 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSHIELD: An Auto-Healing Agentic Defense Framework for LLM Resource Exhaustion Attacks
Jan 27, 2026Sponge attacks increasingly threaten LLM systems by inducing excessive computation and DoS. Existing defenses either rely on statistical filters that fail on semantically meaningful attacks or use static LLM-based detectors that struggle to adapt as attack strategies evolve. We introduce SHIELD, a multi-agent, auto-healing defense framework centered on a three-stage Defense Agent that integrates semantic similarity retrieval, pattern matching, and LLM-based reasoning. Two auxiliary agents, a Knowledge Updating Agent and a Prompt Optimization Agent, form a closed self-healing loop, when an attack bypasses detection, the system updates an evolving knowledgebase, and refines defense instructions. Extensive experiments show that SHIELD consistently outperforms perplexity-based and standalone LLM defenses, achieving high F1 scores across both non-semantic and semantic sponge attacks, demonstrating the effectiveness of agentic self-healing against evolving resource-exhaustion threats.
Prompt-Induced Over-Generation as Denial-of-Service: A Black-Box Attack-Side Benchmark
Dec 29, 2025Large language models (LLMs) can be driven into over-generation, emitting thousands of tokens before producing an end-of-sequence (EOS) token. This degrades answer quality, inflates latency and cost, and can be weaponized as a denial-of-service (DoS) attack. Recent work has begun to study DoS-style prompt attacks, but typically focuses on a single attack algorithm or assumes white-box access, without an attack-side benchmark that compares prompt-based attackers in a black-box, query-only regime with a known tokenizer. We introduce such a benchmark and study two prompt-only attackers. The first is Evolutionary Over-Generation Prompt Search (EOGen), which searches the token space for prefixes that suppress EOS and induce long continuations. The second is a goal-conditioned reinforcement learning attacker (RL-GOAL) that trains a network to generate prefixes conditioned on a target length. To characterize behavior, we introduce Over-Generation Factor (OGF), the ratio of produced tokens to a model's context window, along with stall and latency summaries. Our evolutionary attacker achieves mean OGF = 1.38 +/- 1.15 and Success@OGF >= 2 of 24.5 percent on Phi-3. RL-GOAL is stronger: across victims it achieves higher mean OGF (up to 2.81 +/- 1.38).
Spatio-Temporal Joint Density Driven Learning for Skeleton-Based Action Recognition
May 29, 2025Traditional approaches in unsupervised or self supervised learning for skeleton-based action classification have concentrated predominantly on the dynamic aspects of skeletal sequences. Yet, the intricate interaction between the moving and static elements of the skeleton presents a rarely tapped discriminative potential for action classification. This paper introduces a novel measurement, referred to as spatial-temporal joint density (STJD), to quantify such interaction. Tracking the evolution of this density throughout an action can effectively identify a subset of discriminative moving and/or static joints termed "prime joints" to steer self-supervised learning. A new contrastive learning strategy named STJD-CL is proposed to align the representation of a skeleton sequence with that of its prime joints while simultaneously contrasting the representations of prime and nonprime joints. In addition, a method called STJD-MP is developed by integrating it with a reconstruction-based framework for more effective learning. Experimental evaluations on the NTU RGB+D 60, NTU RGB+D 120, and PKUMMD datasets in various downstream tasks demonstrate that the proposed STJD-CL and STJD-MP improved performance, particularly by 3.5 and 3.6 percentage points over the state-of-the-art contrastive methods on the NTU RGB+D 120 dataset using X-sub and X-set evaluations, respectively.
FullStack Bench: Evaluating LLMs as Full Stack Coders
Dec 03, 2024



As the capabilities of code large language models (LLMs) continue to expand, their applications across diverse code intelligence domains are rapidly increasing. However, most existing datasets only evaluate limited application domains. To address this gap, we have developed a comprehensive code evaluation dataset FullStack Bench focusing on full-stack programming, which encompasses a wide range of application domains (e.g., basic programming, data analysis, software engineering, mathematics, and machine learning). Besides, to assess multilingual programming capabilities, in FullStack Bench, we design real-world instructions and corresponding unit test cases from 16 widely-used programming languages to reflect real-world usage scenarios rather than simple translations. Moreover, we also release an effective code sandbox execution tool (i.e., SandboxFusion) supporting various programming languages and packages to evaluate the performance of our FullStack Bench efficiently. Comprehensive experimental results on our FullStack Bench demonstrate the necessity and effectiveness of our FullStack Bench and SandboxFusion.
Joint Temporal Pooling for Improving Skeleton-based Action Recognition
Aug 18, 2024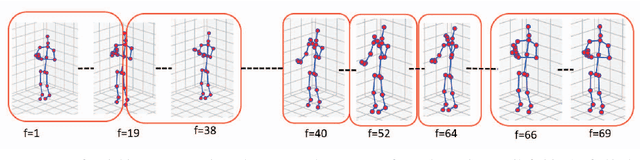
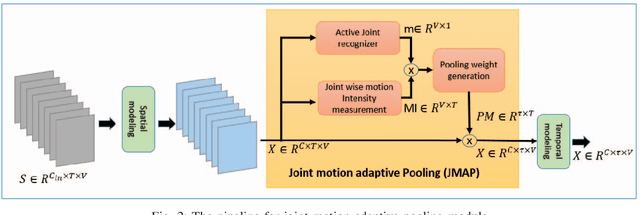
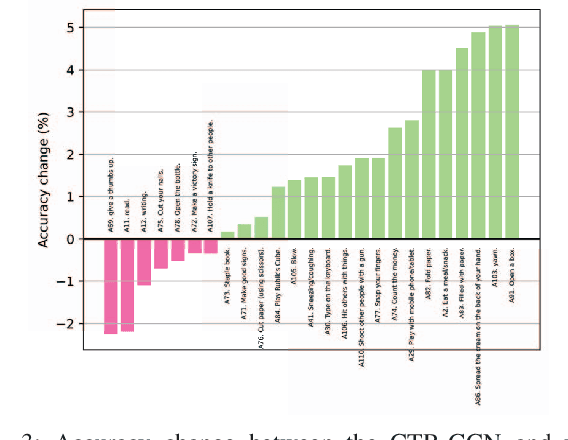
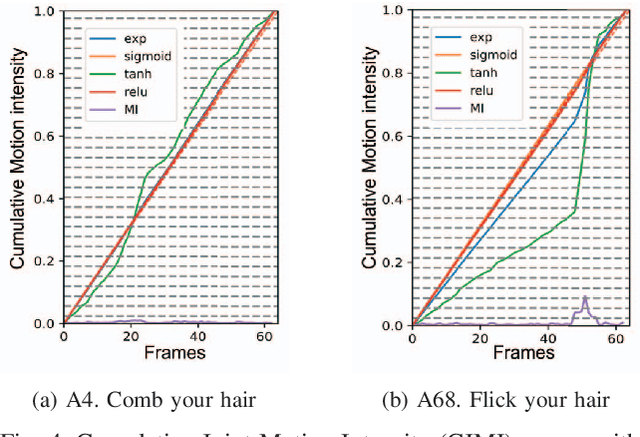
In skeleton-based human action recognition, temporal pooling is a critical step for capturing spatiotemporal relationship of joint dynamics. Conventional pooling methods overlook the preservation of motion information and treat each frame equally. However, in an action sequence, only a few segments of frames carry discriminative information related to the action. This paper presents a novel Joint Motion Adaptive Temporal Pooling (JMAP) method for improving skeleton-based action recognition. Two variants of JMAP, frame-wise pooling and joint-wise pooling, are introduced. The efficacy of JMAP has been validated through experiments on the popular NTU RGB+D 120 and PKU-MMD datasets.