 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Reinforcement Learning for mmWave Initial Beam Alignment
Paper and Code
Feb 17, 2023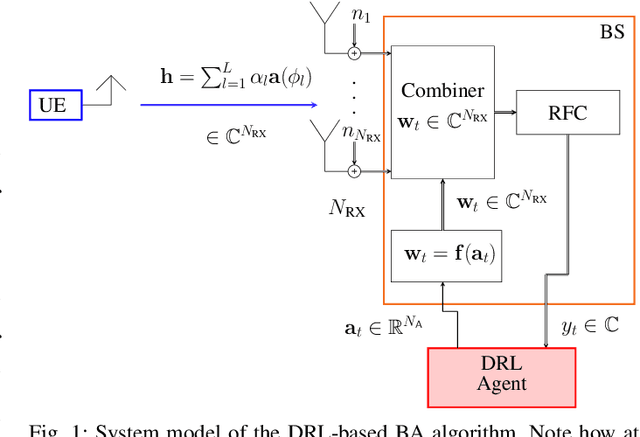
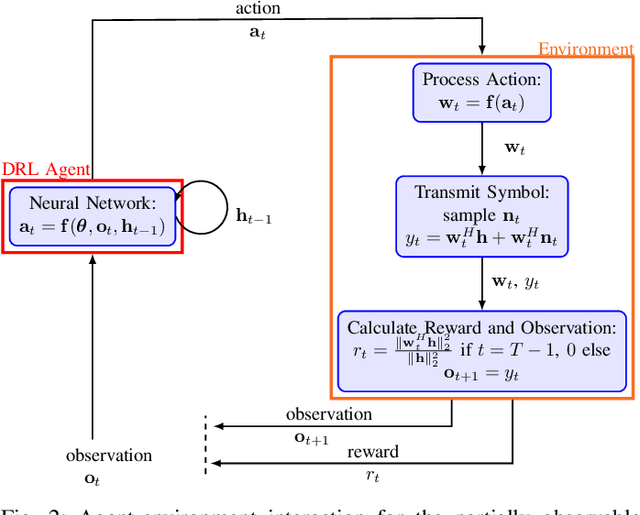
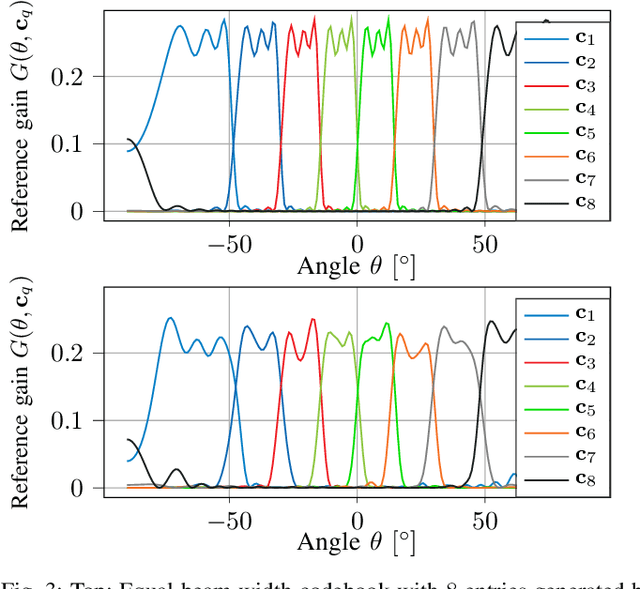
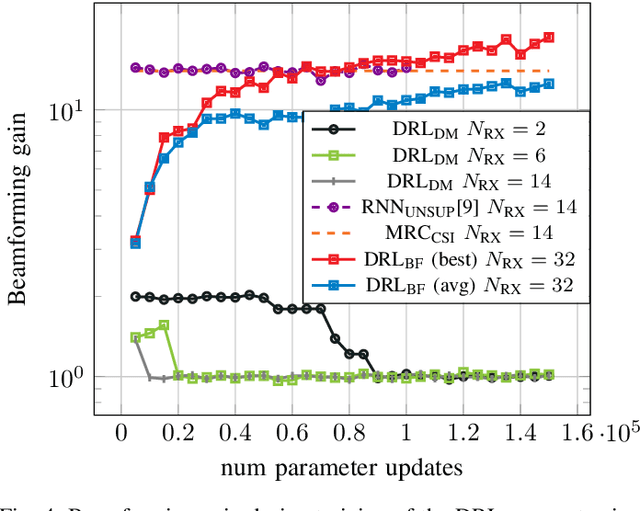
We investigate the applicability of deep reinforcement learning algorithms to the adaptive initial access beam alignment problem for mmWave communications using the state-of-the-art proximal policy optimization algorithm as an example. In comparison to recent unsupervised learning based approaches developed to tackle this problem, deep reinforcement learning has the potential to address a new and wider range of applications, since, in principle, no (differentiable) model of the channel and/or the whole system is required for training, and only agent-environment interactions are necessary to learn an algorithm (be it online or using a recorded dataset). We show that, although the chosen off-the-shelf deep reinforcement learning agent fails to perform well when trained on realistic problem sizes, introducing action space shaping in the form of beamforming modules vastly improves the performance, without sacrificing much generalizability. Using this add-on, the agent is able to deliver competitive performance to various state-of-the-art methods on simulated environments, even under realistic problem sizes. This demonstrates that through well-directed modification, deep reinforcement learning may have a chance to compete with other approaches in this area, opening up many straightforward extensions to other/similar scenarios.