 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeudal Networks for Visual Navigation
Paper and Code
Feb 19, 2024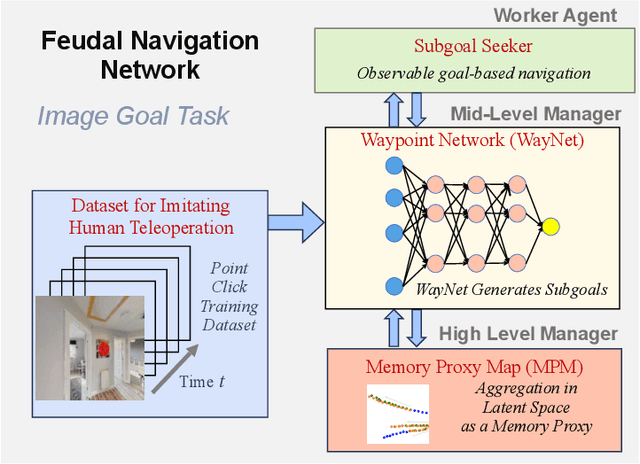

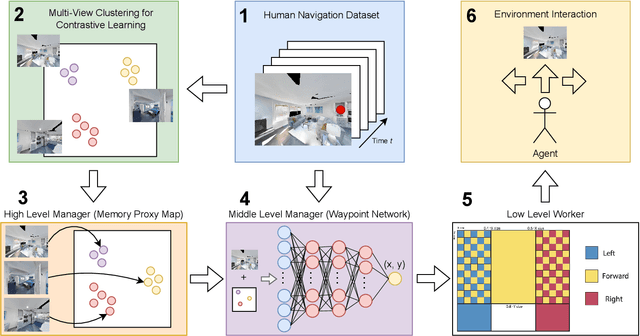
Visual navigation follows the intuition that humans can navigate without detailed maps. A common approach is interactive exploration while building a topological graph with images at nodes that can be used for planning. Recent variations learn from passive videos and can navigate using complex social and semantic cues. However, a significant number of training videos are needed, large graphs are utilized, and scenes are not unseen since odometry is utilized. We introduce a new approach to visual navigation using feudal learning, which employs a hierarchical structure consisting of a worker agent, a mid-level manager, and a high-level manager. Key to the feudal learning paradigm, agents at each level see a different aspect of the task and operate at different spatial and temporal scales. Two unique modules are developed in this framework. For the high-level manager, we learn a memory proxy map in a self supervised manner to record prior observations in a learned latent space and avoid the use of graphs and odometry. For the mid-level manager, we develop a waypoint network that outputs intermediate subgoals imitating human waypoint selection during local navigation. This waypoint network is pre-trained using a new, small set of teleoperation videos that we make publicly available, with training environments different from testing environments. The resulting feudal navigation network achieves near SOTA performance, while providing a novel no-RL, no-graph, no-odometry, no-metric map approach to the image goal navigation task.