 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS2TPVFormer: Spatio-Temporal Tri-Perspective View for temporally coherent 3D Semantic Occupancy Prediction
Paper and Code
Jan 24, 2024

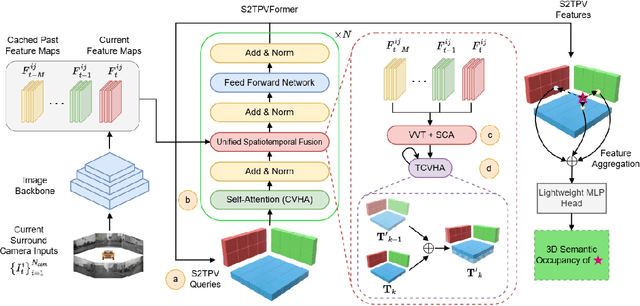
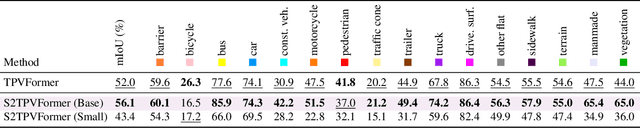
Holistic understanding and reasoning in 3D scenes play a vital role in the success of autonomous driving systems. The evolution of 3D semantic occupancy prediction as a pretraining task for autonomous driving and robotic downstream tasks captures finer 3D details compared to methods like 3D detection. Existing approaches predominantly focus on spatial cues, often overlooking temporal cues. Query-based methods tend to converge on computationally intensive Voxel representation for encoding 3D scene information. This study introduces S2TPVFormer, an extension of TPVFormer, utilizing a spatiotemporal transformer architecture for coherent 3D semantic occupancy prediction. Emphasizing the importance of spatiotemporal cues in 3D scene perception, particularly in 3D semantic occupancy prediction, our work explores the less-explored realm of temporal cues. Leveraging Tri-Perspective View (TPV) representation, our spatiotemporal encoder generates temporally rich embeddings, improving prediction coherence while maintaining computational efficiency. To achieve this, we propose a novel Temporal Cross-View Hybrid Attention (TCVHA) mechanism, facilitating effective spatiotemporal information exchange across TPV views. Experimental evaluations on the nuScenes dataset demonstrate a substantial 3.1% improvement in mean Intersection over Union (mIoU) for 3D Semantic Occupancy compared to TPVFormer, confirming the effectiveness of the proposed S2TPVFormer in enhancing 3D scene perception.