 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinite-Time Analysis for Conflict-Avoidant Multi-Task Reinforcement Learning
Paper and Code
May 25, 2024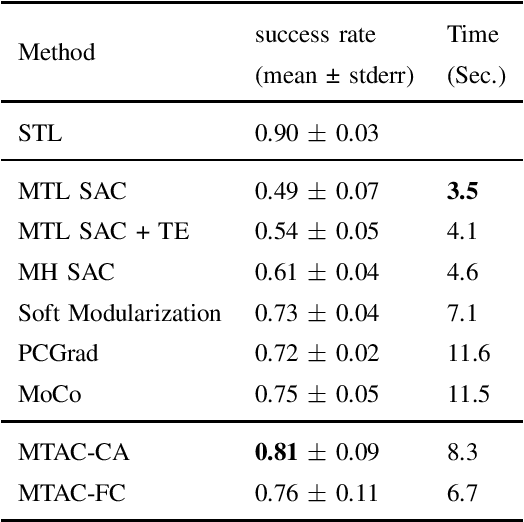
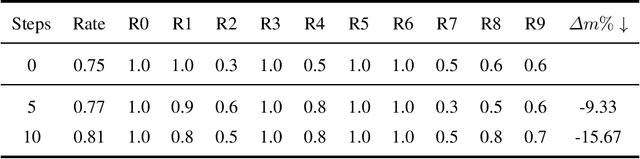
Multi-task reinforcement learning (MTRL) has shown great promise in many real-world applications. Existing MTRL algorithms often aim to learn a policy that optimizes individual objective functions simultaneously with a given prior preference (or weights) on different tasks. However, these methods often suffer from the issue of \textit{gradient conflict} such that the tasks with larger gradients dominate the update direction, resulting in a performance degeneration on other tasks. In this paper, we develop a novel dynamic weighting multi-task actor-critic algorithm (MTAC) under two options of sub-procedures named as CA and FC in task weight updates. MTAC-CA aims to find a conflict-avoidant (CA) update direction that maximizes the minimum value improvement among tasks, and MTAC-FC targets at a much faster convergence rate. We provide a comprehensive finite-time convergence analysis for both algorithms. We show that MTAC-CA can find a $\epsilon+\epsilon_{\text{app}}$-accurate Pareto stationary policy using $\mathcal{O}({\epsilon^{-5}})$ samples, while ensuring a small $\epsilon+\sqrt{\epsilon_{\text{app}}}$-level CA distance (defined as the distance to the CA direction), where $\epsilon_{\text{app}}$ is the function approximation error. The analysis also shows that MTAC-FC improves the sample complexity to $\mathcal{O}(\epsilon^{-3})$, but with a constant-level CA distance. Our experiments on MT10 demonstrate the improved performance of our algorithms over existing MTRL methods with fixed preference.