 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Trustworthy Self-Attention: Enabling the Network to Focus Only on the Most Relevant References
Mar 01, 2024The prediction of optical flow for occluded points is still a difficult problem that has not yet been solved. Recent methods use self-attention to find relevant non-occluded points as references for estimating the optical flow of occluded points based on the assumption of self-similarity. However, they rely on visual features of a single image and weak constraints, which are not sufficient to constrain the trained network to focus on erroneous and weakly relevant reference points. We make full use of online occlusion recognition information to construct occlusion extended visual features and two strong constraints, allowing the network to learn to focus only on the most relevant references without requiring occlusion ground truth to participate in the training of the network. Our method adds very few network parameters to the original framework, making it very lightweight. Extensive experiments show that our model has the greatest cross-dataset generalization. Our method achieves much greater error reduction, 18.6%, 16.2%, and 20.1% for all points, non-occluded points, and occluded points respectively from the state-of-the-art GMA-base method, MATCHFlow(GMA), on Sintel Albedo pass. Furthermore, our model achieves state-of-the-art performance on the Sintel bench-marks, ranking \#1 among all published methods on Sintel clean pass. The code will be open-source.
YOIO: You Only Iterate Once by mining and fusing multiple necessary global information in the optical flow estimation
Jan 11, 2024Occlusions pose a significant challenge to optical flow algorithms that even rely on global evidences. We consider an occluded point to be one that is imaged in the reference frame but not in the next. Estimating the motion of these points is extremely difficult, particularly in the two-frame setting. Previous work only used the current frame as the only input, which could not guarantee providing correct global reference information for occluded points, and had problems such as long calculation time and poor accuracy in predicting optical flow at occluded points. To enable both high accuracy and efficiency, We fully mine and utilize the spatiotemporal information provided by the frame pair, design a loopback judgment algorithm to ensure that correct global reference information is obtained, mine multiple necessary global information, and design an efficient refinement module that fuses these global information. Specifically, we propose a YOIO framework, which consists of three main components: an initial flow estimator, a multiple global information extraction module, and a unified refinement module. We demonstrate that optical flow estimates in the occluded regions can be significantly improved in only one iteration without damaging the performance in non-occluded regions. Compared with GMA, the optical flow prediction accuracy of this method in the occluded area is improved by more than 10%, and the occ_out area exceeds 15%, while the calculation time is 27% shorter. This approach, running up to 18.9fps with 436*1024 image resolution, obtains new state-of-the-art results on the challenging Sintel dataset among all published and unpublished approaches that can run in real-time, suggesting a new paradigm for accurate and efficient optical flow estimation.
RGB Image Classification with Quantum Convolutional Ansaetze
Jul 23, 2021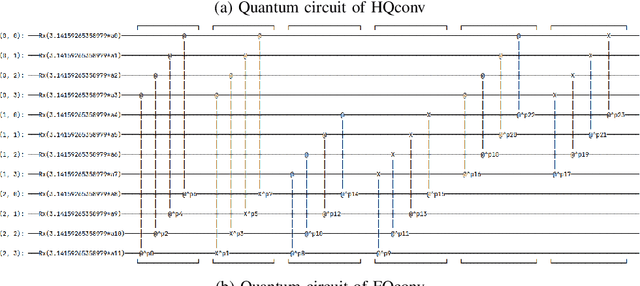
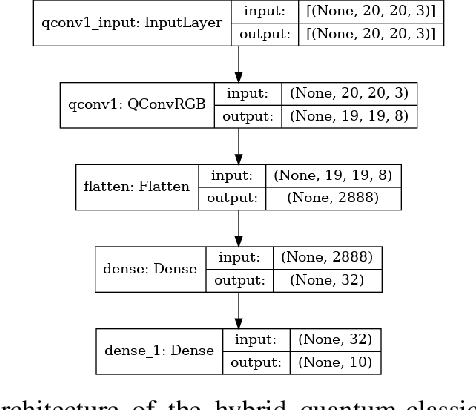
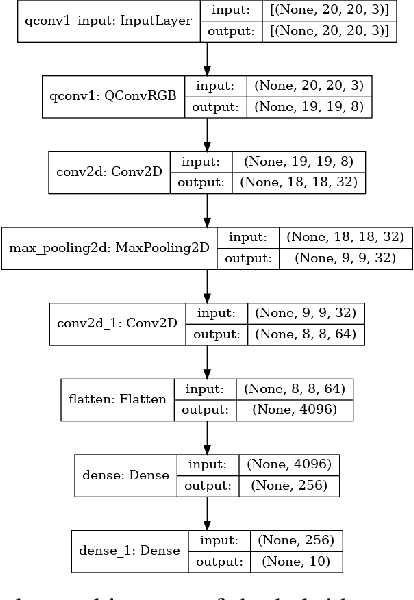
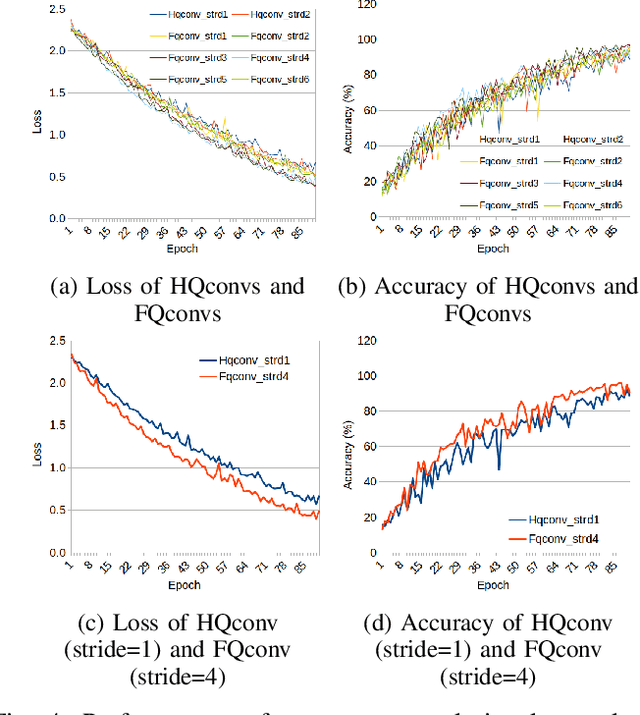
With the rapid growth of qubit numbers and coherence times in quantum hardware technology, implementing shallow neural networks on the so-called Noisy Intermediate-Scale Quantum (NISQ) devices has attracted a lot of interest. Many quantum (convolutional) circuit ansaetze are proposed for grayscale images classification tasks with promising empirical results. However, when applying these ansaetze on RGB images, the intra-channel information that is useful for vision tasks is not extracted effectively. In this paper, we propose two types of quantum circuit ansaetze to simulate convolution operations on RGB images, which differ in the way how inter-channel and intra-channel information are extracted. To the best of our knowledge, this is the first work of a quantum convolutional circuit to deal with RGB images effectively, with a higher test accuracy compared to the purely classical CNNs. We also investigate the relationship between the size of quantum circuit ansatz and the learnability of the hybrid quantum-classical convolutional neural network. Through experiments based on CIFAR-10 and MNIST datasets, we demonstrate that a larger size of the quantum circuit ansatz improves predictive performance in multiclass classification tasks, providing useful insights for near term quantum algorithm developments.
Deep Reinforcement Learning with Surrogate Agent-Environment Interface
Nov 10, 2017


In this paper, we propose surrogate agent-environment interface (SAEI) in reinforcement learning. We also state that learning based on probability surrogate agent-environment interface provides optimal policy of task agent-environment interface. We introduce surrogate probability action and develop the probability surrogate action deterministic policy gradient (PSADPG) algorithm based on SAEI. This algorithm enables continuous control of discrete action. The experiments show PSADPG achieves the performance of DQN in certain tasks with the stochastic optimal policy nature in the initial training stage.