 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUtilization of Neighbor Information for Image Classification with Different Levels of Supervision
Mar 18, 2025We propose to bridge the gap between semi-supervised and unsupervised image recognition with a flexible method that performs well for both generalized category discovery (GCD) and image clustering. Despite the overlap in motivation between these tasks, the methods themselves are restricted to a single task -- GCD methods are reliant on the labeled portion of the data, and deep image clustering methods have no built-in way to leverage the labels efficiently. We connect the two regimes with an innovative approach that Utilizes Neighbor Information for Classification (UNIC) both in the unsupervised (clustering) and semisupervised (GCD) setting. State-of-the-art clustering methods already rely heavily on nearest neighbors. We improve on their results substantially in two parts, first with a sampling and cleaning strategy where we identify accurate positive and negative neighbors, and secondly by finetuning the backbone with clustering losses computed by sampling both types of neighbors. We then adapt this pipeline to GCD by utilizing the labelled images as ground truth neighbors. Our method yields state-of-the-art results for both clustering (+3% ImageNet-100, Imagenet200) and GCD (+0.8% ImageNet-100, +5% CUB, +2% SCars, +4% Aircraft).
S2TPVFormer: Spatio-Temporal Tri-Perspective View for temporally coherent 3D Semantic Occupancy Prediction
Jan 24, 2024

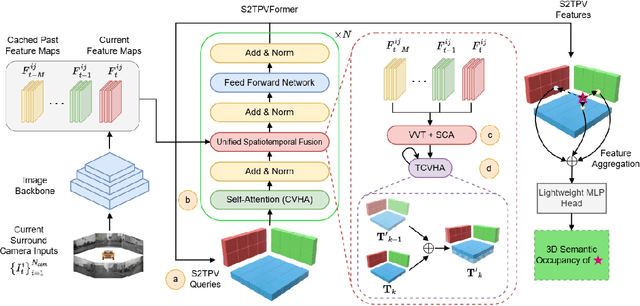
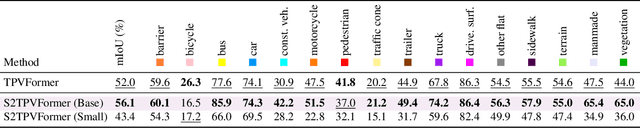
Holistic understanding and reasoning in 3D scenes play a vital role in the success of autonomous driving systems. The evolution of 3D semantic occupancy prediction as a pretraining task for autonomous driving and robotic downstream tasks captures finer 3D details compared to methods like 3D detection. Existing approaches predominantly focus on spatial cues, often overlooking temporal cues. Query-based methods tend to converge on computationally intensive Voxel representation for encoding 3D scene information. This study introduces S2TPVFormer, an extension of TPVFormer, utilizing a spatiotemporal transformer architecture for coherent 3D semantic occupancy prediction. Emphasizing the importance of spatiotemporal cues in 3D scene perception, particularly in 3D semantic occupancy prediction, our work explores the less-explored realm of temporal cues. Leveraging Tri-Perspective View (TPV) representation, our spatiotemporal encoder generates temporally rich embeddings, improving prediction coherence while maintaining computational efficiency. To achieve this, we propose a novel Temporal Cross-View Hybrid Attention (TCVHA) mechanism, facilitating effective spatiotemporal information exchange across TPV views. Experimental evaluations on the nuScenes dataset demonstrate a substantial 3.1% improvement in mean Intersection over Union (mIoU) for 3D Semantic Occupancy compared to TPVFormer, confirming the effectiveness of the proposed S2TPVFormer in enhancing 3D scene perception.
Holistic Interpretation of Public Scenes Using Computer Vision and Temporal Graphs to Identify Social Distancing Violations
Dec 13, 2021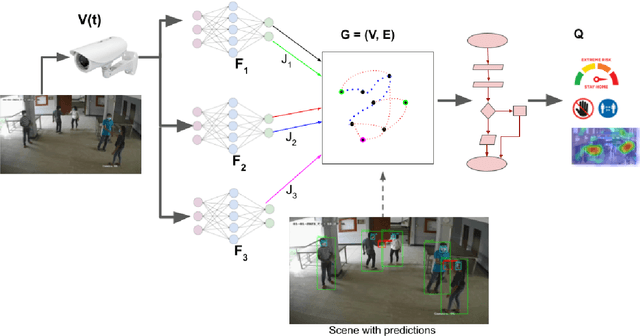

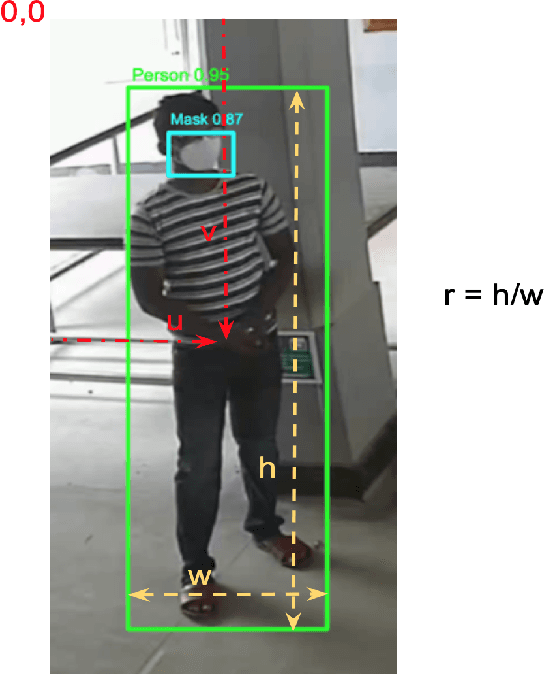

The COVID-19 pandemic has caused an unprecedented global public health crisis. Given its inherent nature, social distancing measures are proposed as the primary strategies to curb the spread of this pandemic. Therefore, identifying situations where these protocols are violated, has implications for curtailing the spread of the disease and promoting a sustainable lifestyle. This paper proposes a novel computer vision-based system to analyze CCTV footage to provide a threat level assessment of COVID-19 spread. The system strives to holistically capture and interpret the information content of CCTV footage spanning multiple frames to recognize instances of various violations of social distancing protocols, across time and space, as well as identification of group behaviors. This functionality is achieved primarily by utilizing a temporal graph-based structure to represent the information of the CCTV footage and a strategy to holistically interpret the graph and quantify the threat level of the given scene. The individual components are tested and validated on a range of scenarios and the complete system is tested against human expert opinion. The results reflect the dependence of the threat level on people, their physical proximity, interactions, protective clothing, and group dynamics. The system performance has an accuracy of 76%, thus enabling a deployable threat monitoring system in cities, to permit normalcy and sustainability in the society.
Hands Off: A Handshake Interaction Detection and Localization Model for COVID-19 Threat Control
Oct 18, 2021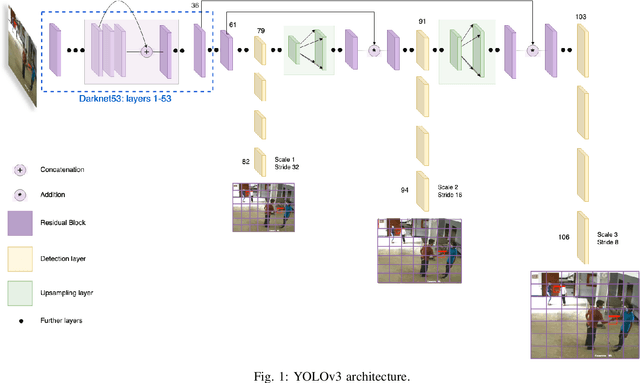

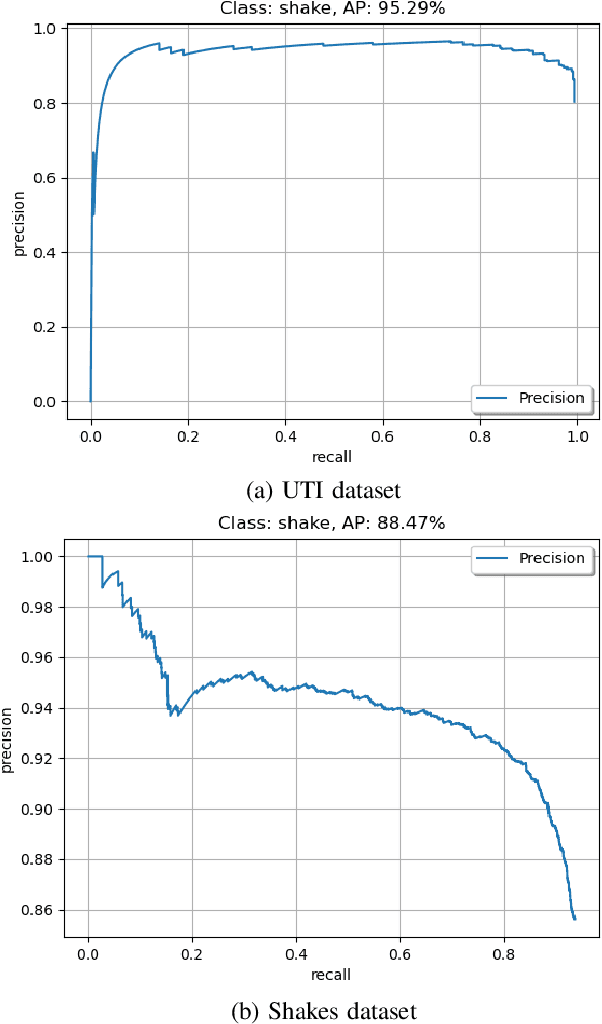

The COVID-19 outbreak has affected millions of people across the globe and is continuing to spread at a drastic scale. Out of the numerous steps taken to control the spread of the virus, social distancing has been a crucial and effective practice. However, recent reports of social distancing violations suggest the need for non-intrusive detection techniques to ensure safety in public spaces. In this paper, a real-time detection model is proposed to identify handshake interactions in a range of realistic scenarios with multiple people in the scene and also detect multiple interactions in a single frame. This is the first work that performs dyadic interaction localization in a multi-person setting. The efficacy of the proposed model was evaluated across two different datasets on more than 3200 frames, thus enabling a robust localization model in different environments. The proposed model is the first dyadic interaction localizer in a multi-person setting, which enables it to be used in public spaces to identify handshake interactions and thereby identify and mitigate COVID-19 transmission.
A generalized forecasting solution to enable future insights of COVID-19 at sub-national level resolutions
Aug 21, 2021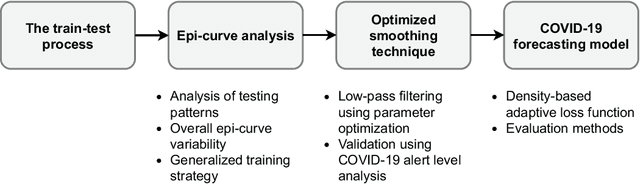
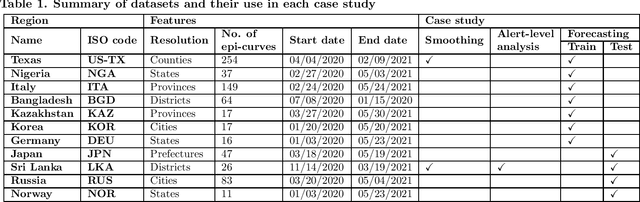
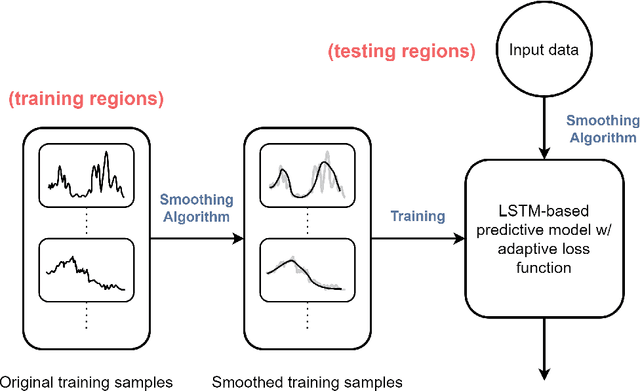
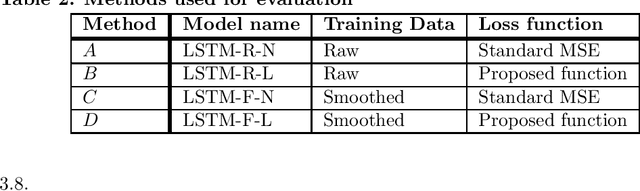
COVID-19 continues to cause a significant impact on public health. To minimize this impact, policy makers undertake containment measures that however, when carried out disproportionately to the actual threat, as a result if errorneous threat assessment, cause undesirable long-term socio-economic complications. In addition, macro-level or national level decision making fails to consider the localized sensitivities in small regions. Hence, the need arises for region-wise threat assessments that provide insights on the behaviour of COVID-19 through time, enabled through accurate forecasts. In this study, a forecasting solution is proposed, to predict daily new cases of COVID-19 in regions small enough where containment measures could be locally implemented, by targeting three main shortcomings that exist in literature; the unreliability of existing data caused by inconsistent testing patterns in smaller regions, weak deploy-ability of forecasting models towards predicting cases in previously unseen regions, and model training biases caused by the imbalanced nature of data in COVID-19 epi-curves. Hence, the contributions of this study are three-fold; an optimized smoothing technique to smoothen less deterministic epi-curves based on epidemiological dynamics of that region, a Long-Short-Term-Memory (LSTM) based forecasting model trained using data from select regions to create a representative and diverse training set that maximizes deploy-ability in regions with lack of historical data, and an adaptive loss function whilst training to mitigate the data imbalances seen in epi-curves. The proposed smoothing technique, the generalized training strategy and the adaptive loss function largely increased the overall accuracy of the forecast, which enables efficient containment measures at a more localized micro-level.
An Optical physics inspired CNN approach for intrinsic image decomposition
May 21, 2021

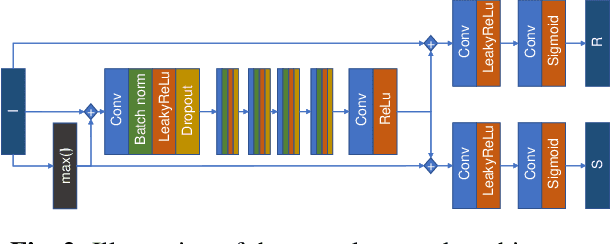

Intrinsic Image Decomposition is an open problem of generating the constituents of an image. Generating reflectance and shading from a single image is a challenging task specifically when there is no ground truth. There is a lack of unsupervised learning approaches for decomposing an image into reflectance and shading using a single image. We propose a neural network architecture capable of this decomposition using physics-based parameters derived from the image. Through experimental results, we show that (a) the proposed methodology outperforms the existing deep learning-based IID techniques and (b) the derived parameters improve the efficacy significantly. We conclude with a closer analysis of the results (numerical and example images) showing several avenues for improvement.
DeepLight: Robust & Unobtrusive Real-time Screen-Camera Communication for Real-World Displays
May 11, 2021
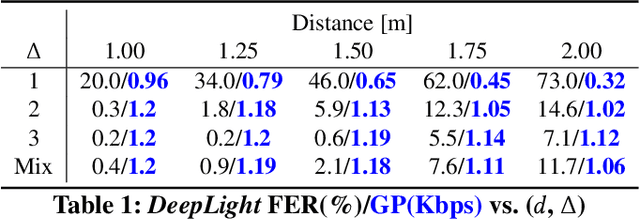

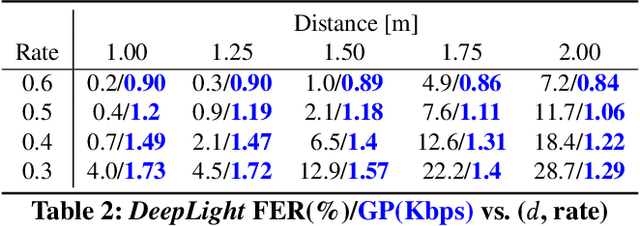
The paper introduces a novel, holistic approach for robust Screen-Camera Communication (SCC), where video content on a screen is visually encoded in a human-imperceptible fashion and decoded by a camera capturing images of such screen content. We first show that state-of-the-art SCC techniques have two key limitations for in-the-wild deployment: (a) the decoding accuracy drops rapidly under even modest screen extraction errors from the captured images, and (b) they generate perceptible flickers on common refresh rate screens even with minimal modulation of pixel intensity. To overcome these challenges, we introduce DeepLight, a system that incorporates machine learning (ML) models in the decoding pipeline to achieve humanly-imperceptible, moderately high SCC rates under diverse real-world conditions. Deep-Light's key innovation is the design of a Deep Neural Network (DNN) based decoder that collectively decodes all the bits spatially encoded in a display frame, without attempting to precisely isolate the pixels associated with each encoded bit. In addition, DeepLight supports imperceptible encoding by selectively modulating the intensity of only the Blue channel, and provides reasonably accurate screen extraction (IoU values >= 83%) by using state-of-the-art object detection DNN pipelines. We show that a fully functional DeepLight system is able to robustly achieve high decoding accuracy (frame error rate < 0.2) and moderately-high data goodput (>=0.95Kbps) using a human-held smartphone camera, even over larger screen-camera distances (approx =2m).
A Retinex based GAN Pipeline to Utilize Paired and Unpaired Datasets for Enhancing Low Light Images
Jun 27, 2020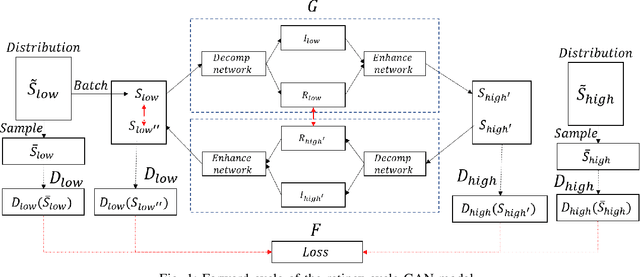
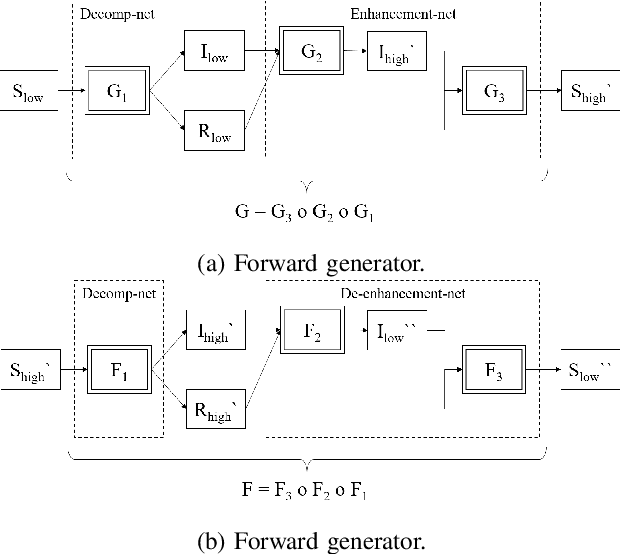
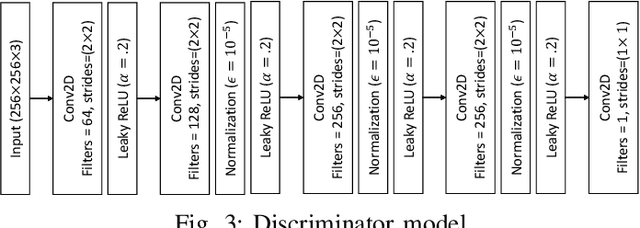

Low light image enhancement is an important challenge for the development of robust computer vision algorithms. The machine learning approaches to this have been either unsupervised, supervised based on paired dataset or supervised based on unpaired dataset. This paper presents a novel deep learning pipeline that can learn from both paired and unpaired datasets. Convolution Neural Networks (CNNs) that are optimized to minimize standard loss, and Generative Adversarial Networks (GANs) that are optimized to minimize the adversarial loss are used to achieve different steps of the low light image enhancement process. Cycle consistency loss and a patched discriminator are utilized to further improve the performance. The paper also analyses the functionality and the performance of different components, hidden layers, and the entire pipeline.
Non-contact Infant Sleep Apnea Detection
Oct 10, 2019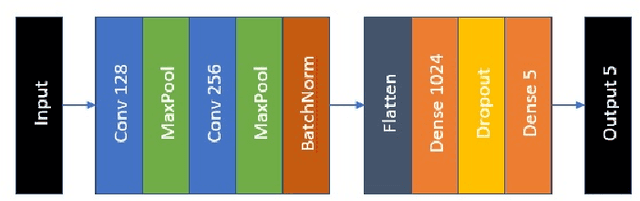
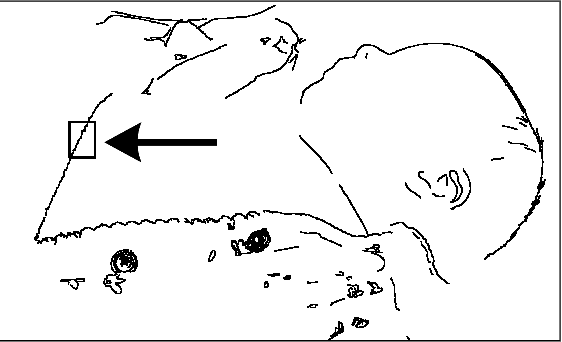
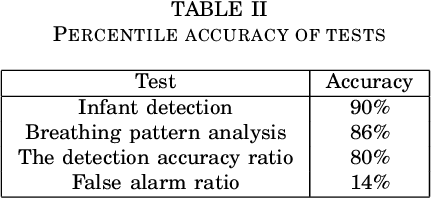
Sleep apnea is a breathing disorder where a person repeatedly stops breathing in sleep. Early detection is crucial for infants because it might bring long term adversities. The existing accurate detection mechanism (pulse oximetry) is a skin contact measurement. The existing non-contact mechanisms (acoustics, video processing) are not accurate enough. This paper presents a novel algorithm for the detection of sleep apnea with video processing. The solution is non-contact, accurate and lightweight enough to run on a single board computer. The paper discusses the accuracy of the algorithm on real data, advantages of the new algorithm, its limitations and suggests future improvements.