 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Unified Coding Scheme for 6G
Mar 24, 2026The growing demand for higher data rates necessitates continuous innovations in wireless communication systems, particularly with the emergence of 6G. Channel coding plays a crucial role in this evolution. In 5G systems, rate-adaptive raptor-like quasi-cyclic irregular low-density parity-check codes are used for the data link, while polar codes with successive cancellation list decoding handle short messages on the synchronization channel. However, to meet the stringent requirements of future 6G systems, a versatile and unified coding scheme should be developed - one that offers competitive error-correcting performance alongside low complexity encoding and decoding schemes that enable energy-efficient hardware implementations. This white paper outlines the vision for such a unified coding scheme. We explore various 6G communication scenarios that pose new challenges to channel coding and provide a first analysis of potential solutions.
Graph Neural Network-based Joint Equalization and Decoding
Jan 29, 2024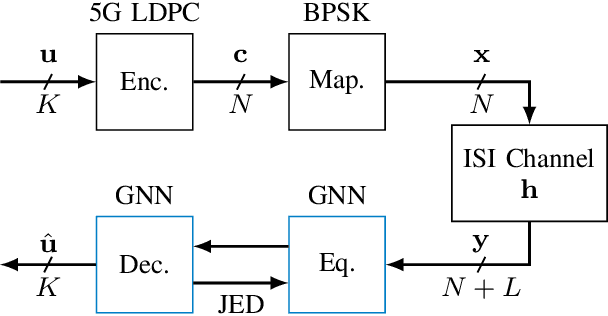
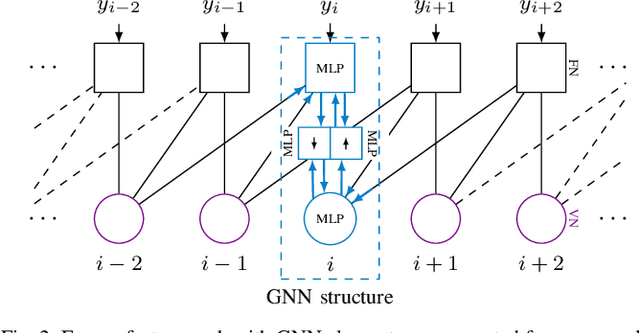
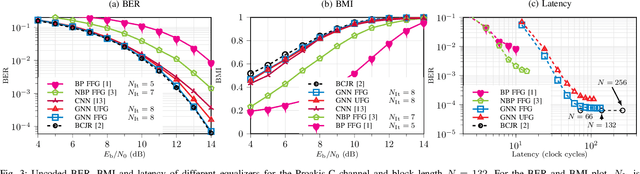
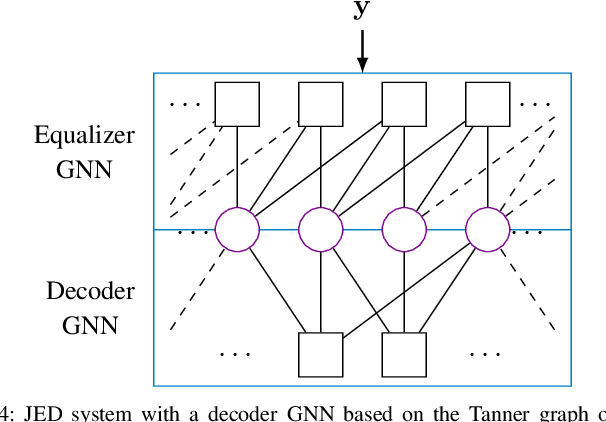
This paper proposes to use graph neural networks (GNNs) for equalization, that can also be used to perform joint equalization and decoding (JED). For equalization, the GNN is build upon the factor graph representations of the channel, while for JED, the factor graph is expanded by the Tanner graph of the parity-check matrix (PCM) of the channel code, sharing the variable nodes (VNs). A particularly advantageous property of the GNN is the robustness against cycles in the factor graphs which is the main problem for belief propagation (BP)-based equalization. As a result of having a fully deep learning-based receiver, joint optimization instead of individual optimization of the components is enabled, so-called end-to-end learning. Furthermore, we propose a parallel flooding schedule that further reduces the latency, which turns out to improve also the error correcting performance. The proposed approach is analyzed and compared to state-of-the-art baselines in terms of error correcting capability and latency. At a fixed low latency, the flooding GNN for JED demonstrates a gain of 2.25 dB in bit error rate (BER) compared to an iterative Bahl--Cock--Jelinek--Raviv (BCJR)-BP baseline.
Deep Learning Based Adaptive Joint mmWave Beam Alignment
Jan 24, 2024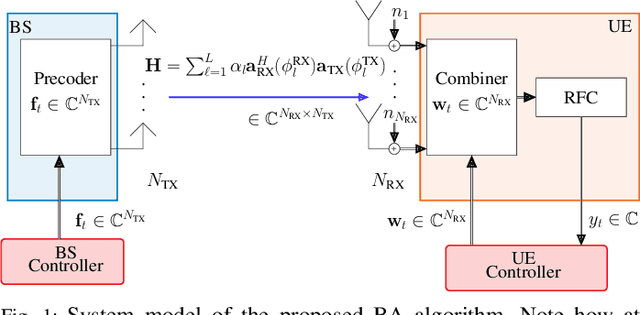
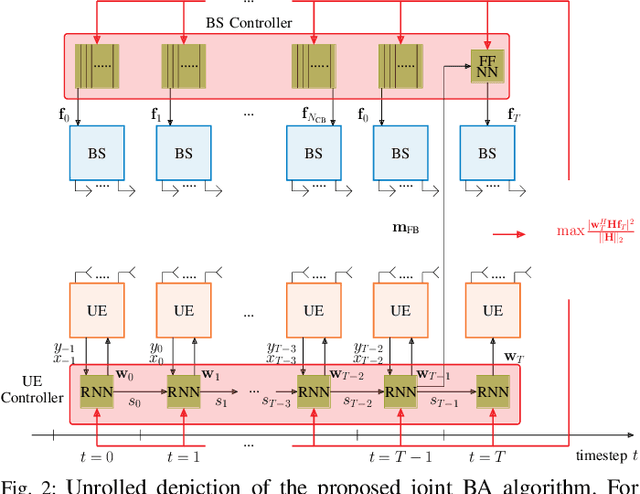
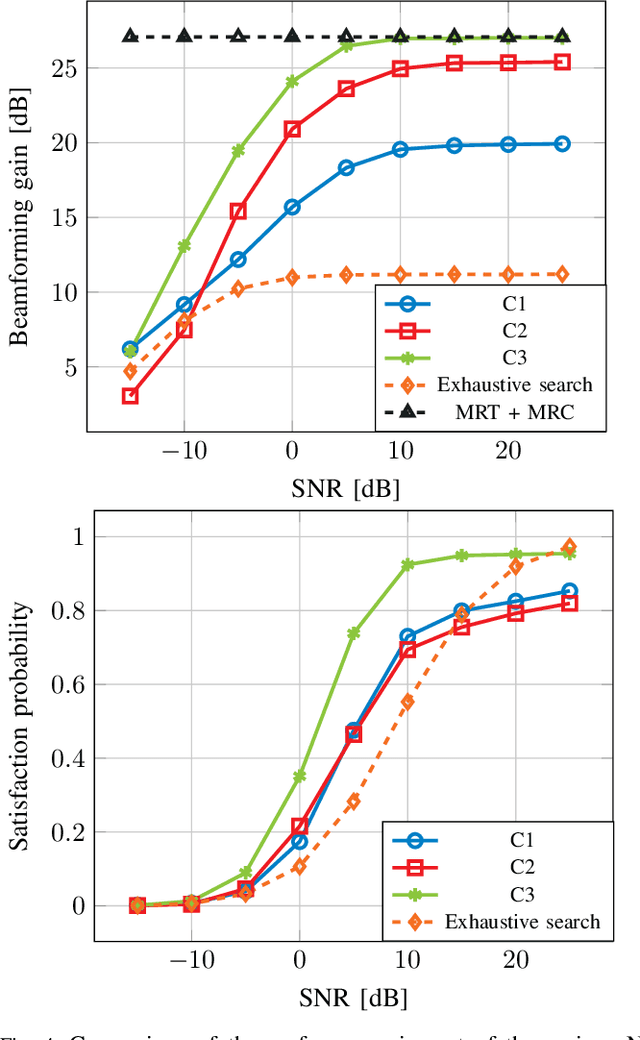
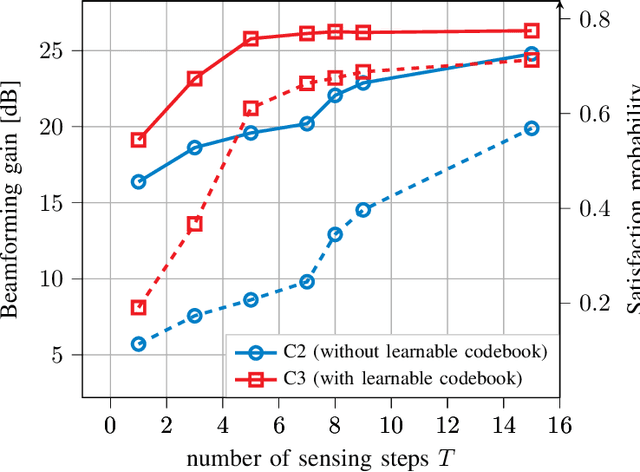
The challenging propagation environment, combined with the hardware limitations of mmWave systems, gives rise to the need for accurate initial access beam alignment strategies with low latency and high achievable beamforming gain. Much of the recent work in this area either focuses on one-sided beam alignment, or, joint beam alignment methods where both sides of the link perform a sequence of fixed channel probing steps. Codebook-based non-adaptive beam alignment schemes have the potential to allow multiple user equipment (UE) to perform initial access beam alignment in parallel whereas adaptive schemes are favourable in achievable beamforming gain. This work introduces a novel deep learning based joint beam alignment scheme that aims to combine the benefits of adaptive, codebook-free beam alignment at the UE side with the advantages of a codebook-sweep based scheme at the base station. The proposed end-to-end trainable scheme is compatible with current cellular standard signaling and can be readily integrated into the standard without requiring significant changes to it. Extensive simulations demonstrate superior performance of the proposed approach over purely codebook-based ones.
Deep Reinforcement Learning for mmWave Initial Beam Alignment
Feb 17, 2023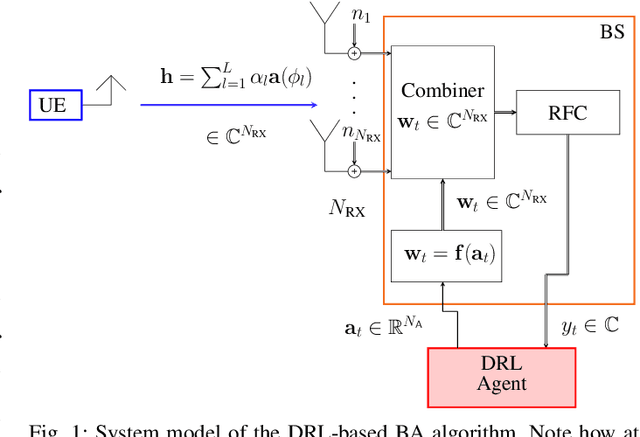
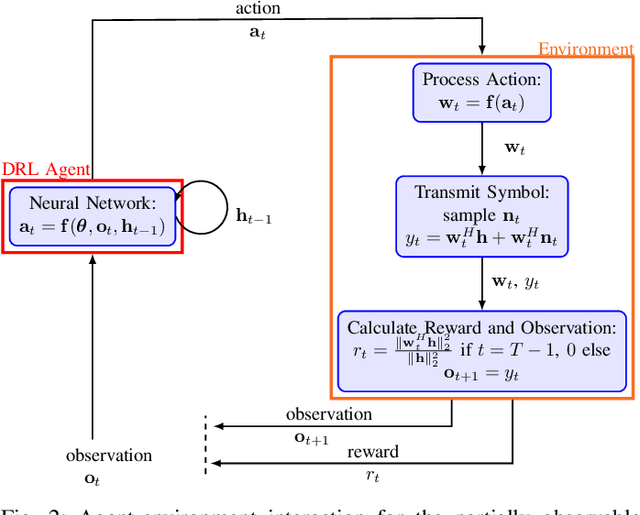
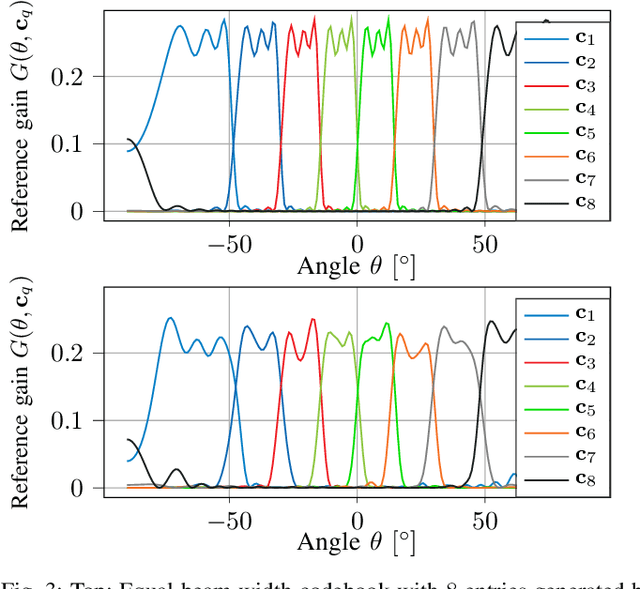
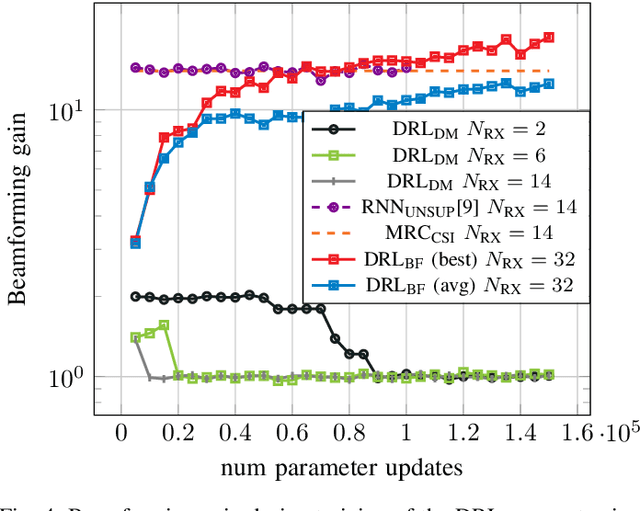
We investigate the applicability of deep reinforcement learning algorithms to the adaptive initial access beam alignment problem for mmWave communications using the state-of-the-art proximal policy optimization algorithm as an example. In comparison to recent unsupervised learning based approaches developed to tackle this problem, deep reinforcement learning has the potential to address a new and wider range of applications, since, in principle, no (differentiable) model of the channel and/or the whole system is required for training, and only agent-environment interactions are necessary to learn an algorithm (be it online or using a recorded dataset). We show that, although the chosen off-the-shelf deep reinforcement learning agent fails to perform well when trained on realistic problem sizes, introducing action space shaping in the form of beamforming modules vastly improves the performance, without sacrificing much generalizability. Using this add-on, the agent is able to deliver competitive performance to various state-of-the-art methods on simulated environments, even under realistic problem sizes. This demonstrates that through well-directed modification, deep reinforcement learning may have a chance to compete with other approaches in this area, opening up many straightforward extensions to other/similar scenarios.
On Recurrent Neural Networks for Sequence-based Processing in Communications
May 24, 2019

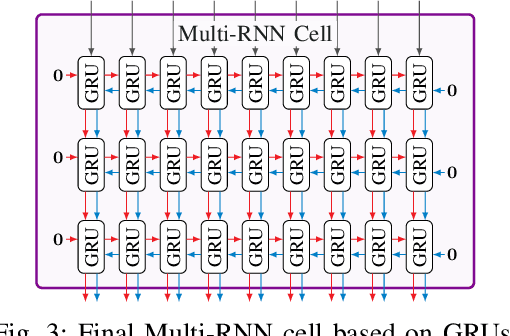
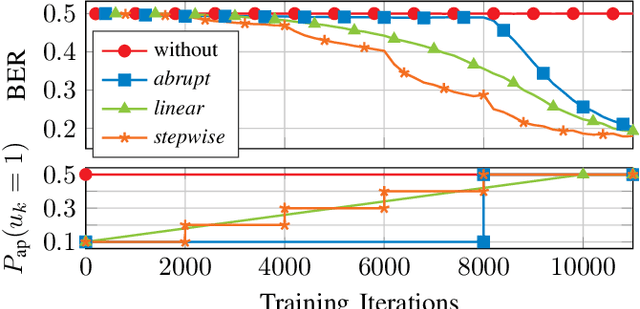
In this work, we analyze the capabilities and practical limitations of neural networks (NNs) for sequence-based signal processing which can be seen as an omnipresent property in almost any modern communication systems. In particular, we train multiple state-of-the-art recurrent neural network (RNN) structures to learn how to decode convolutional codes allowing a clear benchmarking with the corresponding maximum likelihood (ML) Viterbi decoder. We examine the decoding performance for various kinds of NN architectures, beginning with classical types like feedforward layers and gated recurrent unit (GRU)-layers, up to more recently introduced architectures such as temporal convolutional networks (TCNs) and differentiable neural computers (DNCs) with external memory. As a key limitation, it turns out that the training complexity increases exponentially with the length of the encoding memory $\nu$ and, thus, practically limits the achievable bit error rate (BER) performance. To overcome this limitation, we introduce a new training-method by gradually increasing the number of ones within the training sequences, i.e., we constrain the amount of possible training sequences in the beginning until first convergence. By consecutively adding more and more possible sequences to the training set, we finally achieve training success in cases that did not converge before via naive training. Further, we show that our network can learn to jointly detect and decode a quadrature phase shift keying (QPSK) modulated code with sub-optimal (anti-Gray) labeling in one-shot at a performance that would require iterations between demapper and decoder in classic detection schemes.