 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatio-Temporal Joint Density Driven Learning for Skeleton-Based Action Recognition
May 29, 2025Traditional approaches in unsupervised or self supervised learning for skeleton-based action classification have concentrated predominantly on the dynamic aspects of skeletal sequences. Yet, the intricate interaction between the moving and static elements of the skeleton presents a rarely tapped discriminative potential for action classification. This paper introduces a novel measurement, referred to as spatial-temporal joint density (STJD), to quantify such interaction. Tracking the evolution of this density throughout an action can effectively identify a subset of discriminative moving and/or static joints termed "prime joints" to steer self-supervised learning. A new contrastive learning strategy named STJD-CL is proposed to align the representation of a skeleton sequence with that of its prime joints while simultaneously contrasting the representations of prime and nonprime joints. In addition, a method called STJD-MP is developed by integrating it with a reconstruction-based framework for more effective learning. Experimental evaluations on the NTU RGB+D 60, NTU RGB+D 120, and PKUMMD datasets in various downstream tasks demonstrate that the proposed STJD-CL and STJD-MP improved performance, particularly by 3.5 and 3.6 percentage points over the state-of-the-art contrastive methods on the NTU RGB+D 120 dataset using X-sub and X-set evaluations, respectively.
Joint Temporal Pooling for Improving Skeleton-based Action Recognition
Aug 18, 2024
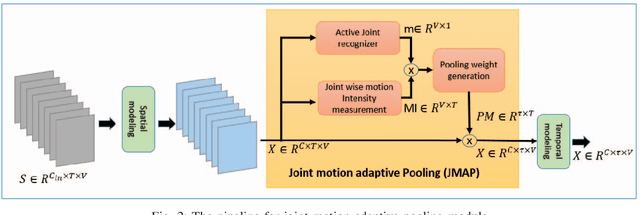
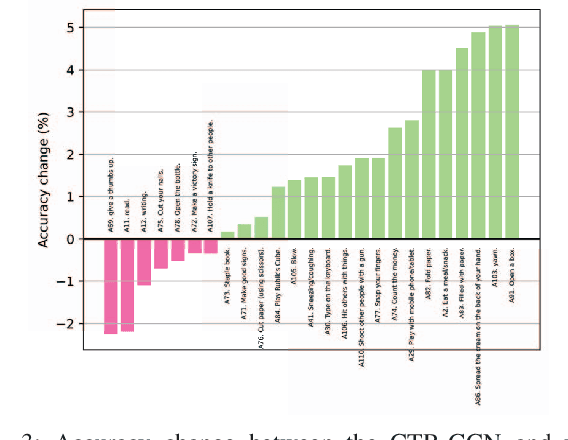
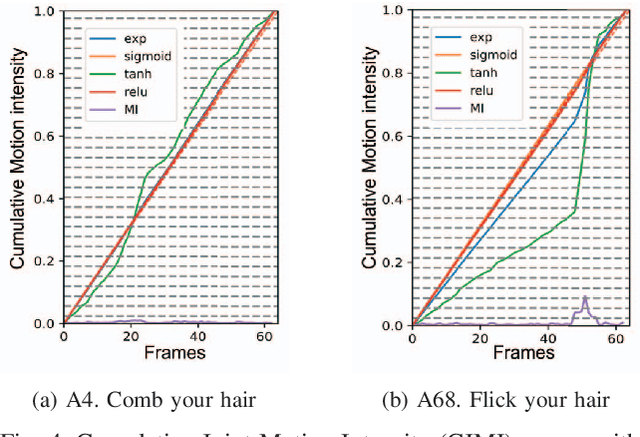
In skeleton-based human action recognition, temporal pooling is a critical step for capturing spatiotemporal relationship of joint dynamics. Conventional pooling methods overlook the preservation of motion information and treat each frame equally. However, in an action sequence, only a few segments of frames carry discriminative information related to the action. This paper presents a novel Joint Motion Adaptive Temporal Pooling (JMAP) method for improving skeleton-based action recognition. Two variants of JMAP, frame-wise pooling and joint-wise pooling, are introduced. The efficacy of JMAP has been validated through experiments on the popular NTU RGB+D 120 and PKU-MMD datasets.
Unsupervised Domain Expansion from Multiple Sources
May 26, 2020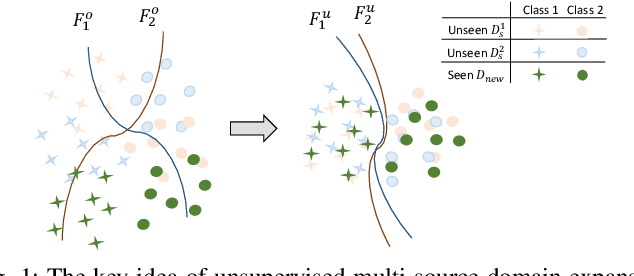
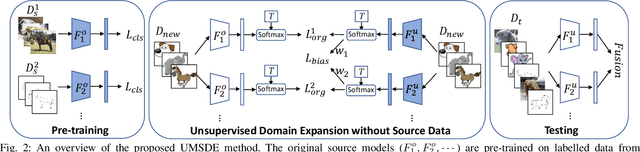
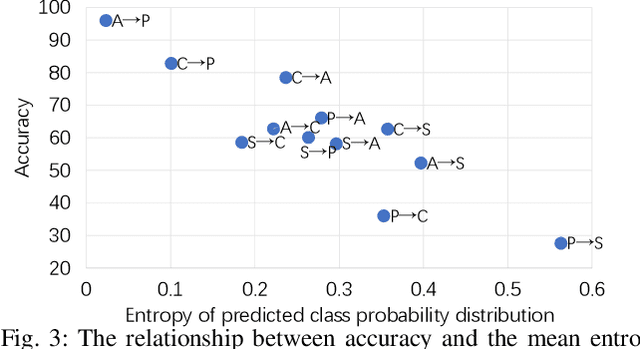
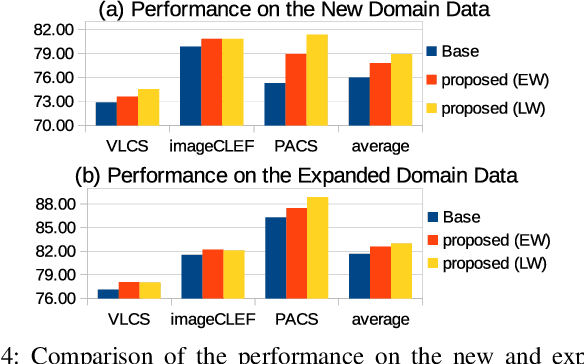
Given an existing system learned from previous source domains, it is desirable to adapt the system to new domains without accessing and forgetting all the previous domains in some applications. This problem is known as domain expansion. Unlike traditional domain adaptation in which the target domain is the domain defined by new data, in domain expansion the target domain is formed jointly by the source domains and the new domain (hence, domain expansion) and the label function to be learned must work for the expanded domain. Specifically, this paper presents a method for unsupervised multi-source domain expansion (UMSDE) where only the pre-learned models of the source domains and unlabelled new domain data are available. We propose to use the predicted class probability of the unlabelled data in the new domain produced by different source models to jointly mitigate the biases among domains, exploit the discriminative information in the new domain, and preserve the performance in the source domains. Experimental results on the VLCS, ImageCLEF_DA and PACS datasets have verified the effectiveness of the proposed method.
RGB-D-based Human Motion Recognition with Deep Learning: A Survey
Apr 24, 2018



Human motion recognition is one of the most important branches of human-centered research activities. In recent years, motion recognition based on RGB-D data has attracted much attention. Along with the development in artificial intelligence, deep learning techniques have gained remarkable success in computer vision. In particular, convolutional neural networks (CNN) have achieved great success for image-based tasks, and recurrent neural networks (RNN) are renowned for sequence-based problems. Specifically, deep learning methods based on the CNN and RNN architectures have been adopted for motion recognition using RGB-D data. In this paper, a detailed overview of recent advances in RGB-D-based motion recognition is presented. The reviewed methods are broadly categorized into four groups, depending on the modality adopted for recognition: RGB-based, depth-based, skeleton-based and RGB+D-based. As a survey focused on the application of deep learning to RGB-D-based motion recognition, we explicitly discuss the advantages and limitations of existing techniques. Particularly, we highlighted the methods of encoding spatial-temporal-structural information inherent in video sequence, and discuss potential directions for future research.
Depth Pooling Based Large-scale 3D Action Recognition with Convolutional Neural Networks
Apr 17, 2018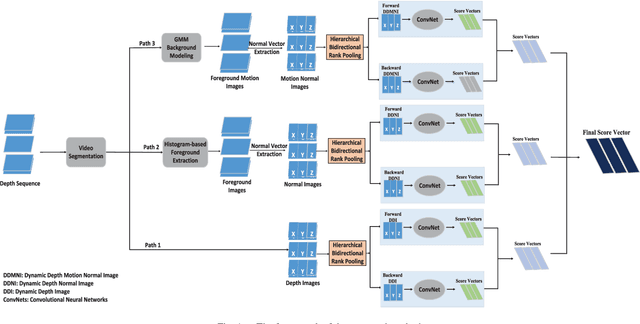
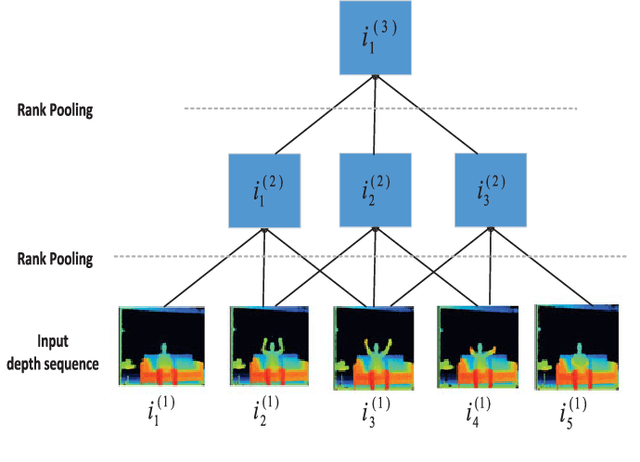
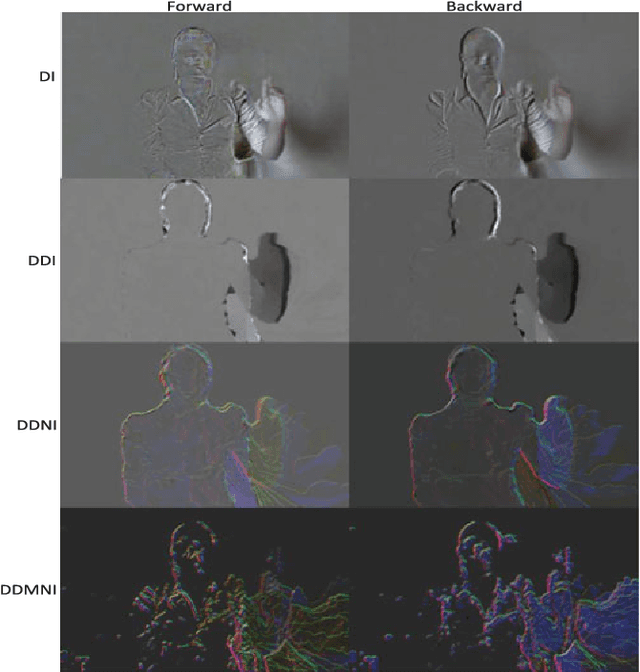
This paper proposes three simple, compact yet effective representations of depth sequences, referred to respectively as Dynamic Depth Images (DDI), Dynamic Depth Normal Images (DDNI) and Dynamic Depth Motion Normal Images (DDMNI), for both isolated and continuous action recognition. These dynamic images are constructed from a segmented sequence of depth maps using hierarchical bidirectional rank pooling to effectively capture the spatial-temporal information. Specifically, DDI exploits the dynamics of postures over time and DDNI and DDMNI exploit the 3D structural information captured by depth maps. Upon the proposed representations, a ConvNet based method is developed for action recognition. The image-based representations enable us to fine-tune the existing Convolutional Neural Network (ConvNet) models trained on image data without training a large number of parameters from scratch. The proposed method achieved the state-of-art results on three large datasets, namely, the Large-scale Continuous Gesture Recognition Dataset (means Jaccard index 0.4109), the Large-scale Isolated Gesture Recognition Dataset (59.21%), and the NTU RGB+D Dataset (87.08% cross-subject and 84.22% cross-view) even though only the depth modality was used.
Importance Weighted Adversarial Nets for Partial Domain Adaptation
Mar 28, 2018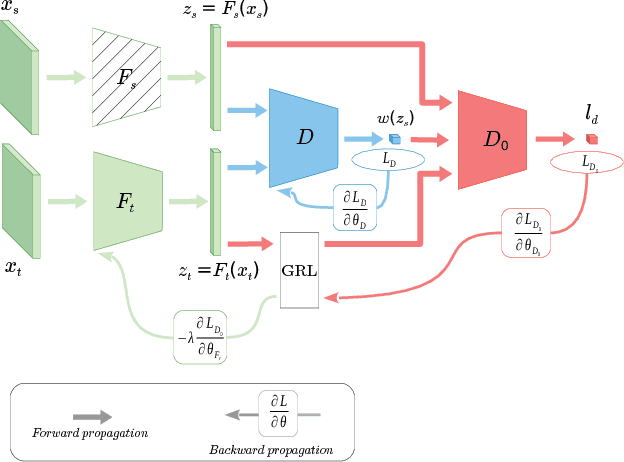
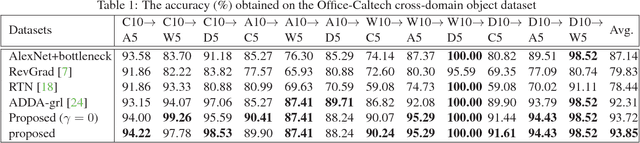

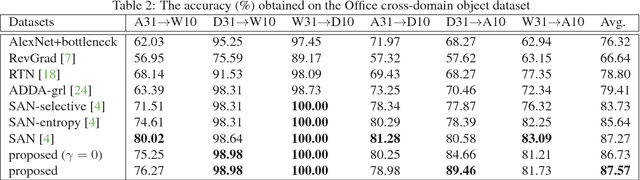
This paper proposes an importance weighted adversarial nets-based method for unsupervised domain adaptation, specific for partial domain adaptation where the target domain has less number of classes compared to the source domain. Previous domain adaptation methods generally assume the identical label spaces, such that reducing the distribution divergence leads to feasible knowledge transfer. However, such an assumption is no longer valid in a more realistic scenario that requires adaptation from a larger and more diverse source domain to a smaller target domain with less number of classes. This paper extends the adversarial nets-based domain adaptation and proposes a novel adversarial nets-based partial domain adaptation method to identify the source samples that are potentially from the outlier classes and, at the same time, reduce the shift of shared classes between domains.
Unsupervised Domain Adaptation: A Multi-task Learning-based Method
Mar 25, 2018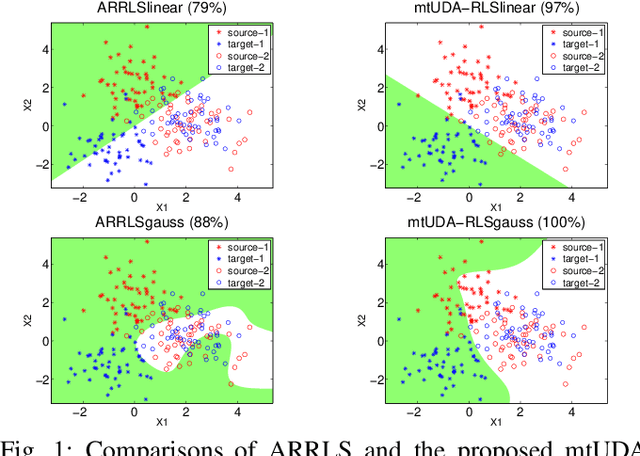
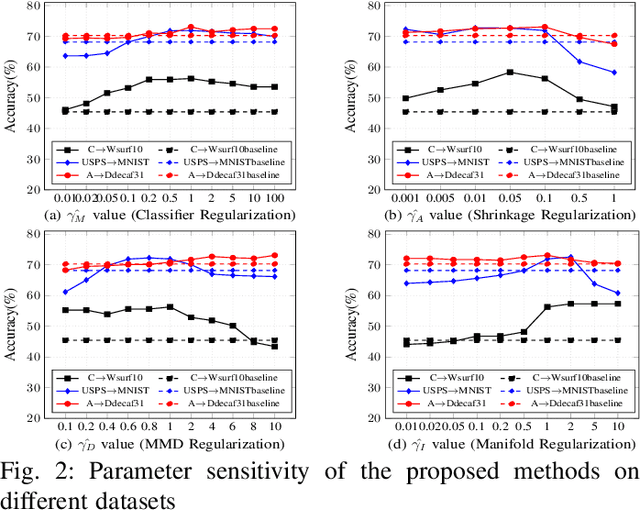

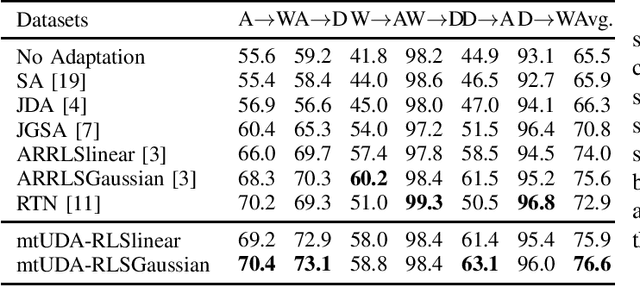
This paper presents a novel multi-task learning-based method for unsupervised domain adaptation. Specifically, the source and target domain classifiers are jointly learned by considering the geometry of target domain and the divergence between the source and target domains based on the concept of multi-task learning. Two novel algorithms are proposed upon the method using Regularized Least Squares and Support Vector Machines respectively. Experiments on both synthetic and real world cross domain recognition tasks have shown that the proposed methods outperform several state-of-the-art domain adaptation methods.
Cooperative Training of Deep Aggregation Networks for RGB-D Action Recognition
Dec 05, 2017
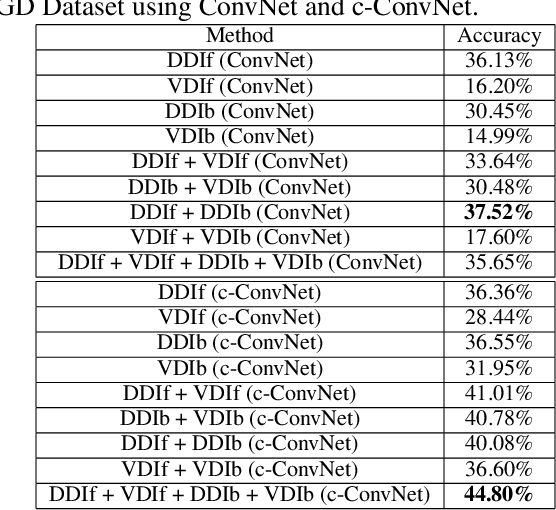


A novel deep neural network training paradigm that exploits the conjoint information in multiple heterogeneous sources is proposed. Specifically, in a RGB-D based action recognition task, it cooperatively trains a single convolutional neural network (named c-ConvNet) on both RGB visual features and depth features, and deeply aggregates the two kinds of features for action recognition. Differently from the conventional ConvNet that learns the deep separable features for homogeneous modality-based classification with only one softmax loss function, the c-ConvNet enhances the discriminative power of the deeply learned features and weakens the undesired modality discrepancy by jointly optimizing a ranking loss and a softmax loss for both homogeneous and heterogeneous modalities. The ranking loss consists of intra-modality and cross-modality triplet losses, and it reduces both the intra-modality and cross-modality feature variations. Furthermore, the correlations between RGB and depth data are embedded in the c-ConvNet, and can be retrieved by either of the modalities and contribute to the recognition in the case even only one of the modalities is available. The proposed method was extensively evaluated on two large RGB-D action recognition datasets, ChaLearn LAP IsoGD and NTU RGB+D datasets, and one small dataset, SYSU 3D HOI, and achieved state-of-the-art results.
Transfer Learning for Cross-Dataset Recognition: A Survey
Jul 06, 2017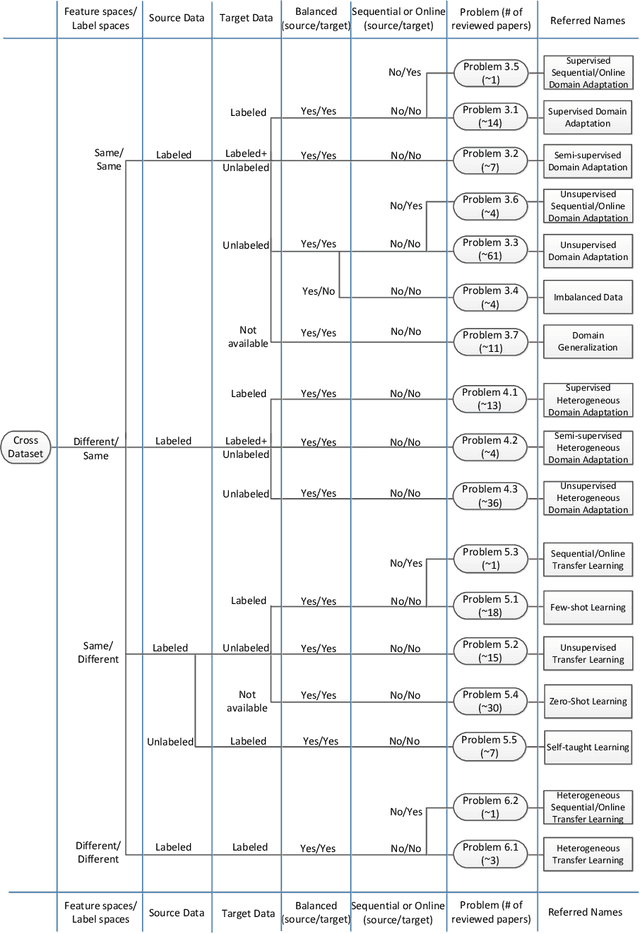
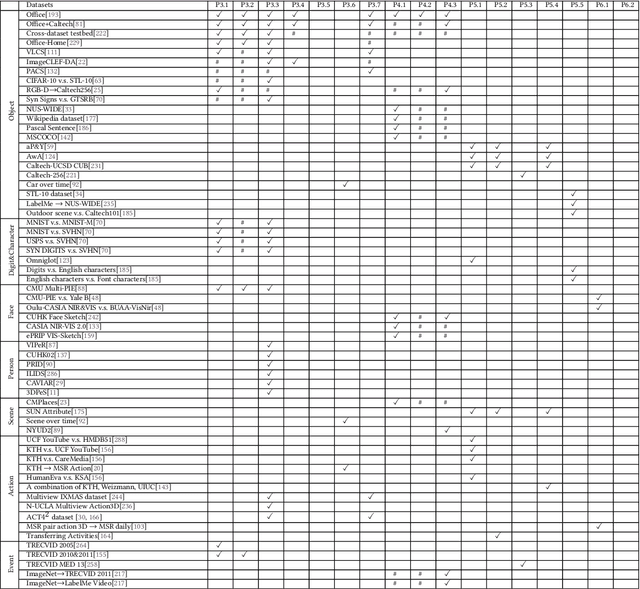


This paper summarises and analyses the cross-dataset recognition transfer learning techniques with the emphasis on what kinds of methods can be used when the available source and target data are presented in different forms for boosting the target task. This paper for the first time summarises several transferring criteria in details from the concept level, which are the key bases to guide what kind of knowledge to transfer between datasets. In addition, a taxonomy of cross-dataset scenarios and problems is proposed according the properties of data that define how different datasets are diverged, thereby review the recent advances on each specific problem under different scenarios. Moreover, some real world applications and corresponding commonly used benchmarks of cross-dataset recognition are reviewed. Lastly, several future directions are identified.
Joint Geometrical and Statistical Alignment for Visual Domain Adaptation
May 16, 2017



This paper presents a novel unsupervised domain adaptation method for cross-domain visual recognition. We propose a unified framework that reduces the shift between domains both statistically and geometrically, referred to as Joint Geometrical and Statistical Alignment (JGSA). Specifically, we learn two coupled projections that project the source domain and target domain data into low dimensional subspaces where the geometrical shift and distribution shift are reduced simultaneously. The objective function can be solved efficiently in a closed form. Extensive experiments have verified that the proposed method significantly outperforms several state-of-the-art domain adaptation methods on a synthetic dataset and three different real world cross-domain visual recognition tasks.