 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Recurrent Neural Networks for Sequence-based Processing in Communications
Paper and Code


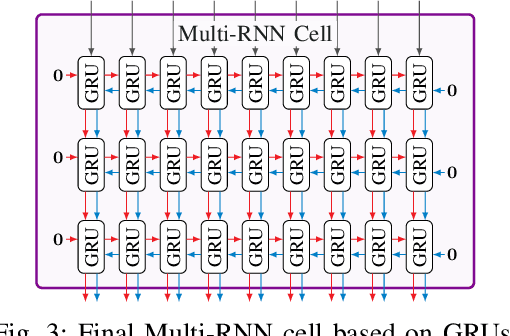
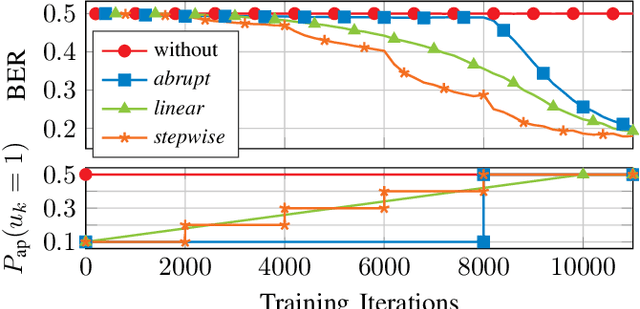
In this work, we analyze the capabilities and practical limitations of neural networks (NNs) for sequence-based signal processing which can be seen as an omnipresent property in almost any modern communication systems. In particular, we train multiple state-of-the-art recurrent neural network (RNN) structures to learn how to decode convolutional codes allowing a clear benchmarking with the corresponding maximum likelihood (ML) Viterbi decoder. We examine the decoding performance for various kinds of NN architectures, beginning with classical types like feedforward layers and gated recurrent unit (GRU)-layers, up to more recently introduced architectures such as temporal convolutional networks (TCNs) and differentiable neural computers (DNCs) with external memory. As a key limitation, it turns out that the training complexity increases exponentially with the length of the encoding memory $\nu$ and, thus, practically limits the achievable bit error rate (BER) performance. To overcome this limitation, we introduce a new training-method by gradually increasing the number of ones within the training sequences, i.e., we constrain the amount of possible training sequences in the beginning until first convergence. By consecutively adding more and more possible sequences to the training set, we finally achieve training success in cases that did not converge before via naive training. Further, we show that our network can learn to jointly detect and decode a quadrature phase shift keying (QPSK) modulated code with sub-optimal (anti-Gray) labeling in one-shot at a performance that would require iterations between demapper and decoder in classic detection schemes.