Model, encompasses over 100 distinct types and includes more than 2000 tasks. Experiments on state-of-the-art MLLMs reveal systematic failure modes, including unstable enforcement of physical constraints and violations of global topological conditions, highlighting the need for physics-grounded benchmarks for visual reasoning over scientific notation. FeynmanBench provides a logically rigorous test of whether AI can effectively engage in scientific discovery, particularly within theoretical physics.
SPM-Bench: Benchmarking Large Language Models for Scanning Probe Microscopy
Feb 26, 2026As LLMs achieved breakthroughs in general reasoning, their proficiency in specialized scientific domains reveals pronounced gaps in existing benchmarks due to data contamination, insufficient complexity, and prohibitive human labor costs. Here we present SPM-Bench, an original, PhD-level multimodal benchmark specifically designed for scanning probe microscopy (SPM). We propose a fully automated data synthesis pipeline that ensures both high authority and low-cost. By employing Anchor-Gated Sieve (AGS) technology, we efficiently extract high-value image-text pairs from arXiv and journal papers published between 2023 and 2025. Through a hybrid cloud-local architecture where VLMs return only spatial coordinates "llbox" for local high-fidelity cropping, our pipeline achieves extreme token savings while maintaining high dataset purity. To accurately and objectively evaluate the performance of the LLMs, we introduce the Strict Imperfection Penalty F1 (SIP-F1) score. This metric not only establishes a rigorous capability hierarchy but also, for the first time, quantifies model "personalities" (Conservative, Aggressive, Gambler, or Wise). By correlating these results with model-reported confidence and perceived difficulty, we expose the true reasoning boundaries of current AI in complex physical scenarios. These insights establish SPM-Bench as a generalizable paradigm for automated scientific data synthesis.
HLE-Verified: A Systematic Verification and Structured Revision of Humanity's Last Exam
Feb 17, 2026Humanity's Last Exam (HLE) has become a widely used benchmark for evaluating frontier large language models on challenging, multi-domain questions. However, community-led analyses have raised concerns that HLE contains a non-trivial number of noisy items, which can bias evaluation results and distort cross-model comparisons. To address this challenge, we introduce HLE-Verified, a verified and revised version of HLE with a transparent verification protocol and fine-grained error taxonomy. Our construction follows a two-stage validation-and-repair workflow resulting in a certified benchmark. In Stage I, each item undergoes binary validation of the problem and final answer through domain-expert review and model-based cross-checks, yielding 641 verified items. In Stage II, flawed but fixable items are revised under strict constraints preserving the original evaluation intent, through dual independent expert repairs, model-assisted auditing, and final adjudication, resulting in 1,170 revised-and-certified items. The remaining 689 items are released as a documented uncertain set with explicit uncertainty sources and expertise tags for future refinement. We evaluate seven state-of-the-art language models on HLE and HLE-Verified, observing an average absolute accuracy gain of 7--10 percentage points on HLE-Verified. The improvement is particularly pronounced on items where the original problem statement and/or reference answer is erroneous, with gains of 30--40 percentage points. Our analyses further reveal a strong association between model confidence and the presence of errors in the problem statement or reference answer, supporting the effectiveness of our revisions. Overall, HLE-Verified improves HLE-style evaluations by reducing annotation noise and enabling more faithful measurement of model capabilities. Data is available at: https://github.com/SKYLENAGE-AI/HLE-Verified
Domain adaption and physical constrains transfer learning for shale gas production
Dec 18, 2023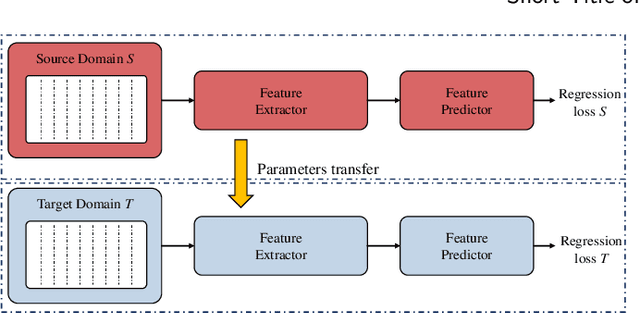
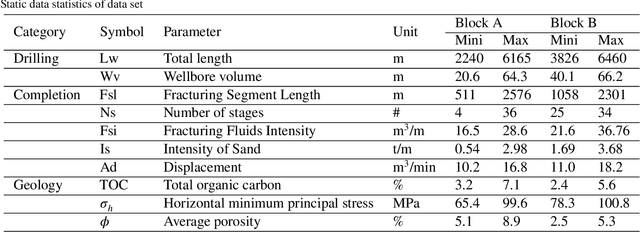
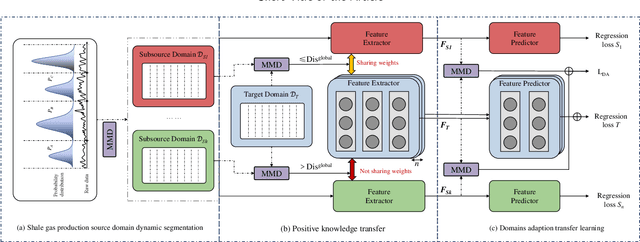
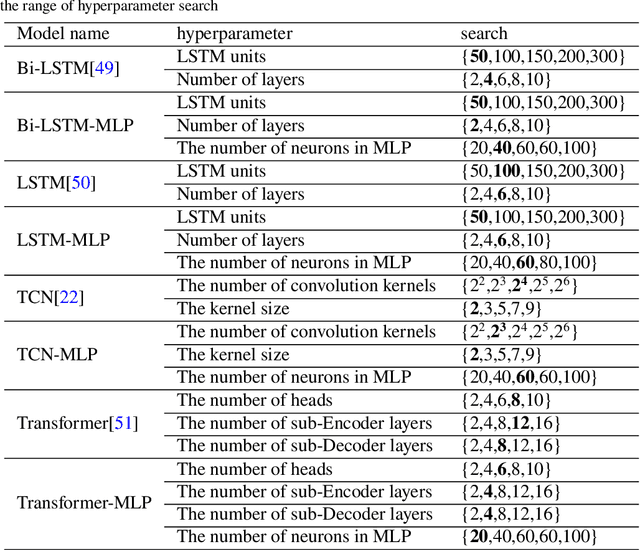
Effective prediction of shale gas production is crucial for strategic reservoir development. However, in new shale gas blocks, two main challenges are encountered: (1) the occurrence of negative transfer due to insufficient data, and (2) the limited interpretability of deep learning (DL) models. To tackle these problems, we propose a novel transfer learning methodology that utilizes domain adaptation and physical constraints. This methodology effectively employs historical data from the source domain to reduce negative transfer from the data distribution perspective, while also using physical constraints to build a robust and reliable prediction model that integrates various types of data. The methodology starts by dividing the production data from the source domain into multiple subdomains, thereby enhancing data diversity. It then uses Maximum Mean Discrepancy (MMD) and global average distance measures to decide on the feasibility of transfer. Through domain adaptation, we integrate all transferable knowledge, resulting in a more comprehensive target model. Lastly, by incorporating drilling, completion, and geological data as physical constraints, we develop a hybrid model. This model, a combination of a multi-layer perceptron (MLP) and a Transformer (Transformer-MLP), is designed to maximize interpretability. Experimental validation in China's southwestern region confirms the method's effectiveness.
Interpretability and causal discovery of the machine learning models to predict the production of CBM wells after hydraulic fracturing
Dec 21, 2022



Machine learning approaches are widely studied in the production prediction of CBM wells after hydraulic fracturing, but merely used in practice due to the low generalization ability and the lack of interpretability. A novel methodology is proposed in this article to discover the latent causality from observed data, which is aimed at finding an indirect way to interpret the machine learning results. Based on the theory of causal discovery, a causal graph is derived with explicit input, output, treatment and confounding variables. Then, SHAP is employed to analyze the influence of the factors on the production capability, which indirectly interprets the machine learning models. The proposed method can capture the underlying nonlinear relationship between the factors and the output, which remedies the limitation of the traditional machine learning routines based on the correlation analysis of factors. The experiment on the data of CBM shows that the detected relationship between the production and the geological/engineering factors by the presented method, is coincident with the actual physical mechanism. Meanwhile, compared with traditional methods, the interpretable machine learning models have better performance in forecasting production capability, averaging 20% improvement in accuracy.
RGB Image Classification with Quantum Convolutional Ansaetze
Jul 23, 2021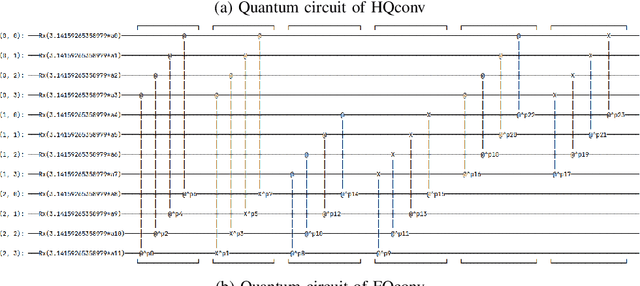
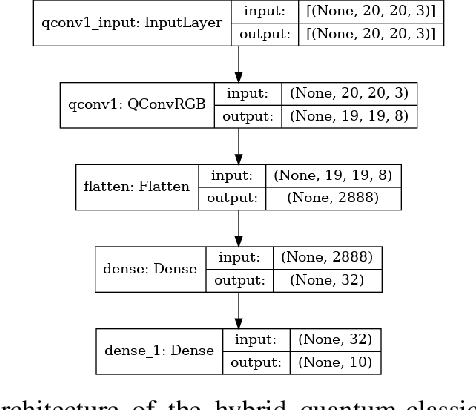
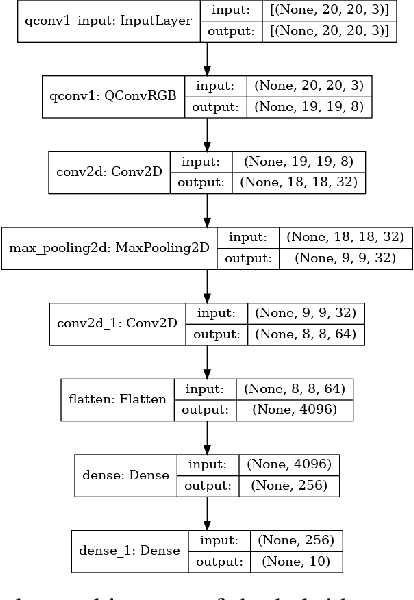
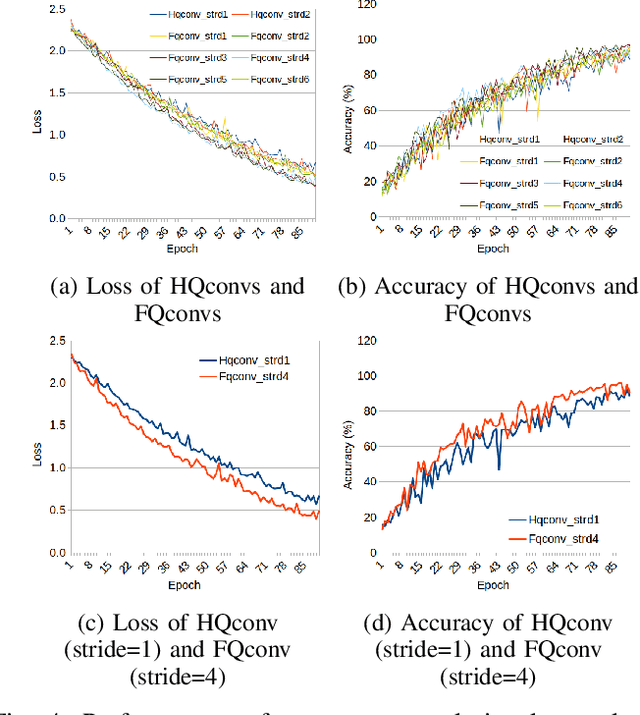
With the rapid growth of qubit numbers and coherence times in quantum hardware technology, implementing shallow neural networks on the so-called Noisy Intermediate-Scale Quantum (NISQ) devices has attracted a lot of interest. Many quantum (convolutional) circuit ansaetze are proposed for grayscale images classification tasks with promising empirical results. However, when applying these ansaetze on RGB images, the intra-channel information that is useful for vision tasks is not extracted effectively. In this paper, we propose two types of quantum circuit ansaetze to simulate convolution operations on RGB images, which differ in the way how inter-channel and intra-channel information are extracted. To the best of our knowledge, this is the first work of a quantum convolutional circuit to deal with RGB images effectively, with a higher test accuracy compared to the purely classical CNNs. We also investigate the relationship between the size of quantum circuit ansatz and the learnability of the hybrid quantum-classical convolutional neural network. Through experiments based on CIFAR-10 and MNIST datasets, we demonstrate that a larger size of the quantum circuit ansatz improves predictive performance in multiclass classification tasks, providing useful insights for near term quantum algorithm developments.
Geodesic Clustering in Deep Generative Models
Sep 13, 2018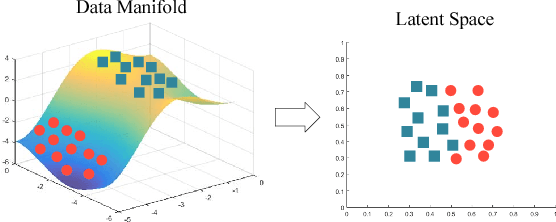
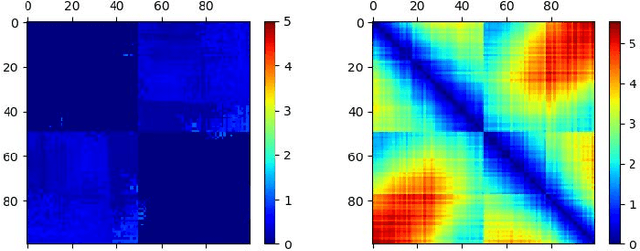
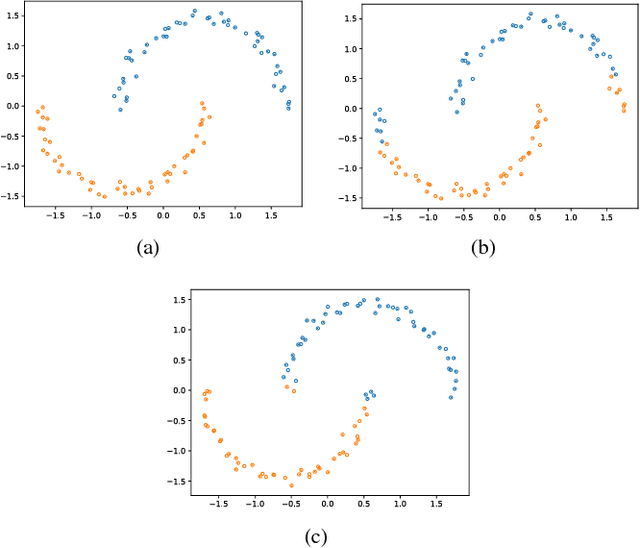
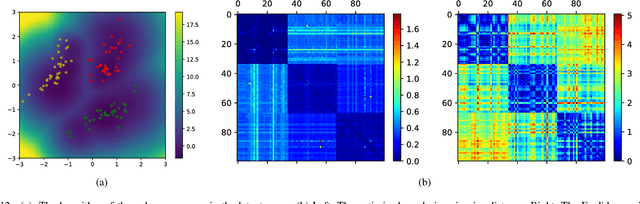
Deep generative models are tremendously successful in learning low-dimensional latent representations that well-describe the data. These representations, however, tend to much distort relationships between points, i.e. pairwise distances tend to not reflect semantic similarities well. This renders unsupervised tasks, such as clustering, difficult when working with the latent representations. We demonstrate that taking the geometry of the generative model into account is sufficient to make simple clustering algorithms work well over latent representations. Leaning on the recent finding that deep generative models constitute stochastically immersed Riemannian manifolds, we propose an efficient algorithm for computing geodesics (shortest paths) and computing distances in the latent space, while taking its distortion into account. We further propose a new architecture for modeling uncertainty in variational autoencoders, which is essential for understanding the geometry of deep generative models. Experiments show that the geodesic distance is very likely to reflect the internal structure of the data.