 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgtech Framework for Cranberry-Ripening Analysis Using Vision Foundation Models
Dec 12, 2024


Agricultural domains are being transformed by recent advances in AI and computer vision that support quantitative visual evaluation. Using aerial and ground imaging over a time series, we develop a framework for characterizing the ripening process of cranberry crops, a crucial component for precision agriculture tasks such as comparing crop breeds (high-throughput phenotyping) and detecting disease. Using drone imaging, we capture images from 20 waypoints across multiple bogs, and using ground-based imaging (hand-held camera), we image same bog patch using fixed fiducial markers. Both imaging methods are repeated to gather a multi-week time series spanning the entire growing season. Aerial imaging provides multiple samples to compute a distribution of albedo values. Ground imaging enables tracking of individual berries for a detailed view of berry appearance changes. Using vision transformers (ViT) for feature detection after segmentation, we extract a high dimensional feature descriptor of berry appearance. Interpretability of appearance is critical for plant biologists and cranberry growers to support crop breeding decisions (e.g.\ comparison of berry varieties from breeding programs). For interpretability, we create a 2D manifold of cranberry appearance by using a UMAP dimensionality reduction on ViT features. This projection enables quantification of ripening paths and a useful metric of ripening rate. We demonstrate the comparison of four cranberry varieties based on our ripening assessments. This work is the first of its kind and has future impact for cranberries and for other crops including wine grapes, olives, blueberries, and maize. Aerial and ground datasets are made publicly available.
Memory Proxy Maps for Visual Navigation
Nov 15, 2024



Visual navigation takes inspiration from humans, who navigate in previously unseen environments using vision without detailed environment maps. Inspired by this, we introduce a novel no-RL, no-graph, no-odometry approach to visual navigation using feudal learning to build a three tiered agent. Key to our approach is a memory proxy map (MPM), an intermediate representation of the environment learned in a self-supervised manner by the high-level manager agent that serves as a simplified memory, approximating what the agent has seen. We demonstrate that recording observations in this learned latent space is an effective and efficient memory proxy that can remove the need for graphs and odometry in visual navigation tasks. For the mid-level manager agent, we develop a waypoint network (WayNet) that outputs intermediate subgoals, or waypoints, imitating human waypoint selection during local navigation. For the low-level worker agent, we learn a classifier over a discrete action space that avoids local obstacles and moves the agent towards the WayNet waypoint. The resulting feudal navigation network offers a novel approach with no RL, no graph, no odometry, and no metric map; all while achieving SOTA results on the image goal navigation task.
A Landmark-Aware Visual Navigation Dataset
Feb 22, 2024



Map representation learned by expert demonstrations has shown promising research value. However, recent advancements in the visual navigation field face challenges due to the lack of human datasets in the real world for efficient supervised representation learning of the environments. We present a Landmark-Aware Visual Navigation (LAVN) dataset to allow for supervised learning of human-centric exploration policies and map building. We collect RGB observation and human point-click pairs as a human annotator explores virtual and real-world environments with the goal of full coverage exploration of the space. The human annotators also provide distinct landmark examples along each trajectory, which we intuit will simplify the task of map or graph building and localization. These human point-clicks serve as direct supervision for waypoint prediction when learning to explore in environments. Our dataset covers a wide spectrum of scenes, including rooms in indoor environments, as well as walkways outdoors. Dataset is available at DOI: 10.5281/zenodo.10608067.
Feudal Networks for Visual Navigation
Feb 19, 2024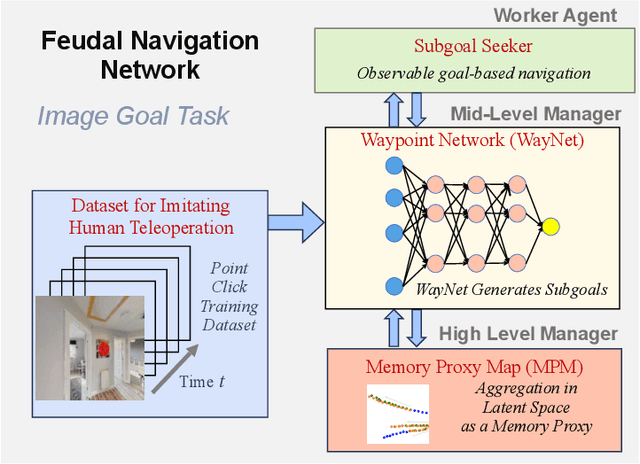

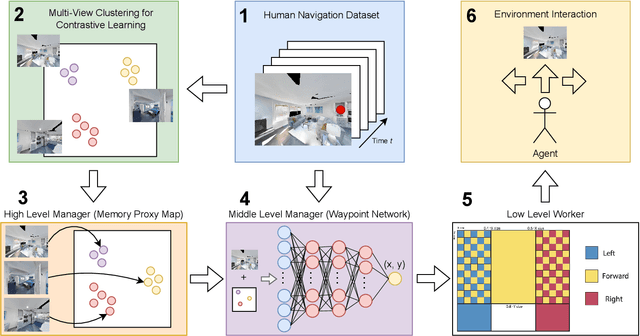
Visual navigation follows the intuition that humans can navigate without detailed maps. A common approach is interactive exploration while building a topological graph with images at nodes that can be used for planning. Recent variations learn from passive videos and can navigate using complex social and semantic cues. However, a significant number of training videos are needed, large graphs are utilized, and scenes are not unseen since odometry is utilized. We introduce a new approach to visual navigation using feudal learning, which employs a hierarchical structure consisting of a worker agent, a mid-level manager, and a high-level manager. Key to the feudal learning paradigm, agents at each level see a different aspect of the task and operate at different spatial and temporal scales. Two unique modules are developed in this framework. For the high-level manager, we learn a memory proxy map in a self supervised manner to record prior observations in a learned latent space and avoid the use of graphs and odometry. For the mid-level manager, we develop a waypoint network that outputs intermediate subgoals imitating human waypoint selection during local navigation. This waypoint network is pre-trained using a new, small set of teleoperation videos that we make publicly available, with training environments different from testing environments. The resulting feudal navigation network achieves near SOTA performance, while providing a novel no-RL, no-graph, no-odometry, no-metric map approach to the image goal navigation task.
Hierarchical Reinforcement Learning for Temporal Pattern Prediction
Oct 09, 2023In this work, we explore the use of hierarchical reinforcement learning (HRL) for the task of temporal sequence prediction. Using a combination of deep learning and HRL, we develop a stock agent to predict temporal price sequences from historical stock price data and a vehicle agent to predict steering angles from first person, dash cam images. Our results in both domains indicate that a type of HRL, called feudal reinforcement learning, provides significant improvements to training speed and stability and prediction accuracy over standard RL. A key component to this success is the multi-resolution structure that introduces both temporal and spatial abstraction into the network hierarchy.
Vision-Based Cranberry Crop Ripening Assessment
Aug 31, 2023


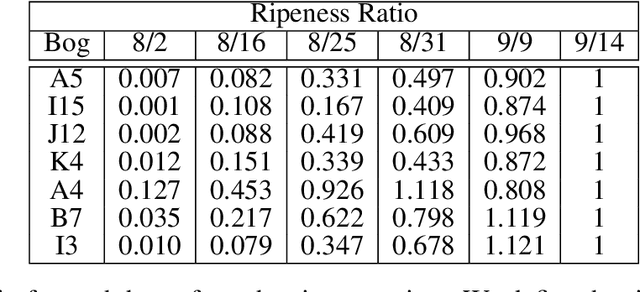
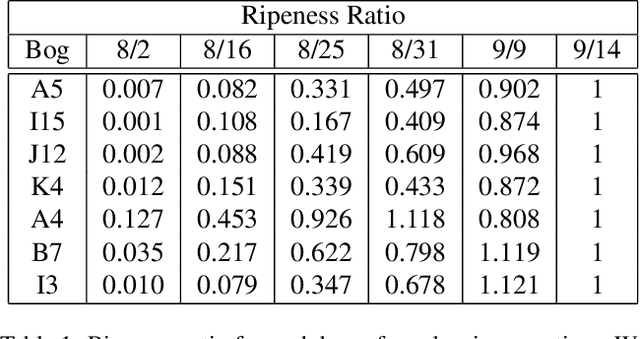
Agricultural domains are being transformed by recent advances in AI and computer vision that support quantitative visual evaluation. Using drone imaging, we develop a framework for characterizing the ripening process of cranberry crops. Our method consists of drone-based time-series collection over a cranberry growing season, photometric calibration for albedo recovery from pixels, and berry segmentation with semi-supervised deep learning networks using point-click annotations. By extracting time-series berry albedo measurements, we evaluate four different varieties of cranberries and provide a quantification of their ripening rates. Such quantification has practical implications for 1) assessing real-time overheating risks for cranberry bogs; 2) large scale comparisons of progeny in crop breeding; 3) detecting disease by looking for ripening pattern outliers. This work is the first of its kind in quantitative evaluation of ripening using computer vision methods and has impact beyond cranberry crops including wine grapes, olives, blueberries, and maize.
Learning a Pedestrian Social Behavior Dictionary
Dec 02, 2022


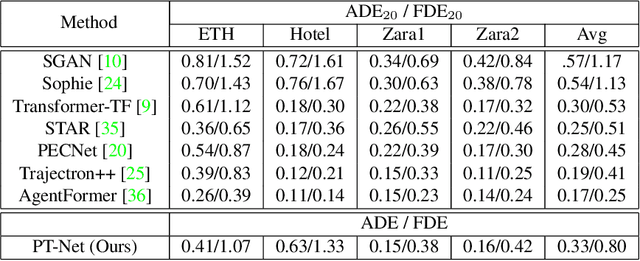
Understanding pedestrian behavior patterns is a key component to building autonomous agents that can navigate among humans. We seek a learned dictionary of pedestrian behavior to obtain a semantic description of pedestrian trajectories. Supervised methods for dictionary learning are impractical since pedestrian behaviors may be unknown a priori and the process of manually generating behavior labels is prohibitively time consuming. We instead utilize a novel, unsupervised framework to create a taxonomy of pedestrian behavior observed in a specific space. First, we learn a trajectory latent space that enables unsupervised clustering to create an interpretable pedestrian behavior dictionary. We show the utility of this dictionary for building pedestrian behavior maps to visualize space usage patterns and for computing the distributions of behaviors. We demonstrate a simple but effective trajectory prediction by conditioning on these behavior labels. While many trajectory analysis methods rely on RNNs or transformers, we develop a lightweight, low-parameter approach and show results comparable to SOTA on the ETH and UCY datasets.
Feudal Steering: Hierarchical Learning for Steering Angle Prediction
Jun 11, 2020
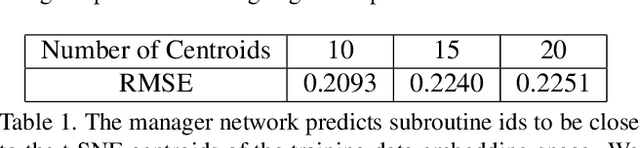
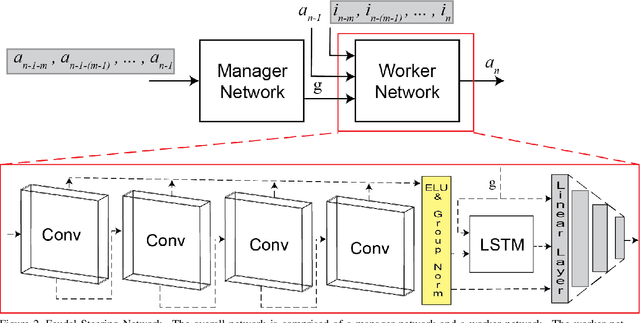
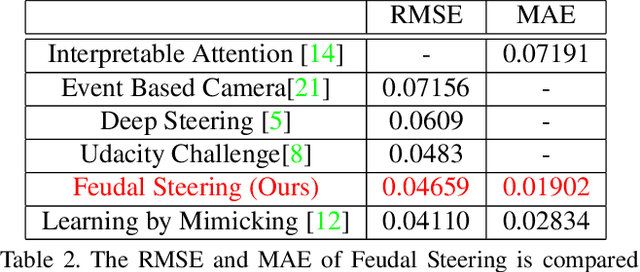
We consider the challenge of automated steering angle prediction for self driving cars using egocentric road images. In this work, we explore the use of feudal networks, used in hierarchical reinforcement learning (HRL), to devise a vehicle agent to predict steering angles from first person, dash-cam images of the Udacity driving dataset. Our method, Feudal Steering, is inspired by recent work in HRL consisting of a manager network and a worker network that operate on different temporal scales and have different goals. The manager works at a temporal scale that is relatively coarse compared to the worker and has a higher level, task-oriented goal space. Using feudal learning to divide the task into manager and worker sub-networks provides more accurate and robust prediction. Temporal abstraction in driving allows more complex primitives than the steering angle at a single time instance. Composite actions comprise a subroutine or skill that can be re-used throughout the driving sequence. The associated subroutine id is the manager network's goal, so that the manager seeks to succeed at the high level task (e.g. a sharp right turn, a slight right turn, moving straight in traffic, or moving straight unencumbered by traffic). The steering angle at a particular time instance is the worker network output which is regulated by the manager's high level task. We demonstrate state-of-the art steering angle prediction results on the Udacity dataset.