 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Latent-CoT Models Think Step-by-Step? A Mechanistic Study on Sequential Reasoning Tasks
Jan 31, 2026Latent Chain-of-Thought (Latent-CoT) aims to enable step-by-step computation without emitting long rationales, yet its mechanisms remain unclear. We study CODI, a continuous-thought teacher-student distillation model, on strictly sequential polynomial-iteration tasks. Using logit-lens decoding, linear probes, attention analysis, and activation patching, we localize intermediate-state representations and trace their routing to the final readout. On two- and three-hop tasks, CODI forms the full set of bridge states that become decodable across latent-thought positions, while the final input follows a separate near-direct route; predictions arise via late fusion at the end-of-thought boundary. For longer hop lengths, CODI does not reliably execute a full latent rollout, instead exhibiting a partial latent reasoning path that concentrates on late intermediates and fuses them with the last input at the answer readout position. Ablations show that this partial pathway can collapse under regime shifts, including harder optimization. Overall, we delineate when CODI-style latent-CoT yields faithful iterative computation versus compressed or shortcut strategies, and highlight challenges in designing robust latent-CoT objectives for sequential reasoning.
Acquire Precise and Comparable Fundus Image Quality Score: FTHNet and FQS Dataset
Nov 19, 2024The retinal fundus images are utilized extensively in the diagnosis, and their quality can directly affect the diagnosis results. However, due to the insufficient dataset and algorithm application, current fundus image quality assessment (FIQA) methods are not powerful enough to meet ophthalmologists` demands. In this paper, we address the limitations of datasets and algorithms in FIQA. First, we establish a new FIQA dataset, Fundus Quality Score(FQS), which includes 2246 fundus images with two labels: a continuous Mean Opinion Score varying from 0 to 100 and a three-level quality label. Then, we propose a FIQA Transformer-based Hypernetwork (FTHNet) to solve these tasks with regression results rather than classification results in conventional FIQA works. The FTHNet is optimized for the FIQA tasks with extensive experiments. Results on our FQS dataset show that the FTHNet can give quality scores for fundus images with PLCC of 0.9423 and SRCC of 0.9488, significantly outperforming other methods with fewer parameters and less computation complexity.We successfully build a dataset and model addressing the problems of current FIQA methods. Furthermore, the model deployment experiments demonstrate its potential in automatic medical image quality control. All experiments are carried out with 10-fold cross-validation to ensure the significance of the results.
AdaSelection: Accelerating Deep Learning Training through Data Subsampling
Jun 19, 2023
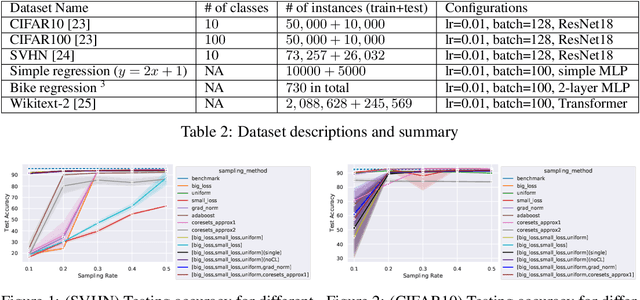
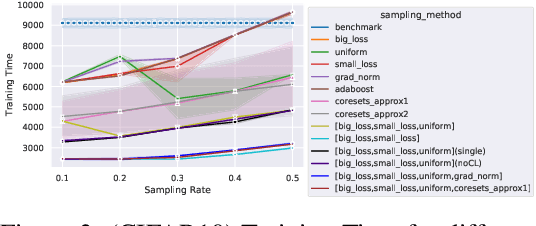
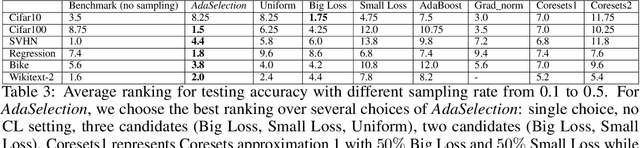
In this paper, we introduce AdaSelection, an adaptive sub-sampling method to identify the most informative sub-samples within each minibatch to speed up the training of large-scale deep learning models without sacrificing model performance. Our method is able to flexibly combines an arbitrary number of baseline sub-sampling methods incorporating the method-level importance and intra-method sample-level importance at each iteration. The standard practice of ad-hoc sampling often leads to continuous training with vast amounts of data from production environments. To improve the selection of data instances during forward and backward passes, we propose recording a constant amount of information per instance from these passes. We demonstrate the effectiveness of our method by testing it across various types of inputs and tasks, including the classification tasks on both image and language datasets, as well as regression tasks. Compared with industry-standard baselines, AdaSelection consistently displays superior performance.
Bone Suppression on Chest Radiographs With Adversarial Learning
Feb 08, 2020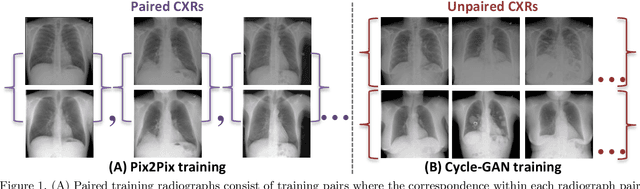

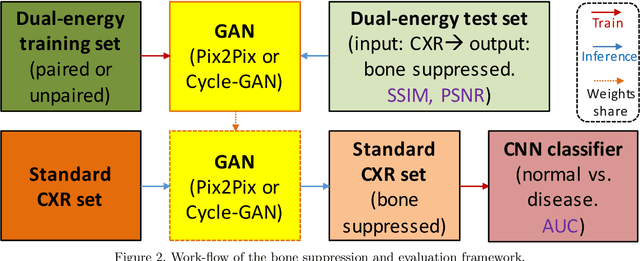
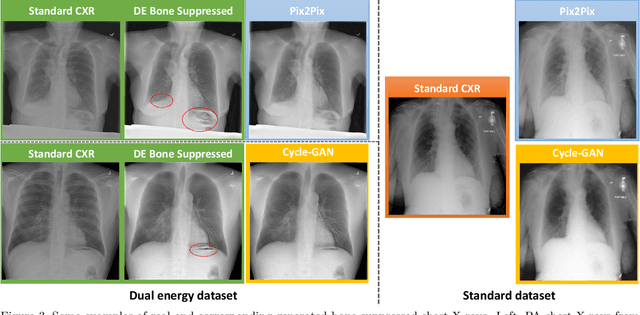
Dual-energy (DE) chest radiography provides the capability of selectively imaging two clinically relevant materials, namely soft tissues, and osseous structures, to better characterize a wide variety of thoracic pathology and potentially improve diagnosis in posteroanterior (PA) chest radiographs. However, DE imaging requires specialized hardware and a higher radiation dose than conventional radiography, and motion artifacts sometimes happen due to involuntary patient motion. In this work, we learn the mapping between conventional radiographs and bone suppressed radiographs. Specifically, we propose to utilize two variations of generative adversarial networks (GANs) for image-to-image translation between conventional and bone suppressed radiographs obtained by DE imaging technique. We compare the effectiveness of training with patient-wisely paired and unpaired radiographs. Experiments show both training strategies yield "radio-realistic'' radiographs with suppressed bony structures and few motion artifacts on a hold-out test set. While training with paired images yields slightly better performance than that of unpaired images when measuring with two objective image quality metrics, namely Structural Similarity Index (SSIM) and Peak Signal-to-Noise Ratio (PSNR), training with unpaired images demonstrates better generalization ability on unseen anteroposterior (AP) radiographs than paired training.
Relating Complexity-theoretic Parameters with SAT Solver Performance
Jun 26, 2017
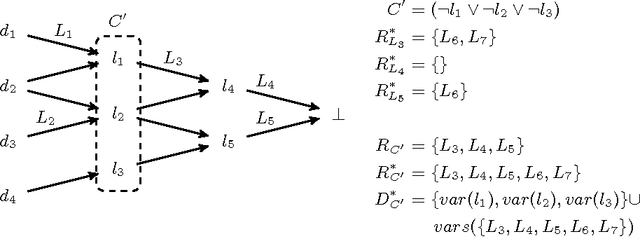
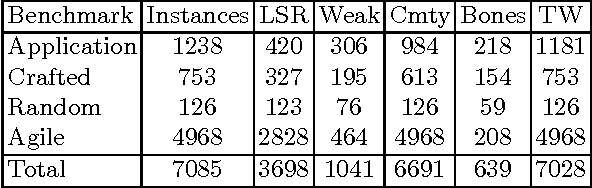

Over the years complexity theorists have proposed many structural parameters to explain the surprising efficiency of conflict-driven clause-learning (CDCL) SAT solvers on a wide variety of large industrial Boolean instances. While some of these parameters have been studied empirically, until now there has not been a unified comparative study of their explanatory power on a comprehensive benchmark. We correct this state of affairs by conducting a large-scale empirical evaluation of CDCL SAT solver performance on nearly 7000 industrial and crafted formulas against several structural parameters such as backdoors, treewidth, backbones, and community structure. Our study led us to several results. First, we show that while such parameters only weakly correlate with CDCL solving time, certain combinations of them yield much better regression models. Second, we show how some parameters can be used as a "lens" to better understand the efficiency of different solving heuristics. Finally, we propose a new complexity-theoretic parameter, which we call learning-sensitive with restarts (LSR) backdoors, that extends the notion of learning-sensitive (LS) backdoors to incorporate restarts and discuss algorithms to compute them. We mathematically prove that for certain class of instances minimal LSR-backdoors are exponentially smaller than minimal-LS backdoors.