 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Bilevel Loss Balancing for Multi-Task Learning
Feb 12, 2025



Multi-task learning (MTL) has been widely adopted for its ability to simultaneously learn multiple tasks. While existing gradient manipulation methods often yield more balanced solutions than simple scalarization-based approaches, they typically incur a significant computational overhead of $\mathcal{O}(K)$ in both time and memory, where $K$ is the number of tasks. In this paper, we propose BiLB4MTL, a simple and scalable loss balancing approach for MTL, formulated from a novel bilevel optimization perspective. Our method incorporates three key components: (i) an initial loss normalization, (ii) a bilevel loss-balancing formulation, and (iii) a scalable first-order algorithm that requires only $\mathcal{O}(1)$ time and memory. Theoretically, we prove that BiLB4MTL guarantees convergence not only to a stationary point of the bilevel loss balancing problem but also to an $\epsilon$-accurate Pareto stationary point for all $K$ loss functions under mild conditions. Extensive experiments on diverse multi-task datasets demonstrate that BiLB4MTL achieves state-of-the-art performance in both accuracy and efficiency. Code is available at https://github.com/OptMN-Lab/-BiLB4MTL.
ReGNet: Reciprocal Space-Aware Long-Range Modeling and Multi-Property Prediction for Crystals
Feb 04, 2025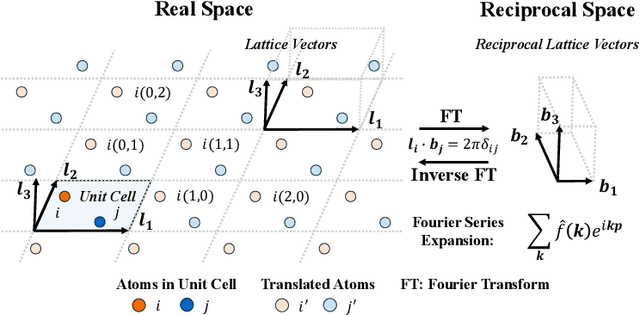
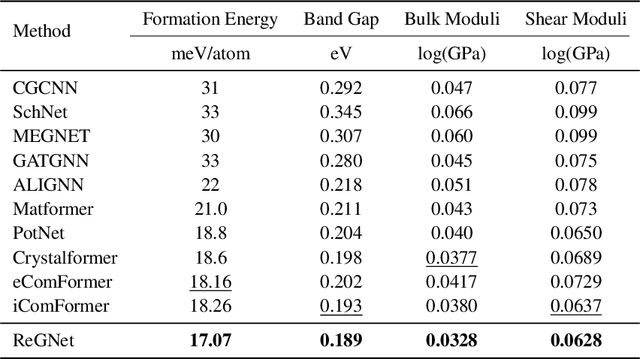
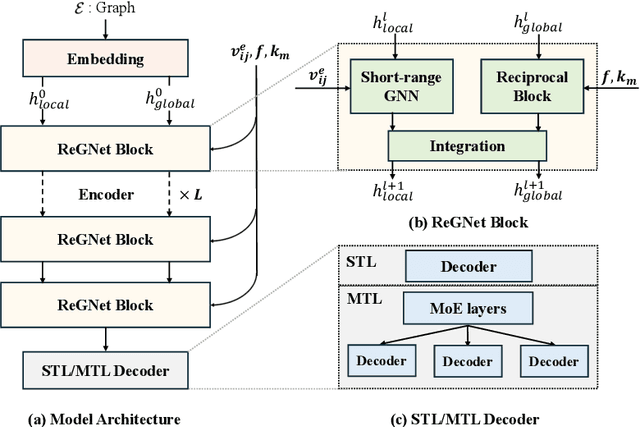
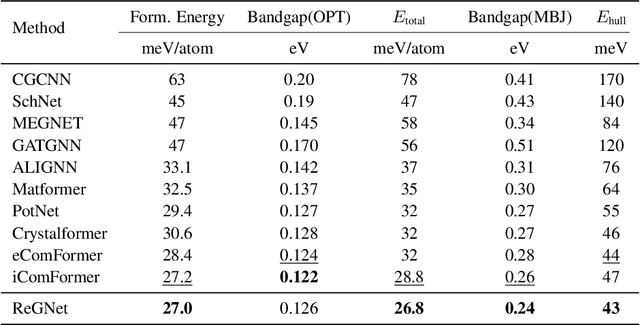
Predicting properties of crystals from their structures is a fundamental yet challenging task in materials science. Unlike molecules, crystal structures exhibit infinite periodic arrangements of atoms, requiring methods capable of capturing both local and global information effectively. However, most current works fall short of capturing long-range interactions within periodic structures. To address this limitation, we leverage reciprocal space to efficiently encode long-range interactions with learnable filters within Fourier transforms. We introduce Reciprocal Geometry Network (ReGNet), a novel architecture that integrates geometric GNNs and reciprocal blocks to model short-range and long-range interactions, respectively. Additionally, we introduce ReGNet-MT, a multi-task extension that employs mixture of experts (MoE) for multi-property prediction. Experimental results on the JARVIS and Materials Project benchmarks demonstrate that ReGNet achieves significant performance improvements. Moreover, ReGNet-MT attains state-of-the-art results on two bandgap properties due to positive transfer, while maintaining high computational efficiency. These findings highlight the potential of our model as a scalable and accurate solution for crystal property prediction. The code will be released upon paper acceptance.
On the Convergence of Multi-objective Optimization under Generalized Smoothness
May 29, 2024



Multi-objective optimization (MOO) is receiving more attention in various fields such as multi-task learning. Recent works provide some effective algorithms with theoretical analysis but they are limited by the standard $L$-smooth or bounded-gradient assumptions, which are typically unsatisfactory for neural networks, such as recurrent neural networks (RNNs) and transformers. In this paper, we study a more general and realistic class of $\ell$-smooth loss functions, where $\ell$ is a general non-decreasing function of gradient norm. We develop two novel single-loop algorithms for $\ell$-smooth MOO problems, Generalized Smooth Multi-objective Gradient descent (GSMGrad) and its stochastic variant, Stochastic Generalized Smooth Multi-objective Gradient descent (SGSMGrad), which approximate the conflict-avoidant (CA) direction that maximizes the minimum improvement among objectives. We provide a comprehensive convergence analysis of both algorithms and show that they converge to an $\epsilon$-accurate Pareto stationary point with a guaranteed $\epsilon$-level average CA distance (i.e., the gap between the updating direction and the CA direction) over all iterations, where totally $\mathcal{O}(\epsilon^{-2})$ and $\mathcal{O}(\epsilon^{-4})$ samples are needed for deterministic and stochastic settings, respectively. Our algorithms can also guarantee a tighter $\epsilon$-level CA distance in each iteration using more samples. Moreover, we propose a practical variant of GSMGrad named GSMGrad-FA using only constant-level time and space, while achieving the same performance guarantee as GSMGrad. Our experiments validate our theory and demonstrate the effectiveness of the proposed methods.
Finite-Time Analysis for Conflict-Avoidant Multi-Task Reinforcement Learning
May 25, 2024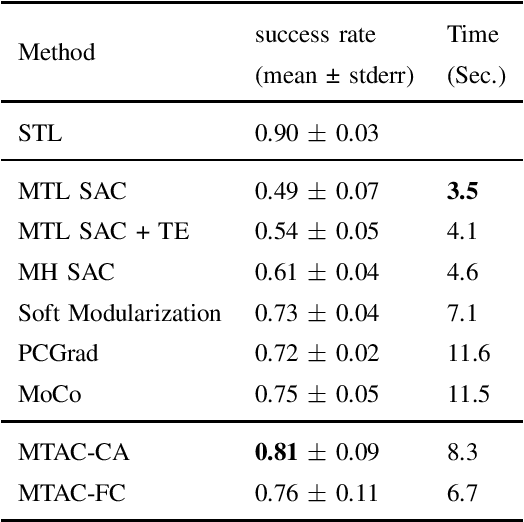
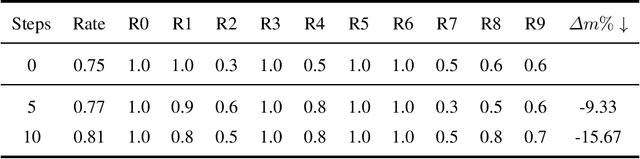
Multi-task reinforcement learning (MTRL) has shown great promise in many real-world applications. Existing MTRL algorithms often aim to learn a policy that optimizes individual objective functions simultaneously with a given prior preference (or weights) on different tasks. However, these methods often suffer from the issue of \textit{gradient conflict} such that the tasks with larger gradients dominate the update direction, resulting in a performance degeneration on other tasks. In this paper, we develop a novel dynamic weighting multi-task actor-critic algorithm (MTAC) under two options of sub-procedures named as CA and FC in task weight updates. MTAC-CA aims to find a conflict-avoidant (CA) update direction that maximizes the minimum value improvement among tasks, and MTAC-FC targets at a much faster convergence rate. We provide a comprehensive finite-time convergence analysis for both algorithms. We show that MTAC-CA can find a $\epsilon+\epsilon_{\text{app}}$-accurate Pareto stationary policy using $\mathcal{O}({\epsilon^{-5}})$ samples, while ensuring a small $\epsilon+\sqrt{\epsilon_{\text{app}}}$-level CA distance (defined as the distance to the CA direction), where $\epsilon_{\text{app}}$ is the function approximation error. The analysis also shows that MTAC-FC improves the sample complexity to $\mathcal{O}(\epsilon^{-3})$, but with a constant-level CA distance. Our experiments on MT10 demonstrate the improved performance of our algorithms over existing MTRL methods with fixed preference.
Achieving ${O}(ε^{-1.5})$ Complexity in Hessian/Jacobian-free Stochastic Bilevel Optimization
Dec 20, 2023In this paper, we revisit the bilevel optimization problem, in which the upper-level objective function is generally nonconvex and the lower-level objective function is strongly convex. Although this type of problem has been studied extensively, it still remains an open question how to achieve an ${O}(\epsilon^{-1.5})$ sample complexity in Hessian/Jacobian-free stochastic bilevel optimization without any second-order derivative computation. To fill this gap, we propose a novel Hessian/Jacobian-free bilevel optimizer named FdeHBO, which features a simple fully single-loop structure, a projection-aided finite-difference Hessian/Jacobian-vector approximation, and momentum-based updates. Theoretically, we show that FdeHBO requires ${O}(\epsilon^{-1.5})$ iterations (each using ${O}(1)$ samples and only first-order gradient information) to find an $\epsilon$-accurate stationary point. As far as we know, this is the first Hessian/Jacobian-free method with an ${O}(\epsilon^{-1.5})$ sample complexity for nonconvex-strongly-convex stochastic bilevel optimization.
SimFBO: Towards Simple, Flexible and Communication-efficient Federated Bilevel Learning
Jun 12, 2023Federated bilevel optimization (FBO) has shown great potential recently in machine learning and edge computing due to the emerging nested optimization structure in meta-learning, fine-tuning, hyperparameter tuning, etc. However, existing FBO algorithms often involve complicated computations and require multiple sub-loops per iteration, each of which contains a number of communication rounds. In this paper, we propose a simple and flexible FBO framework named SimFBO, which is easy to implement without sub-loops, and includes a generalized server-side aggregation and update for improving communication efficiency. We further propose System-level heterogeneity robust FBO (ShroFBO) as a variant of SimFBO with stronger resilience to heterogeneous local computation. We show that SimFBO and ShroFBO provably achieve a linear convergence speedup with partial client participation and client sampling without replacement, as well as improved sample and communication complexities. Experiments demonstrate the effectiveness of the proposed methods over existing FBO algorithms.
Direction-oriented Multi-objective Learning: Simple and Provable Stochastic Algorithms
May 28, 2023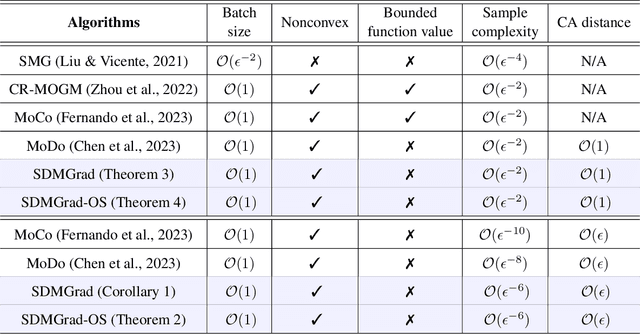
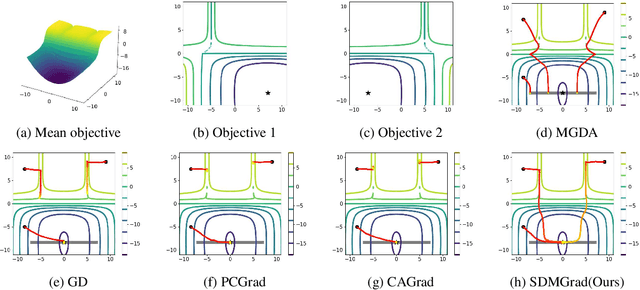
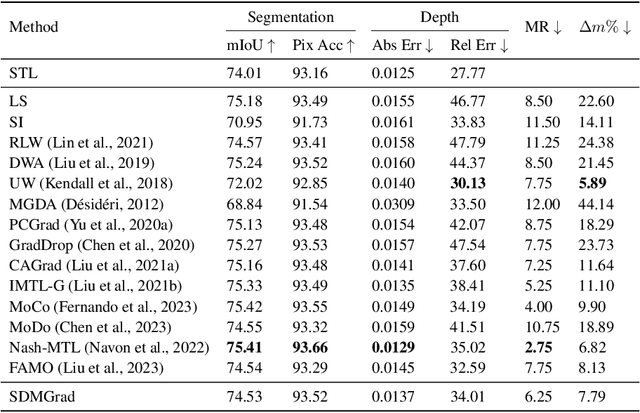
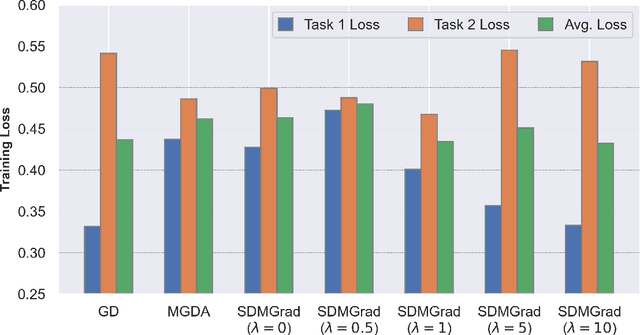
Multi-objective optimization (MOO) has become an influential framework in many machine learning problems with multiple objectives such as learning with multiple criteria and multi-task learning (MTL). In this paper, we propose a new direction-oriented multi-objective problem by regularizing the common descent direction within a neighborhood of a direction that optimizes a linear combination of objectives such as the average loss in MTL. This formulation includes GD and MGDA as special cases, enjoys the direction-oriented benefit as in CAGrad, and facilitates the design of stochastic algorithms. To solve this problem, we propose Stochastic Direction-oriented Multi-objective Gradient descent (SDMGrad) with simple SGD type of updates, and its variant SDMGrad-OS with an efficient objective sampling in the setting where the number of objectives is large. For a constant-level regularization parameter $\lambda$, we show that SDMGrad and SDMGrad-OS provably converge to a Pareto stationary point with improved complexities and milder assumptions. For an increasing $\lambda$, this convergent point reduces to a stationary point of the linear combination of objectives. We demonstrate the superior performance of the proposed methods in a series of tasks on multi-task supervised learning and reinforcement learning. Code is provided at https://github.com/ml-opt-lab/sdmgrad.
Communication-Efficient Federated Hypergradient Computation via Aggregated Iterative Differentiation
Feb 23, 2023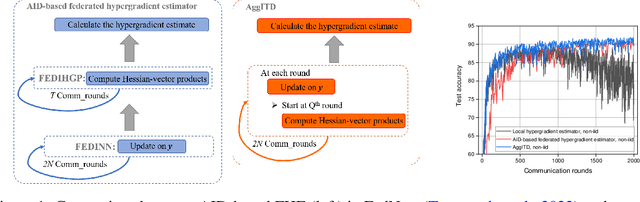



Federated bilevel optimization has attracted increasing attention due to emerging machine learning and communication applications. The biggest challenge lies in computing the gradient of the upper-level objective function (i.e., hypergradient) in the federated setting due to the nonlinear and distributed construction of a series of global Hessian matrices. In this paper, we propose a novel communication-efficient federated hypergradient estimator via aggregated iterative differentiation (AggITD). AggITD is simple to implement and significantly reduces the communication cost by conducting the federated hypergradient estimation and the lower-level optimization simultaneously. We show that the proposed AggITD-based algorithm achieves the same sample complexity as existing approximate implicit differentiation (AID)-based approaches with much fewer communication rounds in the presence of data heterogeneity. Our results also shed light on the great advantage of ITD over AID in the federated/distributed hypergradient estimation. This differs from the comparison in the non-distributed bilevel optimization, where ITD is less efficient than AID. Our extensive experiments demonstrate the great effectiveness and communication efficiency of the proposed method.