 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Graph Neural Networks and Many-Body Expansion Theory for Potential Energy Surfaces
Nov 03, 2024



Rational design of next-generation functional materials relied on quantitative predictions of their electronic structures beyond single building blocks. First-principles quantum mechanical (QM) modeling became infeasible as the size of a material grew beyond hundreds of atoms. In this study, we developed a new computational tool integrating fragment-based graph neural networks (FBGNN) into the fragment-based many-body expansion (MBE) theory, referred to as FBGNN-MBE, and demonstrated its capacity to reproduce full-dimensional potential energy surfaces (FD-PES) for hierarchic chemical systems with manageable accuracy, complexity, and interpretability. In particular, we divided the entire system into basic building blocks (fragments), evaluated their single-fragment energies using a first-principles QM model and attacked many-fragment interactions using the structure-property relationships trained by FBGNNs. Our development of FBGNN-MBE demonstrated the potential of a new framework integrating deep learning models into fragment-based QM methods, and marked a significant step towards computationally aided design of large functional materials.
Improving Subgraph Representation Learning via Multi-View Augmentation
May 25, 2022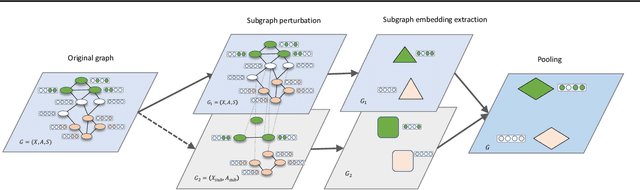
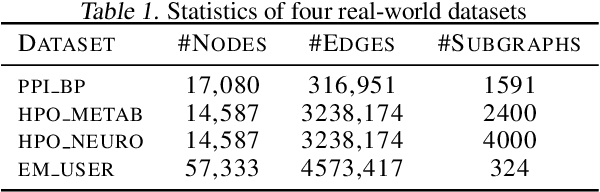

Subgraph representation learning based on Graph Neural Network (GNN) has broad applications in chemistry and biology, such as molecule property prediction and gene collaborative function prediction. On the other hand, graph augmentation techniques have shown promising results in improving graph-based and node-based classification tasks but are rarely explored in the GNN-based subgraph representation learning literature. In this work, we developed a novel multiview augmentation mechanism to improve subgraph representation learning and thus the accuracy of downstream prediction tasks. The augmentation technique creates multiple variants of subgraphs and embeds these variants into the original graph to achieve both high training efficiency, scalability, and improved accuracy. Experiments on several real-world subgraph benchmarks demonstrate the superiority of our proposed multi-view augmentation techniques.
Singularity: Planet-Scale, Preemptive and Elastic Scheduling of AI Workloads
Feb 21, 2022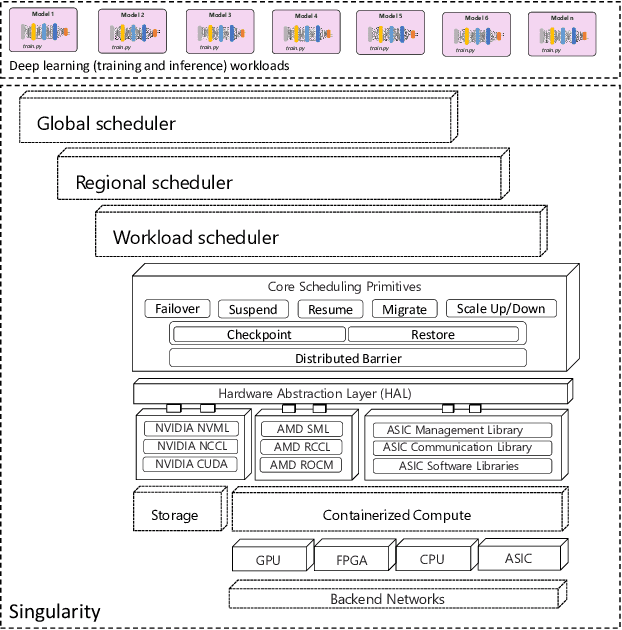
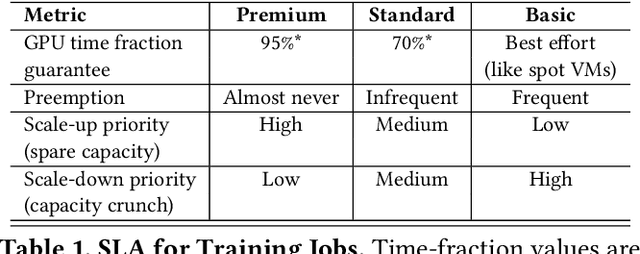
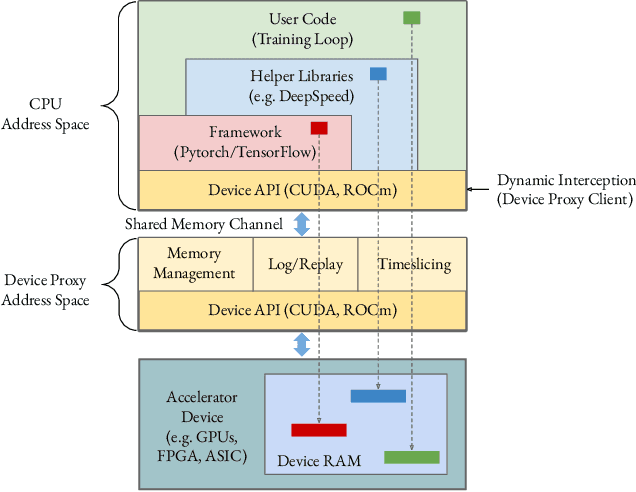
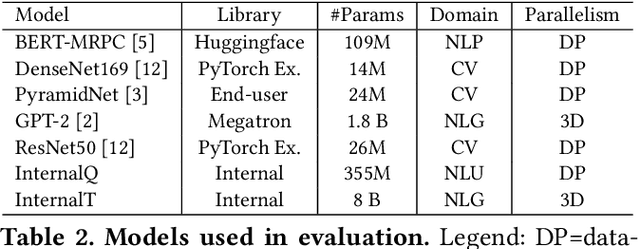
Lowering costs by driving high utilization across deep learning workloads is a crucial lever for cloud providers. We present Singularity, Microsoft's globally distributed scheduling service for highly-efficient and reliable execution of deep learning training and inference workloads. At the heart of Singularity is a novel, workload-aware scheduler that can transparently preempt and elastically scale deep learning workloads to drive high utilization without impacting their correctness or performance, across a global fleet of AI accelerators (e.g., GPUs, FPGAs). All jobs in Singularity are preemptable, migratable, and dynamically resizable (elastic) by default: a live job can be dynamically and transparently (a) preempted and migrated to a different set of nodes, cluster, data center or a region and resumed exactly from the point where the execution was preempted, and (b) resized (i.e., elastically scaled-up/down) on a varying set of accelerators of a given type. Our mechanisms are transparent in that they do not require the user to make any changes to their code or require using any custom libraries that may limit flexibility. Additionally, our approach significantly improves the reliability of deep learning workloads. We show that the resulting efficiency and reliability gains with Singularity are achieved with negligible impact on the steady-state performance. Finally, our design approach is agnostic of DNN architectures and handles a variety of parallelism strategies (e.g., data/pipeline/model parallelism).