 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$P^2$GNN: Two Prototype Sets to boost GNN Performance
Mar 10, 2026Message Passing Graph Neural Networks (MP-GNNs) have garnered attention for addressing various industry challenges, such as user recommendation and fraud detection. However, they face two major hurdles: (1) heavy reliance on local context, often lacking information about the global context or graph-level features, and (2) assumption of strong homophily among connected nodes, struggling with noisy local neighborhoods. To tackle these, we introduce $P^2$GNN, a plug-and-play technique leveraging prototypes to optimize message passing, enhancing the performance of the base GNN model. Our approach views the prototypes in two ways: (1) as universally accessible neighbors for all nodes, enriching global context, and (2) aligning messages to clustered prototypes, offering a denoising effect. We demonstrate the extensibility of our proposed method to all message-passing GNNs and conduct extensive experiments across 18 datasets, including proprietary e-commerce datasets and open-source datasets, on node recommendation and node classification tasks. Results show that $P^2$GNN outperforms production models in e-commerce and achieves the top average rank on open-source datasets, establishing it as a leading approach. Qualitative analysis supports the value of global context and noise mitigation in the local neighborhood in enhancing performance.
DeepMTL2R: A Library for Deep Multi-task Learning to Rank
Feb 16, 2026This paper presents DeepMTL2R, an open-source deep learning framework for Multi-task Learning to Rank (MTL2R), where multiple relevance criteria must be optimized simultaneously. DeepMTL2R integrates heterogeneous relevance signals into a unified, context-aware model by leveraging the self-attention mechanism of transformer architectures, enabling effective learning across diverse and potentially conflicting objectives. The framework includes 21 state-of-the-art multi-task learning algorithms and supports multi-objective optimization to identify Pareto-optimal ranking models. By capturing complex dependencies and long-range interactions among items and labels, DeepMTL2R provides a scalable and expressive solution for modern ranking systems and facilitates controlled comparisons across MTL strategies. We demonstrate its effectiveness on a publicly available dataset, report competitive performance, and visualize the resulting trade-offs among objectives. DeepMTL2R is available at \href{https://github.com/amazon-science/DeepMTL2R}{https://github.com/amazon-science/DeepMTL2R}.
Behavioral Feature Boosting via Substitute Relationships for E-commerce Search
Feb 16, 2026On E-commerce platforms, new products often suffer from the cold-start problem: limited interaction data reduces their search visibility and hurts relevance ranking. To address this, we propose a simple yet effective behavior feature boosting method that leverages substitute relationships among products (BFS). BFS identifies substitutes-products that satisfy similar user needs-and aggregates their behavioral signals (e.g., clicks, add-to-carts, purchases, and ratings) to provide a warm start for new items. Incorporating these enriched signals into ranking models mitigates cold-start effects and improves relevance and competitiveness. Experiments on a large E-commerce platform, both offline and online, show that BFS significantly improves search relevance and product discovery for cold-start products. BFS is scalable and practical, improving user experience while increasing exposure for newly launched items in E-commerce search. The BFS-enhanced ranking model has been launched in production and has served customers since 2025.
Scalable Bilevel Loss Balancing for Multi-Task Learning
Feb 12, 2025



Multi-task learning (MTL) has been widely adopted for its ability to simultaneously learn multiple tasks. While existing gradient manipulation methods often yield more balanced solutions than simple scalarization-based approaches, they typically incur a significant computational overhead of $\mathcal{O}(K)$ in both time and memory, where $K$ is the number of tasks. In this paper, we propose BiLB4MTL, a simple and scalable loss balancing approach for MTL, formulated from a novel bilevel optimization perspective. Our method incorporates three key components: (i) an initial loss normalization, (ii) a bilevel loss-balancing formulation, and (iii) a scalable first-order algorithm that requires only $\mathcal{O}(1)$ time and memory. Theoretically, we prove that BiLB4MTL guarantees convergence not only to a stationary point of the bilevel loss balancing problem but also to an $\epsilon$-accurate Pareto stationary point for all $K$ loss functions under mild conditions. Extensive experiments on diverse multi-task datasets demonstrate that BiLB4MTL achieves state-of-the-art performance in both accuracy and efficiency. Code is available at https://github.com/OptMN-Lab/-BiLB4MTL.
Q-Tuning: Queue-based Prompt Tuning for Lifelong Few-shot Language Learning
Apr 22, 2024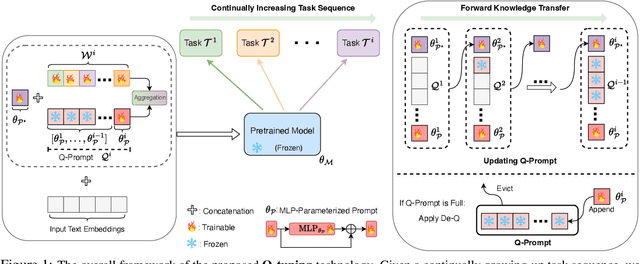
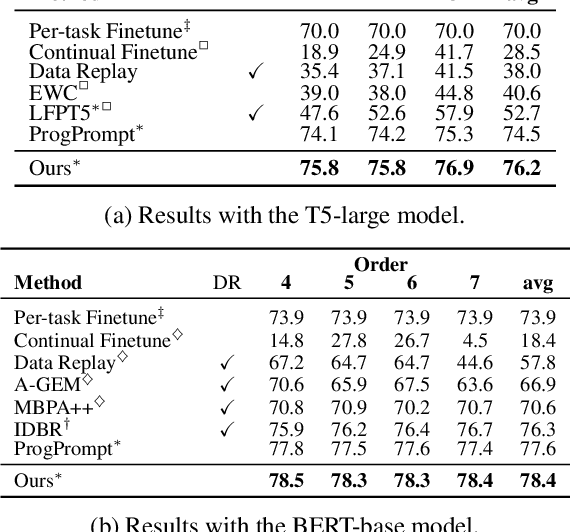
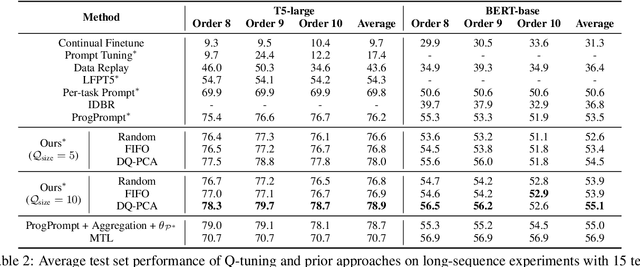
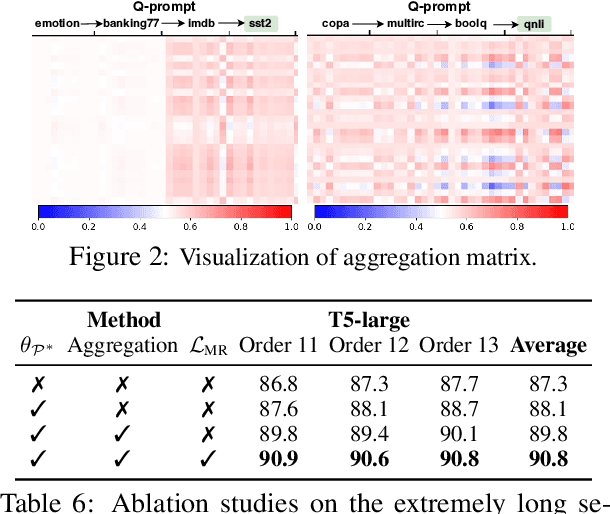
This paper introduces \textbf{Q-tuning}, a novel approach for continual prompt tuning that enables the lifelong learning of a pre-trained language model. When learning a new task, Q-tuning trains a task-specific prompt by adding it to a prompt queue consisting of the prompts from older tasks. To better transfer the knowledge of old tasks, we design an adaptive knowledge aggregation technique that reweighs previous prompts in the queue with a learnable low-rank matrix. Once the prompt queue reaches its maximum capacity, we leverage a PCA-based eviction rule to reduce the queue's size, allowing the newly trained prompt to be added while preserving the primary knowledge of old tasks. In order to mitigate the accumulation of information loss caused by the eviction, we additionally propose a globally shared prefix prompt and a memory retention regularization based on information theory. Extensive experiments demonstrate that our approach outperforms the state-of-the-art methods substantially on continual prompt tuning benchmarks. Moreover, our approach enables lifelong learning on linearly growing task sequences while requiring constant complexity for training and inference.
Towards Generalized Inverse Reinforcement Learning
Feb 11, 2024

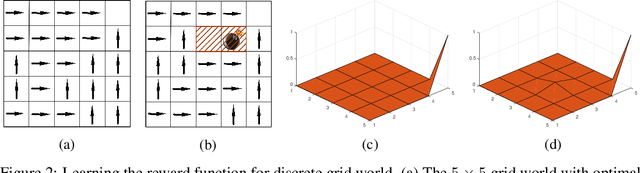

This paper studies generalized inverse reinforcement learning (GIRL) in Markov decision processes (MDPs), that is, the problem of learning the basic components of an MDP given observed behavior (policy) that might not be optimal. These components include not only the reward function and transition probability matrices, but also the action space and state space that are not exactly known but are known to belong to given uncertainty sets. We address two key challenges in GIRL: first, the need to quantify the discrepancy between the observed policy and the underlying optimal policy; second, the difficulty of mathematically characterizing the underlying optimal policy when the basic components of an MDP are unobservable or partially observable. Then, we propose the mathematical formulation for GIRL and develop a fast heuristic algorithm. Numerical results on both finite and infinite state problems show the merit of our formulation and algorithm.
Bandit Learning to Rank with Position-Based Click Models: Personalized and Equal Treatments
Nov 08, 2023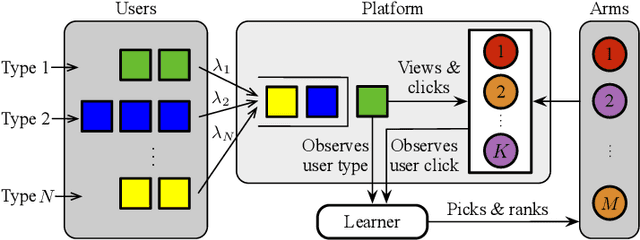
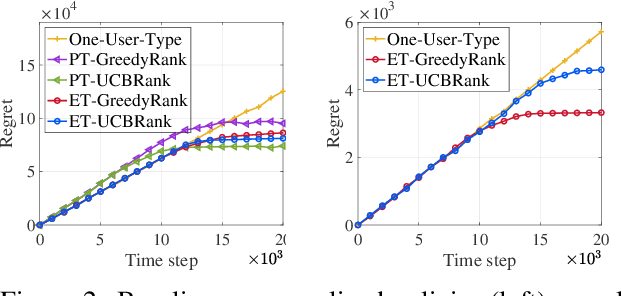

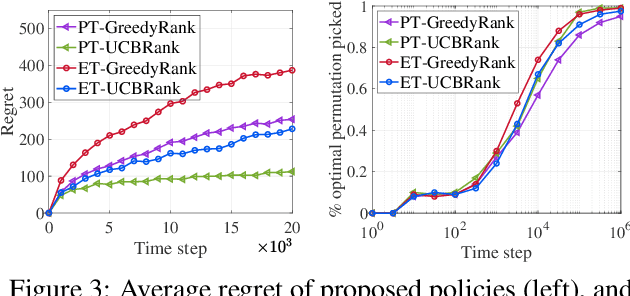
Online learning to rank (ONL2R) is a foundational problem for recommender systems and has received increasing attention in recent years. Among the existing approaches for ONL2R, a natural modeling architecture is the multi-armed bandit framework coupled with the position-based click model. However, developing efficient online learning policies for MAB-based ONL2R with position-based click models is highly challenging due to the combinatorial nature of the problem, and partial observability in the position-based click model. To date, results in MAB-based ONL2R with position-based click models remain rather limited, which motivates us to fill this gap in this work. Our main contributions in this work are threefold: i) We propose the first general MAB framework that captures all key ingredients of ONL2R with position-based click models. Our model considers personalized and equal treatments in ONL2R ranking recommendations, both of which are widely used in practice; ii) Based on the above analytical framework, we develop two unified greed- and UCB-based policies called GreedyRank and UCBRank, each of which can be applied to personalized and equal ranking treatments; and iii) We show that both GreedyRank and UCBRank enjoy $O(\sqrt{t}\ln t)$ and $O(\sqrt{t\ln t})$ anytime sublinear regret for personalized and equal treatment, respectively. For the fundamentally hard equal ranking treatment, we identify classes of collective utility functions and their associated sufficient conditions under which $O(\sqrt{t}\ln t)$ and $O(\sqrt{t\ln t})$ anytime sublinear regrets are still achievable for GreedyRank and UCBRank, respectively. Our numerical experiments also verify our theoretical results and demonstrate the efficiency of GreedyRank and UCBRank in seeking the optimal action under various problem settings.
Federated Multi-Objective Learning
Oct 15, 2023



In recent years, multi-objective optimization (MOO) emerges as a foundational problem underpinning many multi-agent multi-task learning applications. However, existing algorithms in MOO literature remain limited to centralized learning settings, which do not satisfy the distributed nature and data privacy needs of such multi-agent multi-task learning applications. This motivates us to propose a new federated multi-objective learning (FMOL) framework with multiple clients distributively and collaboratively solving an MOO problem while keeping their training data private. Notably, our FMOL framework allows a different set of objective functions across different clients to support a wide range of applications, which advances and generalizes the MOO formulation to the federated learning paradigm for the first time. For this FMOL framework, we propose two new federated multi-objective optimization (FMOO) algorithms called federated multi-gradient descent averaging (FMGDA) and federated stochastic multi-gradient descent averaging (FSMGDA). Both algorithms allow local updates to significantly reduce communication costs, while achieving the {\em same} convergence rates as those of the their algorithmic counterparts in the single-objective federated learning. Our extensive experiments also corroborate the efficacy of our proposed FMOO algorithms.
G-STO: Sequential Main Shopping Intention Detection via Graph-Regularized Stochastic Transformer
Jun 25, 2023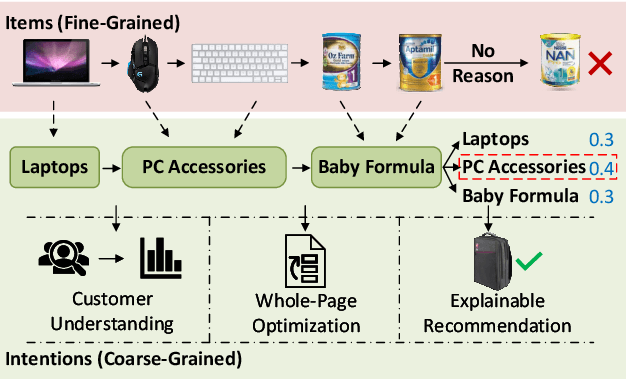

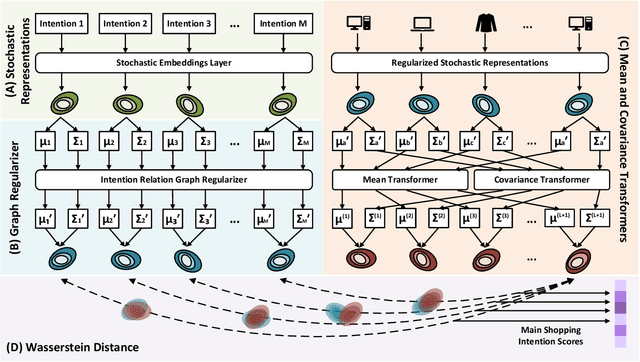
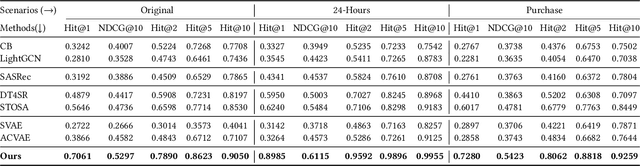
Sequential recommendation requires understanding the dynamic patterns of users' behaviors, contexts, and preferences from their historical interactions. Most existing works focus on modeling user-item interactions only from the item level, ignoring that they are driven by latent shopping intentions (e.g., ballpoint pens, miniatures, etc). The detection of the underlying shopping intentions of users based on their historical interactions is a crucial aspect for e-commerce platforms, such as Amazon, to enhance the convenience and efficiency of their customers' shopping experiences. Despite its significance, the area of main shopping intention detection remains under-investigated in the academic literature. To fill this gap, we propose a graph-regularized stochastic Transformer method, G-STO. By considering intentions as sets of products and user preferences as compositions of intentions, we model both of them as stochastic Gaussian embeddings in the latent representation space. Instead of training the stochastic representations from scratch, we develop a global intention relational graph as prior knowledge for regularization, allowing relevant shopping intentions to be distributionally close. Finally, we feed the newly regularized stochastic embeddings into Transformer-based models to encode sequential information from the intention transitions. We evaluate our main shopping intention identification model on three different real-world datasets, where G-STO achieves significantly superior performances to the baselines by 18.08% in Hit@1, 7.01% in Hit@10, and 6.11% in NDCG@10 on average.
AdaSelection: Accelerating Deep Learning Training through Data Subsampling
Jun 19, 2023
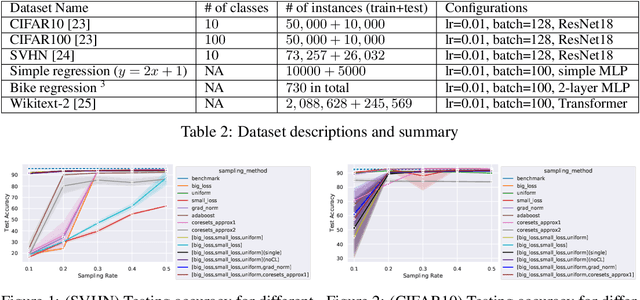
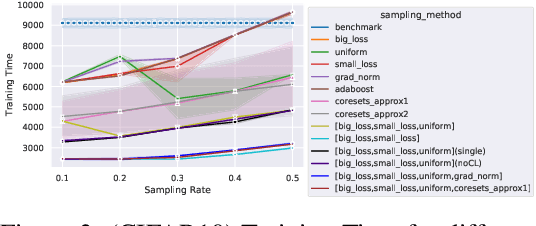
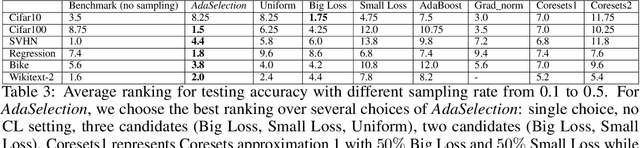
In this paper, we introduce AdaSelection, an adaptive sub-sampling method to identify the most informative sub-samples within each minibatch to speed up the training of large-scale deep learning models without sacrificing model performance. Our method is able to flexibly combines an arbitrary number of baseline sub-sampling methods incorporating the method-level importance and intra-method sample-level importance at each iteration. The standard practice of ad-hoc sampling often leads to continuous training with vast amounts of data from production environments. To improve the selection of data instances during forward and backward passes, we propose recording a constant amount of information per instance from these passes. We demonstrate the effectiveness of our method by testing it across various types of inputs and tasks, including the classification tasks on both image and language datasets, as well as regression tasks. Compared with industry-standard baselines, AdaSelection consistently displays superior performance.