 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Bias Alignment for High-Fidelity Diffusion Inversion in Real-World Image Reconstruction and Manipulation
Mar 25, 2026Recent research has shown that text-to-image diffusion models are capable of generating high-quality images guided by text prompts. But can they be used to generate or approximate real-world images from the seed noise? This is known as the diffusion inversion problem, which serves as a fundamental building block for bridging diffusion models and real-world scenarios. However, existing diffusion inversion methods often suffer from low reconstruction quality or weak robustness. Two major challenges need to be carefully addressed: (1) the misalignment between the inversion and generation trajectories during the diffusion process, and (2) the mismatch between the diffusion inversion process and the VQ autoencoder (VQAE) reconstruction. To address these challenges, we introduce a latent bias vector at each inversion step, which is learned to reduce the misalignment between inversion and generation trajectories. We refer to this strategy as Latent Bias Optimization (LBO). Furthermore, we perform an approximate joint optimization of the diffusion inversion and VQAE reconstruction processes by learning to adjust the image latent representation, which serves as the connecting interface between them. We refer to this technique as Image Latent Boosting (ILB). Extensive experimental results demonstrate that the proposed method significantly improves the image reconstruction quality of the diffusion model, as well as the performance of downstream tasks, including image editing and rare concept generation.
Unleashing Video Language Models for Fine-grained HRCT Report Generation
Mar 12, 2026Generating precise diagnostic reports from High-Resolution Computed Tomography (HRCT) is critical for clinical workflow, yet it remains a formidable challenge due to the high pathological diversity and spatial sparsity within 3D volumes. While Video Language Models (VideoLMs) have demonstrated remarkable spatio-temporal reasoning in general domains, their adaptability to domain-specific, high-volume medical interpretation remains underexplored. In this work, we present AbSteering, an abnormality-centric framework that steers VideoLMs toward precise HRCT report generation. Specifically, AbSteering introduces: (i) an abnormality-centric Chain-of-Thought scheme that enforces abnormality reasoning, and (ii) a Direct Preference Optimization objective that utilizes clinically confusable abnormalities as hard negatives to enhance fine-grained discrimination. Our results demonstrate that general-purpose VideoLMs possess strong transferability to high-volume medical imaging when guided by this paradigm. Notably, AbSteering outperforms state-of-the-art domain-specific CT foundation models, which are pretrained with large-scale CTs, achieving superior detection sensitivity while simultaneously mitigating hallucinations. Our data and model weights are released at https://anonymous.4open.science/r/hrct-report-generation-video-vlm-728C/
Behavioral Feature Boosting via Substitute Relationships for E-commerce Search
Feb 16, 2026On E-commerce platforms, new products often suffer from the cold-start problem: limited interaction data reduces their search visibility and hurts relevance ranking. To address this, we propose a simple yet effective behavior feature boosting method that leverages substitute relationships among products (BFS). BFS identifies substitutes-products that satisfy similar user needs-and aggregates their behavioral signals (e.g., clicks, add-to-carts, purchases, and ratings) to provide a warm start for new items. Incorporating these enriched signals into ranking models mitigates cold-start effects and improves relevance and competitiveness. Experiments on a large E-commerce platform, both offline and online, show that BFS significantly improves search relevance and product discovery for cold-start products. BFS is scalable and practical, improving user experience while increasing exposure for newly launched items in E-commerce search. The BFS-enhanced ranking model has been launched in production and has served customers since 2025.
DeepMTL2R: A Library for Deep Multi-task Learning to Rank
Feb 16, 2026This paper presents DeepMTL2R, an open-source deep learning framework for Multi-task Learning to Rank (MTL2R), where multiple relevance criteria must be optimized simultaneously. DeepMTL2R integrates heterogeneous relevance signals into a unified, context-aware model by leveraging the self-attention mechanism of transformer architectures, enabling effective learning across diverse and potentially conflicting objectives. The framework includes 21 state-of-the-art multi-task learning algorithms and supports multi-objective optimization to identify Pareto-optimal ranking models. By capturing complex dependencies and long-range interactions among items and labels, DeepMTL2R provides a scalable and expressive solution for modern ranking systems and facilitates controlled comparisons across MTL strategies. We demonstrate its effectiveness on a publicly available dataset, report competitive performance, and visualize the resulting trade-offs among objectives. DeepMTL2R is available at \href{https://github.com/amazon-science/DeepMTL2R}{https://github.com/amazon-science/DeepMTL2R}.
Understanding the Implicit User Intention via Reasoning with Large Language Model for Image Editing
Oct 31, 2025Existing image editing methods can handle simple editing instructions very well. To deal with complex editing instructions, they often need to jointly fine-tune the large language models (LLMs) and diffusion models (DMs), which involves very high computational complexity and training cost. To address this issue, we propose a new method, called \textbf{C}omplex \textbf{I}mage \textbf{E}diting via \textbf{L}LM \textbf{R}easoning (CIELR), which converts a complex user instruction into a set of simple and explicit editing actions, eliminating the need for jointly fine-tuning the large language models and diffusion models. Specifically, we first construct a structured semantic representation of the input image using foundation models. Then, we introduce an iterative update mechanism that can progressively refine this representation, obtaining a fine-grained visual representation of the image scene. This allows us to perform complex and flexible image editing tasks. Extensive experiments on the SmartEdit Reasoning Scenario Set show that our method surpasses the previous state-of-the-art by 9.955 dB in PSNR, indicating its superior preservation of regions that should remain consistent. Due to the limited number of samples of public datasets of complex image editing with reasoning, we construct a benchmark named CIEBench, containing 86 image samples, together with a metric specifically for reasoning-based image editing. CIELR also outperforms previous methods on this benchmark. The code and dataset are available at \href{https://github.com/Jia-shao/Reasoning-Editing}{https://github.com/Jia-shao/Reasoning-Editing}.
Generative Semantic Coding for Ultra-Low Bitrate Visual Communication and Analysis
Oct 31, 2025
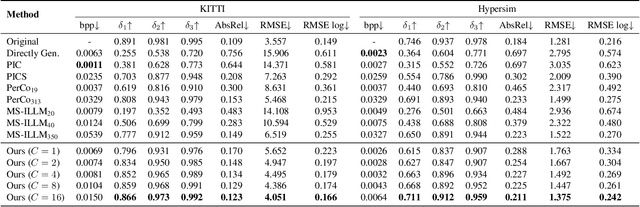

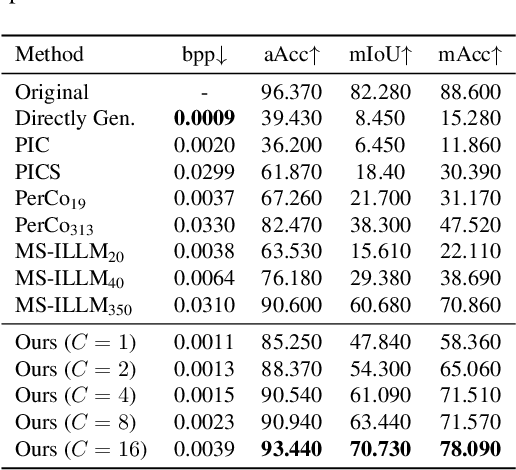
We consider the problem of ultra-low bit rate visual communication for remote vision analysis, human interactions and control in challenging scenarios with very low communication bandwidth, such as deep space exploration, battlefield intelligence, and robot navigation in complex environments. In this paper, we ask the following important question: can we accurately reconstruct the visual scene using only a very small portion of the bit rate in existing coding methods while not sacrificing the accuracy of vision analysis and performance of human interactions? Existing text-to-image generation models offer a new approach for ultra-low bitrate image description. However, they can only achieve a semantic-level approximation of the visual scene, which is far insufficient for the purpose of visual communication and remote vision analysis and human interactions. To address this important issue, we propose to seamlessly integrate image generation with deep image compression, using joint text and coding latent to guide the rectified flow models for precise generation of the visual scene. The semantic text description and coding latent are both encoded and transmitted to the decoder at a very small bit rate. Experimental results demonstrate that our method can achieve the same image reconstruction quality and vision analysis accuracy as existing methods while using much less bandwidth. The code will be released upon paper acceptance.
Runge-Kutta Approximation and Decoupled Attention for Rectified Flow Inversion and Semantic Editing
Sep 16, 2025Rectified flow (RF) models have recently demonstrated superior generative performance compared to DDIM-based diffusion models. However, in real-world applications, they suffer from two major challenges: (1) low inversion accuracy that hinders the consistency with the source image, and (2) entangled multimodal attention in diffusion transformers, which hinders precise attention control. To address the first challenge, we propose an efficient high-order inversion method for rectified flow models based on the Runge-Kutta solver of differential equations. To tackle the second challenge, we introduce Decoupled Diffusion Transformer Attention (DDTA), a novel mechanism that disentangles text and image attention inside the multimodal diffusion transformers, enabling more precise semantic control. Extensive experiments on image reconstruction and text-guided editing tasks demonstrate that our method achieves state-of-the-art performance in terms of fidelity and editability. Code is available at https://github.com/wmchen/RKSovler_DDTA.
CVBench: Evaluating Cross-Video Synergies for Complex Multimodal Understanding and Reasoning
Aug 28, 2025While multimodal large language models (MLLMs) exhibit strong performance on single-video tasks (e.g., video question answering), their ability across multiple videos remains critically underexplored. However, this capability is essential for real-world applications, including multi-camera surveillance and cross-video procedural learning. To bridge this gap, we present CVBench, the first comprehensive benchmark designed to assess cross-video relational reasoning rigorously. CVBench comprises 1,000 question-answer pairs spanning three hierarchical tiers: cross-video object association (identifying shared entities), cross-video event association (linking temporal or causal event chains), and cross-video complex reasoning (integrating commonsense and domain knowledge). Built from five domain-diverse video clusters (e.g., sports, life records), the benchmark challenges models to synthesise information across dynamic visual contexts. Extensive evaluation of 10+ leading MLLMs (including GPT-4o, Gemini-2.0-flash, Qwen2.5-VL) under zero-shot or chain-of-thought prompting paradigms. Key findings reveal stark performance gaps: even top models, such as GPT-4o, achieve only 60% accuracy on causal reasoning tasks, compared to the 91% accuracy of human performance. Crucially, our analysis reveals fundamental bottlenecks inherent in current MLLM architectures, notably deficient inter-video context retention and poor disambiguation of overlapping entities. CVBench establishes a rigorous framework for diagnosing and advancing multi-video reasoning, offering architectural insights for next-generation MLLMs. The data and evaluation code are available at https://github.com/Hokhim2/CVBench.
A multi-source data power load forecasting method using attention mechanism-based parallel cnn-gru
Sep 26, 2024



Accurate power load forecasting is crucial for improving energy efficiency and ensuring power supply quality. Considering the power load forecasting problem involves not only dynamic factors like historical load variations but also static factors such as climate conditions that remain constant over specific periods. From the model-agnostic perspective, this paper proposes a parallel structure network to extract important information from both dynamic and static data. Firstly, based on complexity learning theory, it is demonstrated that models integrated through parallel structures exhibit superior generalization abilities compared to individual base learners. Additionally, the higher the independence between base learners, the stronger the generalization ability of the parallel structure model. This suggests that the structure of machine learning models inherently contains significant information. Building on this theoretical foundation, a parallel convolutional neural network (CNN)-gate recurrent unit (GRU) attention model (PCGA) is employed to address the power load forecasting issue, aiming to effectively integrate the influences of dynamic and static features. The CNN module is responsible for capturing spatial characteristics from static data, while the GRU module captures long-term dependencies in dynamic time series data. The attention layer is designed to focus on key information from the spatial-temporal features extracted by the parallel CNN-GRU. To substantiate the advantages of the parallel structure model in extracting and integrating multi-source information, a series of experiments are conducted.
Regularized Contrastive Partial Multi-view Outlier Detection
Aug 02, 2024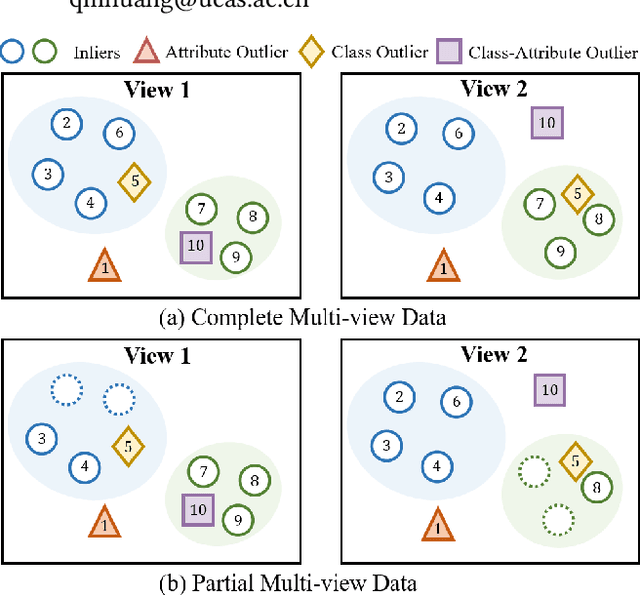
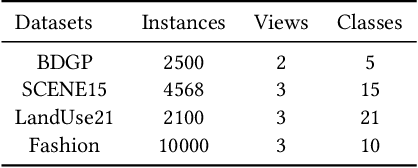
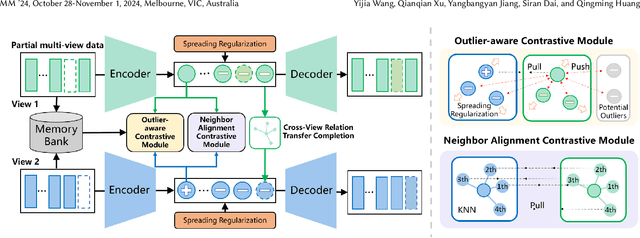
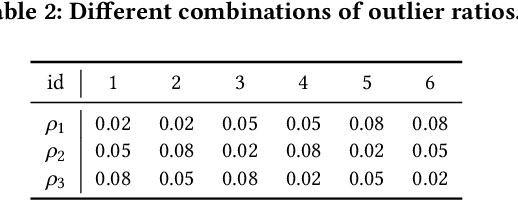
In recent years, multi-view outlier detection (MVOD) methods have advanced significantly, aiming to identify outliers within multi-view datasets. A key point is to better detect class outliers and class-attribute outliers, which only exist in multi-view data. However, existing methods either is not able to reduce the impact of outliers when learning view-consistent information, or struggle in cases with varying neighborhood structures. Moreover, most of them do not apply to partial multi-view data in real-world scenarios. To overcome these drawbacks, we propose a novel method named Regularized Contrastive Partial Multi-view Outlier Detection (RCPMOD). In this framework, we utilize contrastive learning to learn view-consistent information and distinguish outliers by the degree of consistency. Specifically, we propose (1) An outlier-aware contrastive loss with a potential outlier memory bank to eliminate their bias motivated by a theoretical analysis. (2) A neighbor alignment contrastive loss to capture the view-shared local structural correlation. (3) A spreading regularization loss to prevent the model from overfitting over outliers. With the Cross-view Relation Transfer technique, we could easily impute the missing view samples based on the features of neighbors. Experimental results on four benchmark datasets demonstrate that our proposed approach could outperform state-of-the-art competitors under different settings.