 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning Based Adaptive Joint mmWave Beam Alignment
Jan 24, 2024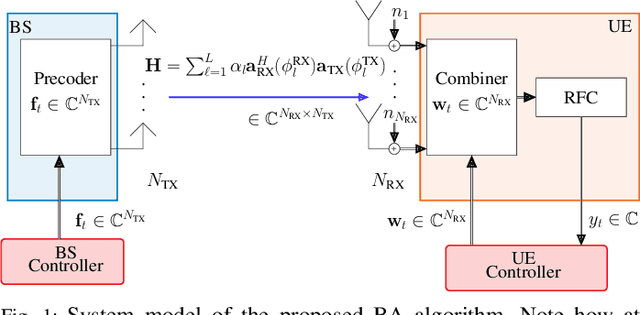
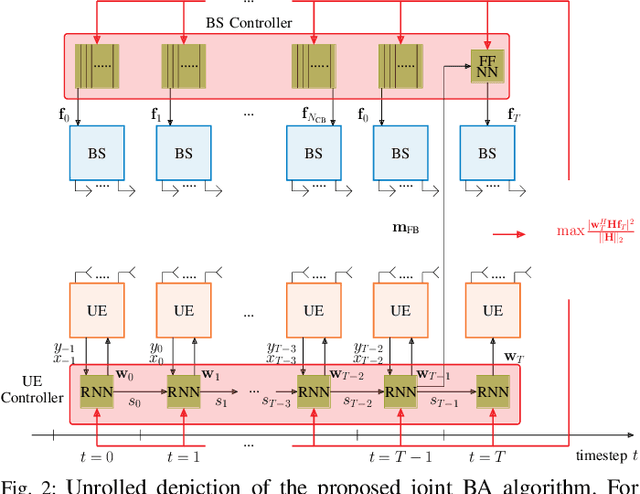
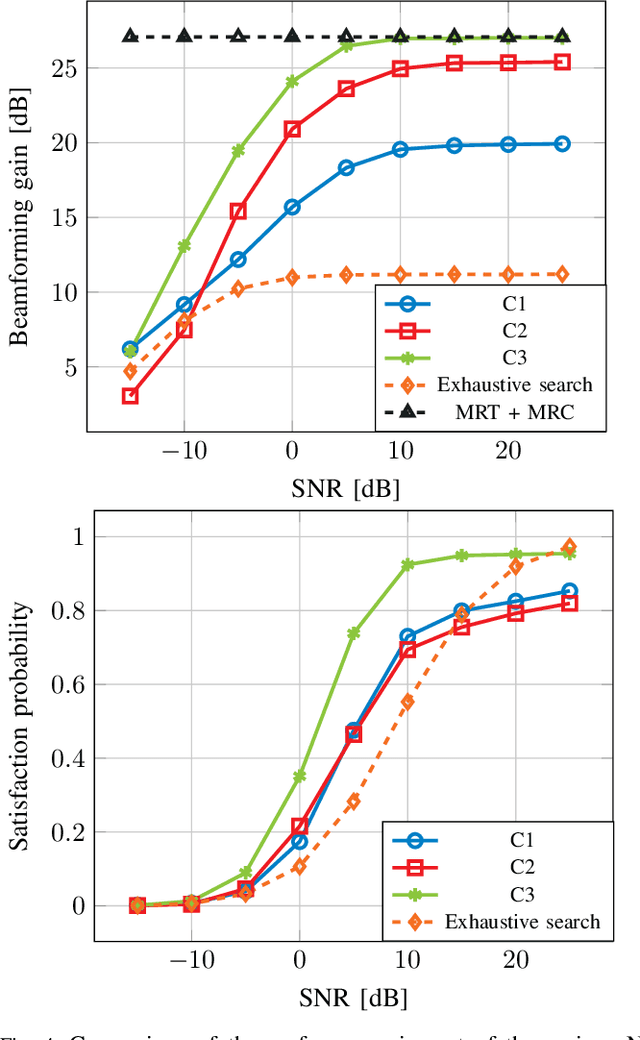
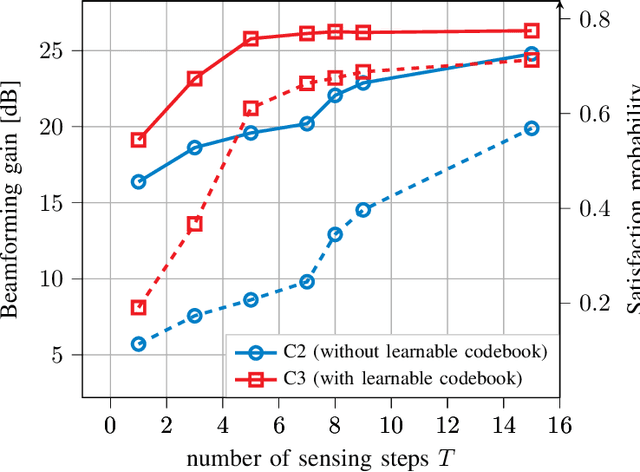
The challenging propagation environment, combined with the hardware limitations of mmWave systems, gives rise to the need for accurate initial access beam alignment strategies with low latency and high achievable beamforming gain. Much of the recent work in this area either focuses on one-sided beam alignment, or, joint beam alignment methods where both sides of the link perform a sequence of fixed channel probing steps. Codebook-based non-adaptive beam alignment schemes have the potential to allow multiple user equipment (UE) to perform initial access beam alignment in parallel whereas adaptive schemes are favourable in achievable beamforming gain. This work introduces a novel deep learning based joint beam alignment scheme that aims to combine the benefits of adaptive, codebook-free beam alignment at the UE side with the advantages of a codebook-sweep based scheme at the base station. The proposed end-to-end trainable scheme is compatible with current cellular standard signaling and can be readily integrated into the standard without requiring significant changes to it. Extensive simulations demonstrate superior performance of the proposed approach over purely codebook-based ones.
Deep Reinforcement Learning for mmWave Initial Beam Alignment
Feb 17, 2023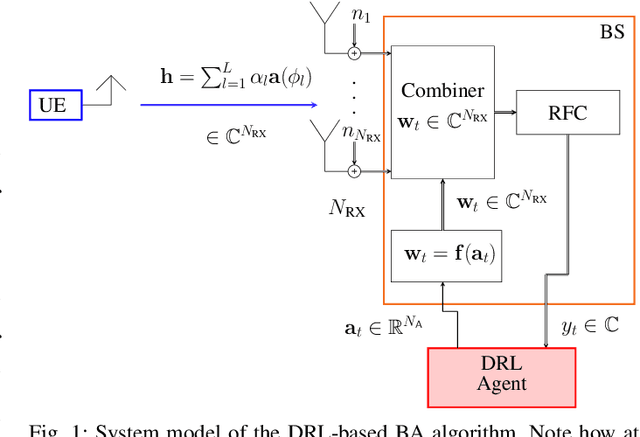
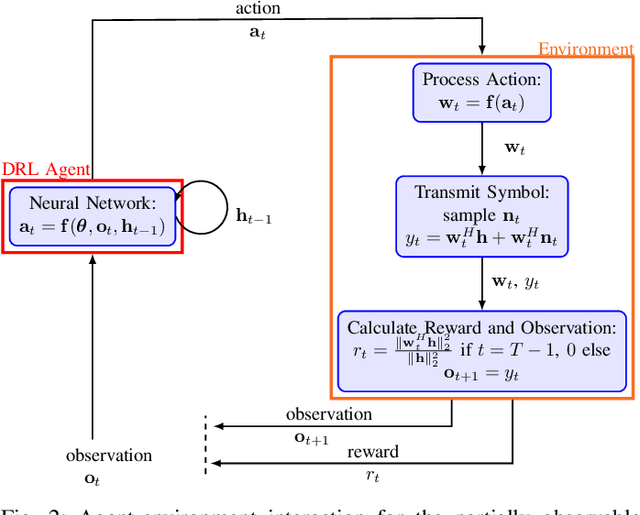
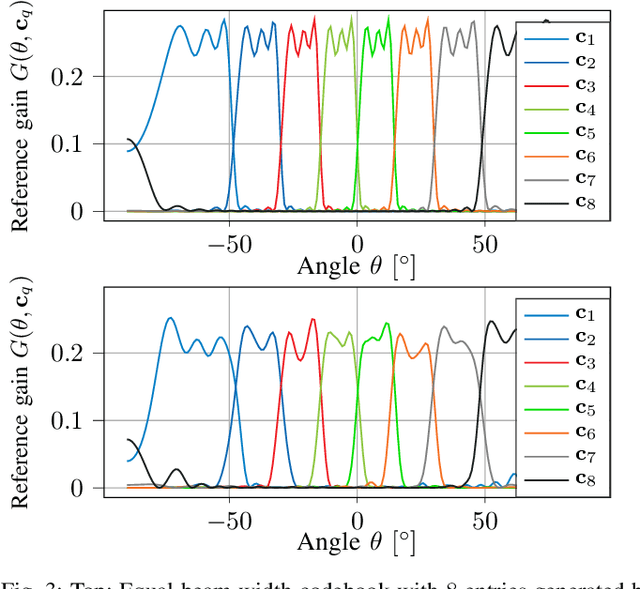
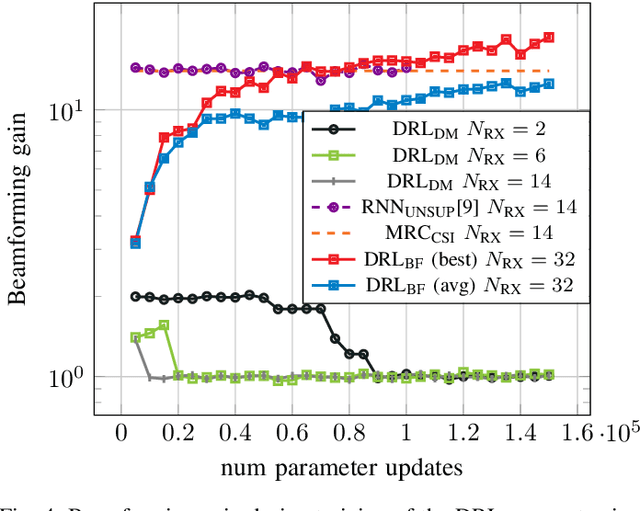
We investigate the applicability of deep reinforcement learning algorithms to the adaptive initial access beam alignment problem for mmWave communications using the state-of-the-art proximal policy optimization algorithm as an example. In comparison to recent unsupervised learning based approaches developed to tackle this problem, deep reinforcement learning has the potential to address a new and wider range of applications, since, in principle, no (differentiable) model of the channel and/or the whole system is required for training, and only agent-environment interactions are necessary to learn an algorithm (be it online or using a recorded dataset). We show that, although the chosen off-the-shelf deep reinforcement learning agent fails to perform well when trained on realistic problem sizes, introducing action space shaping in the form of beamforming modules vastly improves the performance, without sacrificing much generalizability. Using this add-on, the agent is able to deliver competitive performance to various state-of-the-art methods on simulated environments, even under realistic problem sizes. This demonstrates that through well-directed modification, deep reinforcement learning may have a chance to compete with other approaches in this area, opening up many straightforward extensions to other/similar scenarios.
Deep Learning for Uplink CSI-based Downlink Precoding in FDD massive MIMO Evaluated on Indoor Measurements
Sep 22, 2022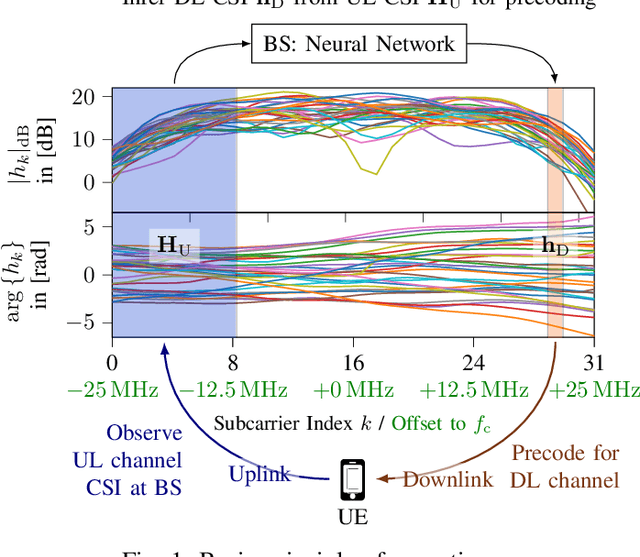
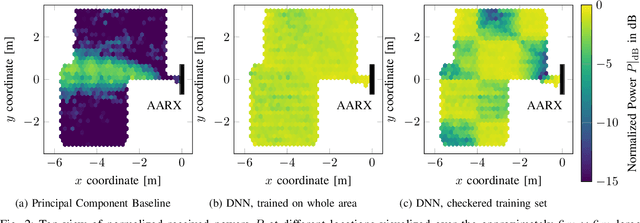
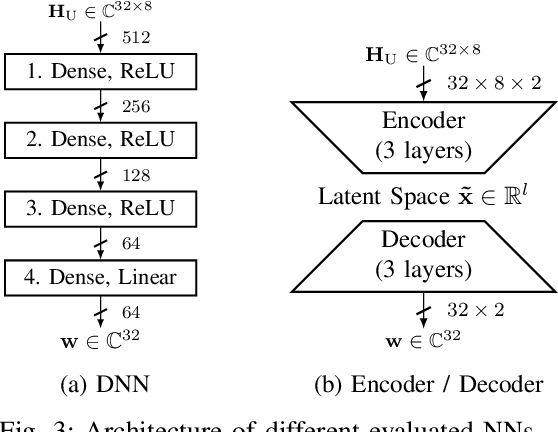
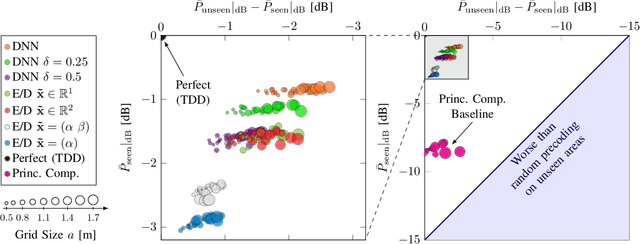
When operating massive multiple-input multiple-output (MIMO) systems with uplink (UL) and downlink (DL) channels at different frequencies (frequency division duplex (FDD) operation), acquisition of channel state information (CSI) for downlink precoding is a major challenge. Since, barring transceiver impairments, both UL and DL CSI are determined by the physical environment surrounding transmitter and receiver, it stands to reason that, for a static environment, a mapping from UL CSI to DL CSI may exist. First, we propose to use various neural network (NN)-based approaches that learn this mapping and provide baselines using classical signal processing. Second, we introduce a scheme to evaluate the performance and quality of generalization of all approaches, distinguishing between known and previously unseen physical locations. Third, we evaluate all approaches on a real-world indoor dataset collected with a 32-antenna channel sounder.
Introducing $γ$-lifting for Learning Nonlinear Pulse Shaping in Coherent Optical Communication
Jul 13, 2022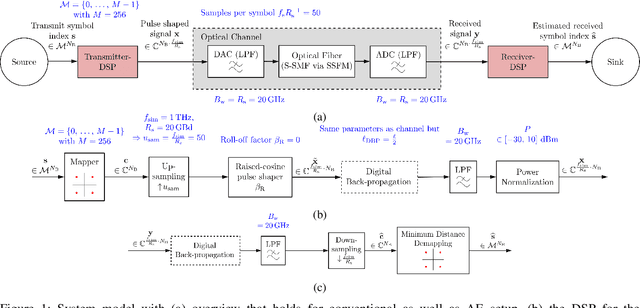
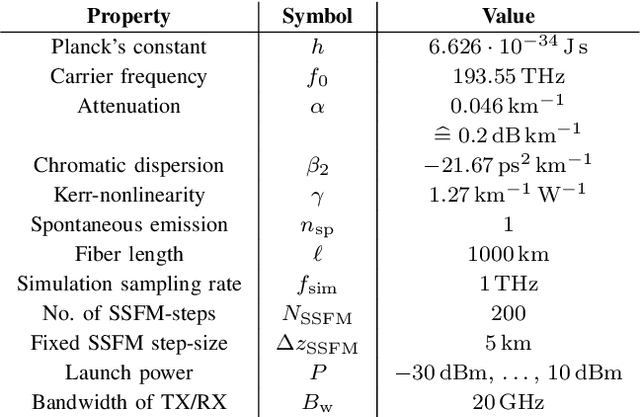
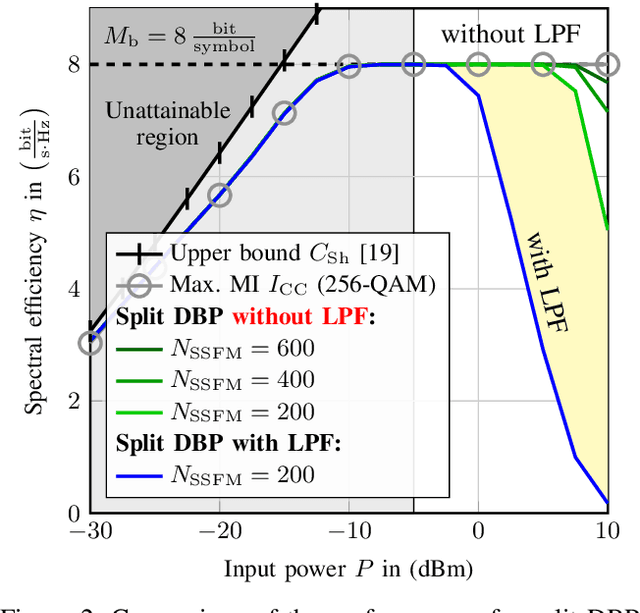
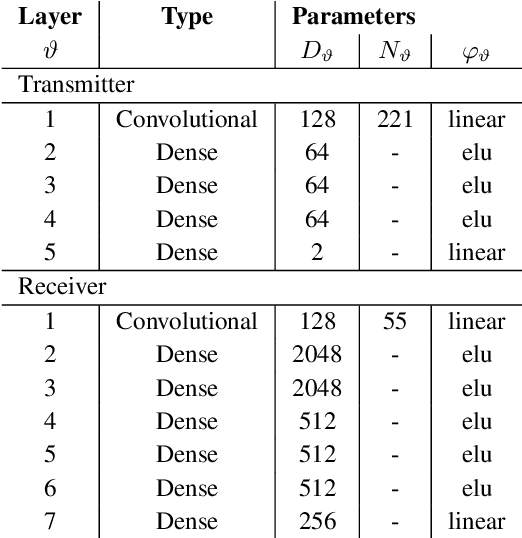
Pulse shaping for coherent optical fiber communication has been an active area of research for the past decade. Most of the early schemes are based on classic Nyquist pulse shaping that was originally intended for linear channels. The best known classic scheme, the split digital back-propagation (DBP), uses joint pre-distortion and post equalization and hence, a nonlinear transmitter (TX); it, however, suffers from spectral broadening on the fiber due to the Kerr-effect. With the advent of deep learning in communications, it has been realized that an Autoencoder can learn to communicate efficiently over the optical fiber channel, jointly optimizing geometric constellations and pulse shaping - while also taking into account linear and nonlinear impairments such as chromatic dispersion and Kerr-nonlinearity. E.g., arXiv:2006.15027 shows how an Autoencoder can learn to mitigate spectral broadening due to the Kerr-effect using a trainable linear TX. In this paper, we extend this linear architectural template to a scalable nonlinear pulse shaping consisting of a Convolutional Neural Network at both transmitter and receiver. By introducing a novel $\gamma$-lifting training procedure tailored to the nonlinear optical fiber channel, we achieve stable Autoencoder convergence to pulse shapes reaching information rates outperforming the classic split DBP reference at high input powers.
Learning Joint Detection, Equalization and Decoding for Short-Packet Communications
Jul 12, 2022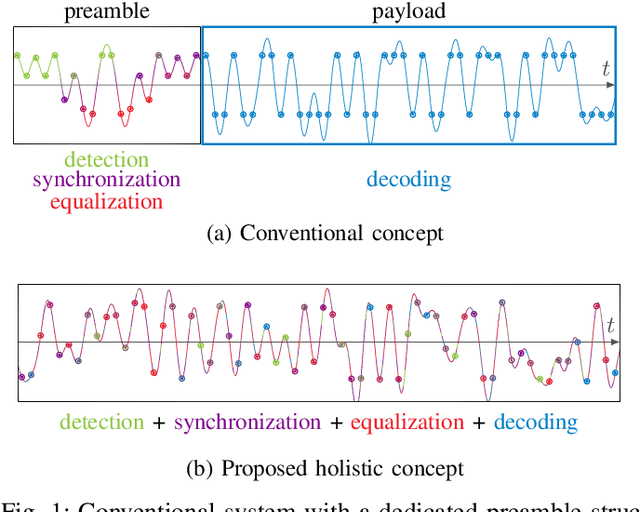
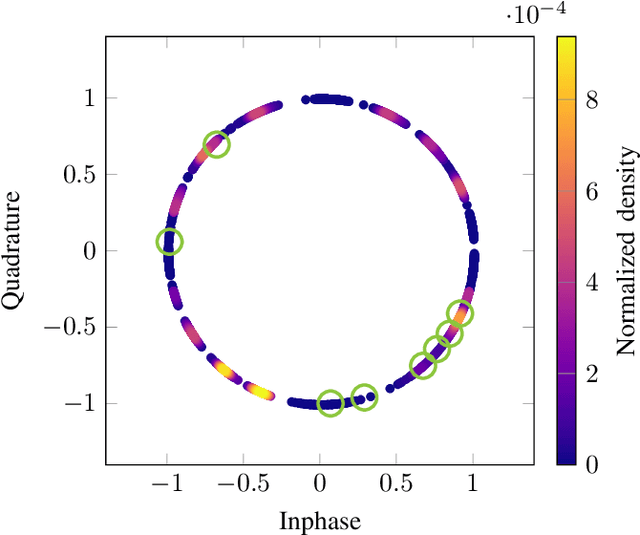
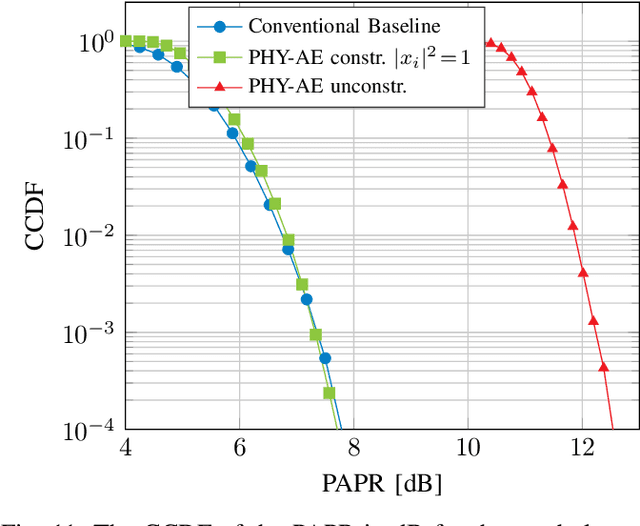
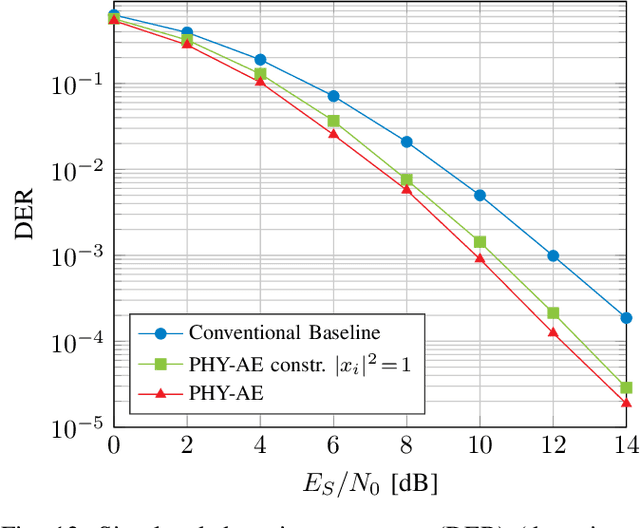
We propose and practically demonstrate a joint detection and decoding scheme for short-packet wireless communications in scenarios that require to first detect the presence of a message before actually decoding it. For this, we extend the recently proposed serial Turbo-autoencoder neural network (NN) architecture and train it to find short messages that can be, all "at once", detected, synchronized, equalized and decoded when sent over an unsynchronized channel with memory. The conceptional advantage of the proposed system stems from a holistic message structure with superimposed pilots for joint detection and decoding without the need of relying on a dedicated preamble. This results not only in higher spectral efficiency, but also translates into the possibility of shorter messages compared to using a dedicated preamble. We compare the detection error rate (DER), bit error rate (BER) and block error rate (BLER) performance of the proposed system with a hand-crafted state-of-the-art conventional baseline and our simulations show a significant advantage of the proposed autoencoder-based system over the conventional baseline in every scenario up to messages conveying k = 96 information bits. Finally, we practically evaluate and confirm the improved performance of the proposed system over-the-air (OTA) using a software-defined radio (SDR)-based measurement testbed.
A Distributed Massive MIMO Channel Sounder for "Big CSI Data"-driven Machine Learning
Jun 30, 2022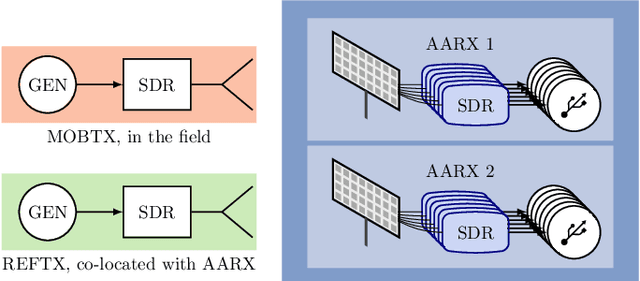

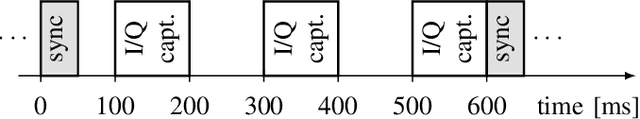
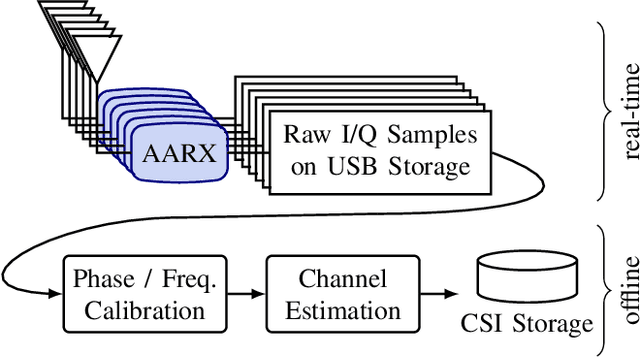
A distributed massive MIMO channel sounder for acquiring large CSI datasets, dubbed DICHASUS, is presented. The measured data has potential applications in the study of various machine learning algorithms for user localization, JCAS, channel charting, enabling massive MIMO in FDD operation, and many others. The proposed channel sounder architecture is distinct from similar previous designs in that each individual single-antenna receiver is completely autonomous, enabling arbitrary, spatially distributed antenna deployments, and offering virtually unlimited scalability in the number of antennas. Optionally, extracted channel coefficient vectors can be tagged with ground truth position data, obtained either through a GNSS receiver (for outdoor operation) or through various indoor positioning techniques.
Improving Triplet-Based Channel Charting on Distributed Massive MIMO Measurements
Jun 20, 2022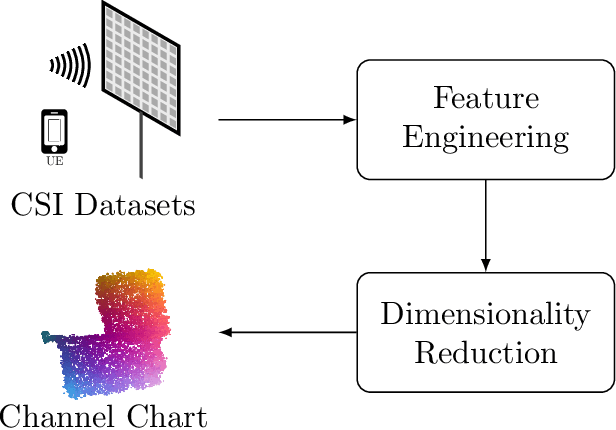
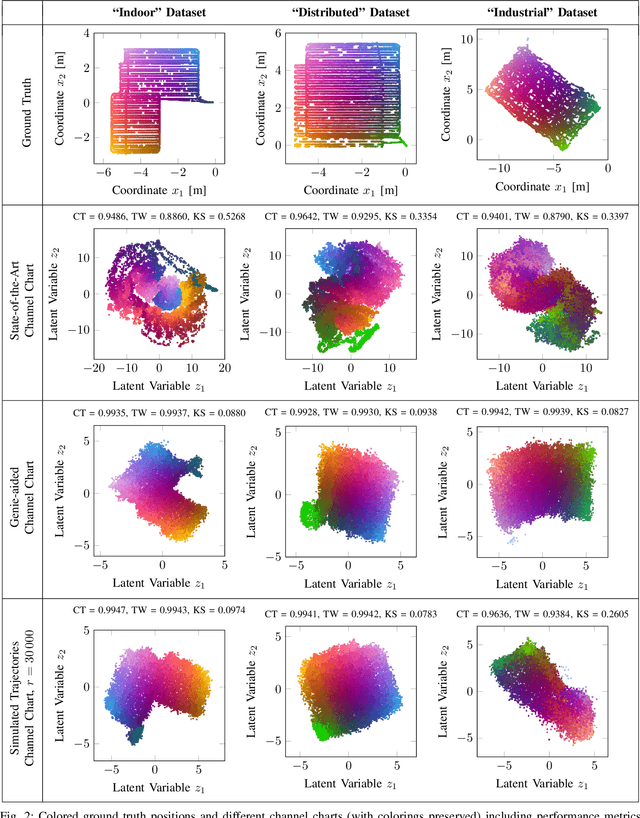
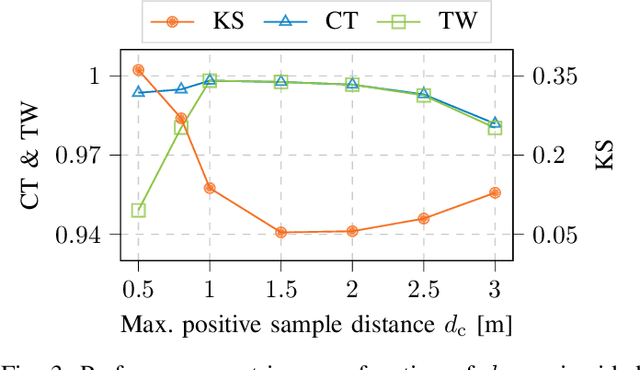
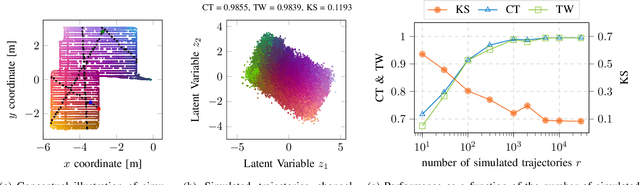
The objective of channel charting is to learn a virtual map of the radio environment from high-dimensional CSI that is acquired by a multi-antenna wireless system. Since, in static environments, CSI is a function of the transmitter location, a mapping from CSI to channel chart coordinates can be learned in a self-supervised manner using dimensionality reduction techniques. The state-of-the-art triplet-based approach is evaluated on multiple datasets measured by a distributed massive MIMO channel sounder, with both co-located and distributed antenna setups. The importance of suitable triplet selection is investigated by comparing results to channel charts learned from a genie-aided triplet generator and learned from triplets on simulated trajectories through measured data. Finally, the transferability of learned forward charting functions to similar, but different radio environments is explored.
Adaptive Neural Network-based OFDM Receivers
Mar 25, 2022
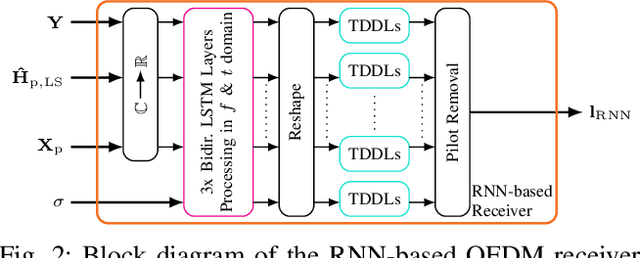
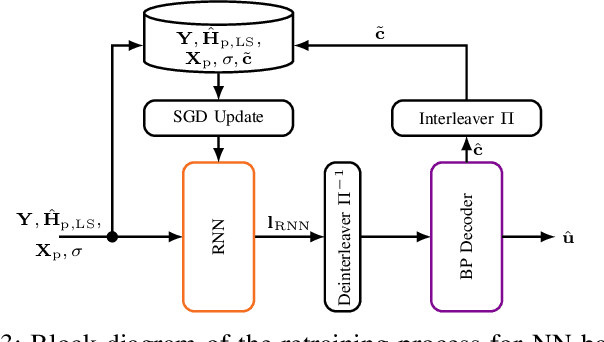
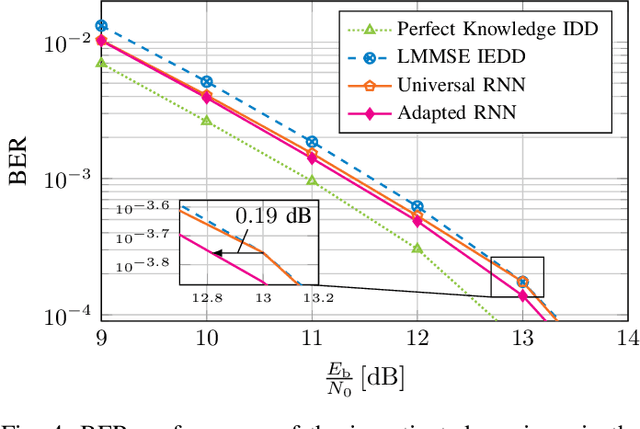
We propose and examine the idea of continuously adapting state-of-the-art neural network (NN)-based orthogonal frequency division multiplex (OFDM) receivers to current channel conditions. This online adaptation via retraining is mainly motivated by two reasons: First, receiver design typically focuses on the universal optimal performance for a wide range of possible channel realizations. However, in actual applications and within short time intervals, only a subset of these channel parameters is likely to occur, as macro parameters, e.g., the maximum channel delay, can assumed to be static. Second, in-the-field alterations like temporal interferences or other conditions out of the originally intended specifications can occur on a practical (real-world) transmission. While conventional (filter-based) systems would require reconfiguration or additional signal processing to cope with these unforeseen conditions, NN-based receivers can learn to mitigate previously unseen effects even after their deployment. For this, we showcase on-the-fly adaption to current channel conditions and temporal alterations solely based on recovered labels from an outer forward error correction (FEC) code without any additional piloting overhead. To underline the flexibility of the proposed adaptive training, we showcase substantial gains for scenarios with static channel macro parameters, for out-ofspecification usage and for interference compensation.
Towards Practical Indoor Positioning Based on Massive MIMO Systems
May 28, 2019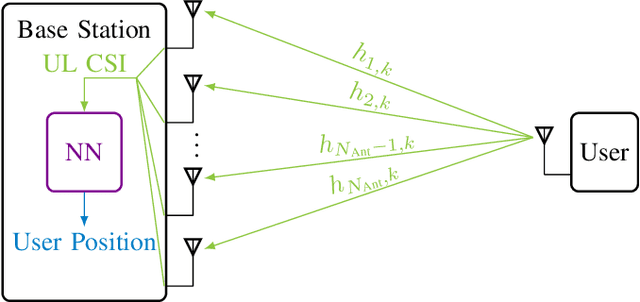
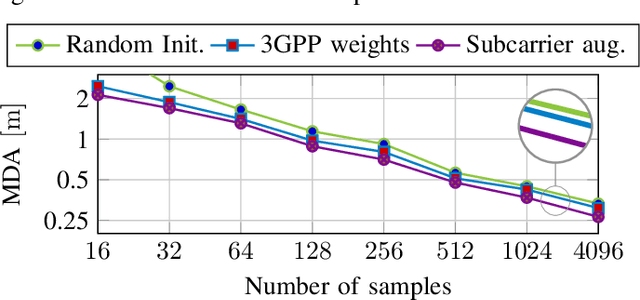
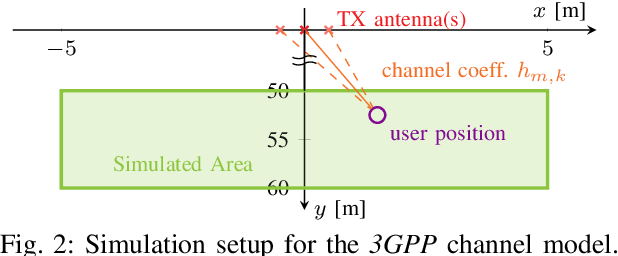
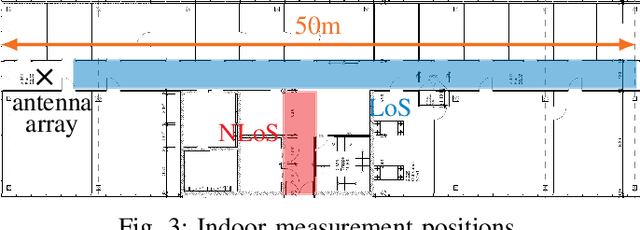
We showcase the practicability of an indoor positioning system (IPS) solely based on Neural Networks (NNs) and the channel state information (CSI) of a (Massive) multiple-input multiple-output (MIMO) communication system, i.e., only build on the basis of data that is already existent in today's systems. As such our IPS system promises both, a good accuracy without the need of any additional protocol/signaling overhead for the user localization task. In particular, we propose a tailored NN structure with an additional phase branch as feature extractor and (compared to previous results) a significantly reduced amount of trainable parameters, leading to a minimization of the amount of required training data. We provide actual measurements for indoor scenarios with up to 64 antennas covering a large area of 80m2. In the second part, several robustness investigations for real-measurements are conducted, i.e., once trained, we analyze the recall accuracy over a time-period of several days. Further, we analyze the impact of pedestrians walking in-between the measurements and show that finetuning and pre-training of the NN helps to mitigate effects of hardware drifts and alterations in the propagation environment over time. This reduces the amount of required training samples at equal precision and, thereby, decreases the effort of the costly training data acquisition
On Recurrent Neural Networks for Sequence-based Processing in Communications
May 24, 2019

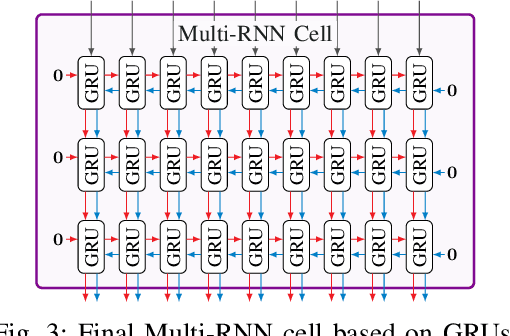
In this work, we analyze the capabilities and practical limitations of neural networks (NNs) for sequence-based signal processing which can be seen as an omnipresent property in almost any modern communication systems. In particular, we train multiple state-of-the-art recurrent neural network (RNN) structures to learn how to decode convolutional codes allowing a clear benchmarking with the corresponding maximum likelihood (ML) Viterbi decoder. We examine the decoding performance for various kinds of NN architectures, beginning with classical types like feedforward layers and gated recurrent unit (GRU)-layers, up to more recently introduced architectures such as temporal convolutional networks (TCNs) and differentiable neural computers (DNCs) with external memory. As a key limitation, it turns out that the training complexity increases exponentially with the length of the encoding memory $\nu$ and, thus, practically limits the achievable bit error rate (BER) performance. To overcome this limitation, we introduce a new training-method by gradually increasing the number of ones within the training sequences, i.e., we constrain the amount of possible training sequences in the beginning until first convergence. By consecutively adding more and more possible sequences to the training set, we finally achieve training success in cases that did not converge before via naive training. Further, we show that our network can learn to jointly detect and decode a quadrature phase shift keying (QPSK) modulated code with sub-optimal (anti-Gray) labeling in one-shot at a performance that would require iterations between demapper and decoder in classic detection schemes.