 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgemicroCLIP: Unsupervised CLIP Adaptation via Coarse-Fine Token Fusion for Fine-Grained Image Classification
Oct 02, 2025Unsupervised adaptation of CLIP-based vision-language models (VLMs) for fine-grained image classification requires sensitivity to microscopic local cues. While CLIP exhibits strong zero-shot transfer, its reliance on coarse global features restricts its performance on fine-grained classification tasks. Prior efforts inject fine-grained knowledge by aligning large language model (LLM) descriptions with the CLIP $\texttt{[CLS]}$ token; however, this approach overlooks spatial precision. We propose $\textbf{microCLIP}$, a self-training framework that jointly refines CLIP's visual and textual representations using fine-grained cues. At its core is Saliency-Oriented Attention Pooling (SOAP) within a lightweight TokenFusion module, which builds a saliency-guided $\texttt{[FG]}$ token from patch embeddings and fuses it with the global $\texttt{[CLS]}$ token for coarse-fine alignment. To stabilize adaptation, we introduce a two-headed LLM-derived classifier: a frozen classifier that, via multi-view alignment, provides a stable text-based prior for pseudo-labeling, and a learnable classifier initialized from LLM descriptions and fine-tuned with TokenFusion. We further develop Dynamic Knowledge Aggregation, which convexly combines fixed LLM/CLIP priors with TokenFusion's evolving logits to iteratively refine pseudo-labels. Together, these components uncover latent fine-grained signals in CLIP, yielding a consistent $2.90\%$ average accuracy gain across 13 fine-grained benchmarks while requiring only light adaptation. Our code is available at https://github.com/sathiiii/microCLIP.
DPA: Dual Prototypes Alignment for Unsupervised Adaptation of Vision-Language Models
Aug 16, 2024Vision-language models (VLMs), e.g., CLIP, have shown remarkable potential in zero-shot image classification. However, adapting these models to new domains remains challenging, especially in unsupervised settings where labelled data is unavailable. Recent research has proposed pseudo-labelling approaches to adapt CLIP in an unsupervised manner using unlabelled target data. Nonetheless, these methods struggle due to noisy pseudo-labels resulting from the misalignment between CLIP's visual and textual representations. This study introduces DPA, an unsupervised domain adaptation method for VLMs. DPA introduces the concept of dual prototypes, acting as distinct classifiers, along with the convex combination of their outputs, thereby leading to accurate pseudo-label construction. Next, it ranks pseudo-labels to facilitate robust self-training, particularly during early training. Finally, it addresses visual-textual misalignment by aligning textual prototypes with image prototypes to further improve the adaptation performance. Experiments on 13 downstream vision tasks demonstrate that DPA significantly outperforms zero-shot CLIP and the state-of-the-art unsupervised adaptation baselines.
S2TPVFormer: Spatio-Temporal Tri-Perspective View for temporally coherent 3D Semantic Occupancy Prediction
Jan 24, 2024

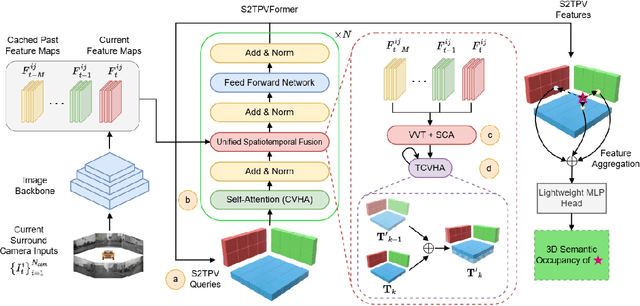
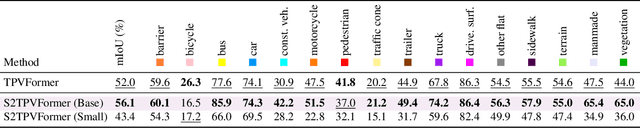
Holistic understanding and reasoning in 3D scenes play a vital role in the success of autonomous driving systems. The evolution of 3D semantic occupancy prediction as a pretraining task for autonomous driving and robotic downstream tasks captures finer 3D details compared to methods like 3D detection. Existing approaches predominantly focus on spatial cues, often overlooking temporal cues. Query-based methods tend to converge on computationally intensive Voxel representation for encoding 3D scene information. This study introduces S2TPVFormer, an extension of TPVFormer, utilizing a spatiotemporal transformer architecture for coherent 3D semantic occupancy prediction. Emphasizing the importance of spatiotemporal cues in 3D scene perception, particularly in 3D semantic occupancy prediction, our work explores the less-explored realm of temporal cues. Leveraging Tri-Perspective View (TPV) representation, our spatiotemporal encoder generates temporally rich embeddings, improving prediction coherence while maintaining computational efficiency. To achieve this, we propose a novel Temporal Cross-View Hybrid Attention (TCVHA) mechanism, facilitating effective spatiotemporal information exchange across TPV views. Experimental evaluations on the nuScenes dataset demonstrate a substantial 3.1% improvement in mean Intersection over Union (mIoU) for 3D Semantic Occupancy compared to TPVFormer, confirming the effectiveness of the proposed S2TPVFormer in enhancing 3D scene perception.