 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSNAP-V: A RISC-V SoC with Configurable Neuromorphic Acceleration for Small-Scale Spiking Neural Networks
Mar 12, 2026Spiking Neural Networks (SNNs) have gained significant attention in edge computing due to their low power consumption and computational efficiency. However, existing implementations either use conventional System on Chip (SoC) architectures that suffer from memory-processor bottlenecks, or large-scale neuromorphic hardware that is inefficient and wasteful for small-scale SNN applications. This work presents SNAP-V, a RISC-V-based neuromorphic SoC with two accelerator variants: Cerebra-S (bus-based) and Cerebra-H (Network-on-Chip (NoC)-based) which are optimized for small-scale SNN inference, integrating a RISC-V core for management tasks, with both accelerators featuring parallel processing nodes and distributed memory. Experimental results show close agreement between software and hardware inference, with an average accuracy deviation of 2.62% across multiple network configurations, and an average synaptic energy of 1.05 pJ per synaptic operation (SOP) in 45 nm CMOS technology. These results show that the proposed solution enables accurate, energy-efficient SNN inference suitable for real-time edge applications.
Balancing Fidelity, Utility, and Privacy in Synthetic Cardiac MRI Generation: A Comparative Study
Mar 04, 2026Deep learning in cardiac MRI (CMR) is fundamentally constrained by both data scarcity and privacy regulations. This study systematically benchmarks three generative architectures: Denoising Diffusion Probabilistic Models (DDPM), Latent Diffusion Models (LDM), and Flow Matching (FM) for synthetic CMR generation. Utilizing a two-stage pipeline where anatomical masks condition image synthesis, we evaluate generated data across three critical axes: fidelity, utility, and privacy. Our results show that diffusion-based models, particularly DDPM, provide the most effective balance between downstream segmentation utility, image fidelity, and privacy preservation under limited-data conditions, while FM demonstrates promising privacy characteristics with slightly lower task-level performance. These findings quantify the trade-offs between cross-domain generalization and patient confidentiality, establishing a framework for safe and effective synthetic data augmentation in medical imaging.
S2TPVFormer: Spatio-Temporal Tri-Perspective View for temporally coherent 3D Semantic Occupancy Prediction
Jan 24, 2024

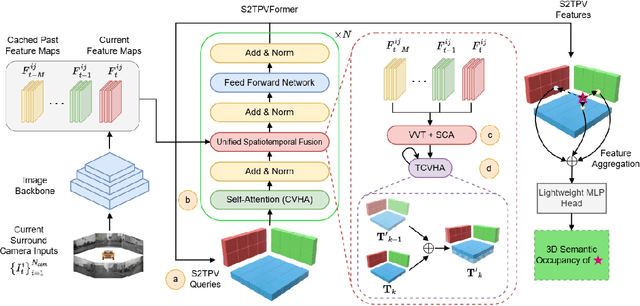
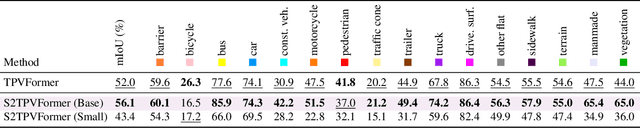
Holistic understanding and reasoning in 3D scenes play a vital role in the success of autonomous driving systems. The evolution of 3D semantic occupancy prediction as a pretraining task for autonomous driving and robotic downstream tasks captures finer 3D details compared to methods like 3D detection. Existing approaches predominantly focus on spatial cues, often overlooking temporal cues. Query-based methods tend to converge on computationally intensive Voxel representation for encoding 3D scene information. This study introduces S2TPVFormer, an extension of TPVFormer, utilizing a spatiotemporal transformer architecture for coherent 3D semantic occupancy prediction. Emphasizing the importance of spatiotemporal cues in 3D scene perception, particularly in 3D semantic occupancy prediction, our work explores the less-explored realm of temporal cues. Leveraging Tri-Perspective View (TPV) representation, our spatiotemporal encoder generates temporally rich embeddings, improving prediction coherence while maintaining computational efficiency. To achieve this, we propose a novel Temporal Cross-View Hybrid Attention (TCVHA) mechanism, facilitating effective spatiotemporal information exchange across TPV views. Experimental evaluations on the nuScenes dataset demonstrate a substantial 3.1% improvement in mean Intersection over Union (mIoU) for 3D Semantic Occupancy compared to TPVFormer, confirming the effectiveness of the proposed S2TPVFormer in enhancing 3D scene perception.
An Optical physics inspired CNN approach for intrinsic image decomposition
May 21, 2021

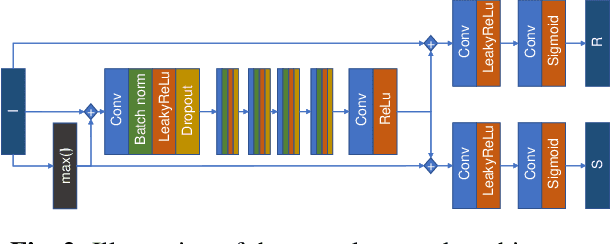

Intrinsic Image Decomposition is an open problem of generating the constituents of an image. Generating reflectance and shading from a single image is a challenging task specifically when there is no ground truth. There is a lack of unsupervised learning approaches for decomposing an image into reflectance and shading using a single image. We propose a neural network architecture capable of this decomposition using physics-based parameters derived from the image. Through experimental results, we show that (a) the proposed methodology outperforms the existing deep learning-based IID techniques and (b) the derived parameters improve the efficacy significantly. We conclude with a closer analysis of the results (numerical and example images) showing several avenues for improvement.
A Retinex based GAN Pipeline to Utilize Paired and Unpaired Datasets for Enhancing Low Light Images
Jun 27, 2020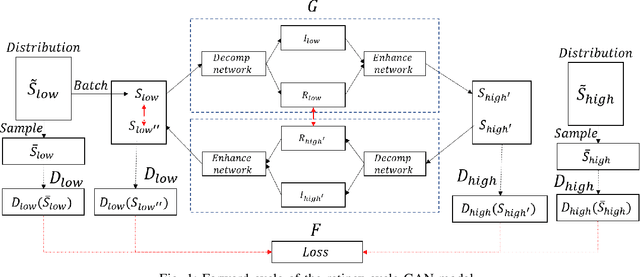
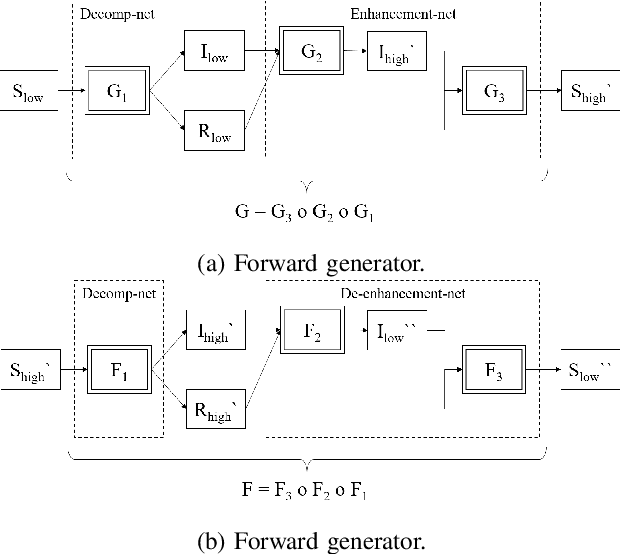
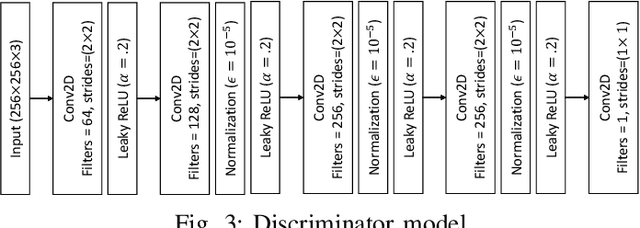

Low light image enhancement is an important challenge for the development of robust computer vision algorithms. The machine learning approaches to this have been either unsupervised, supervised based on paired dataset or supervised based on unpaired dataset. This paper presents a novel deep learning pipeline that can learn from both paired and unpaired datasets. Convolution Neural Networks (CNNs) that are optimized to minimize standard loss, and Generative Adversarial Networks (GANs) that are optimized to minimize the adversarial loss are used to achieve different steps of the low light image enhancement process. Cycle consistency loss and a patched discriminator are utilized to further improve the performance. The paper also analyses the functionality and the performance of different components, hidden layers, and the entire pipeline.
Non-contact Infant Sleep Apnea Detection
Oct 10, 2019
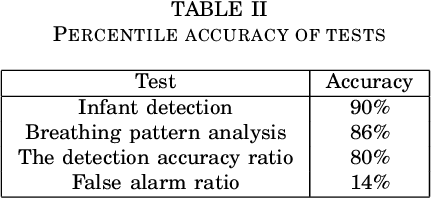
Sleep apnea is a breathing disorder where a person repeatedly stops breathing in sleep. Early detection is crucial for infants because it might bring long term adversities. The existing accurate detection mechanism (pulse oximetry) is a skin contact measurement. The existing non-contact mechanisms (acoustics, video processing) are not accurate enough. This paper presents a novel algorithm for the detection of sleep apnea with video processing. The solution is non-contact, accurate and lightweight enough to run on a single board computer. The paper discusses the accuracy of the algorithm on real data, advantages of the new algorithm, its limitations and suggests future improvements.
Near Real-Time Data Labeling Using a Depth Sensor for EMG Based Prosthetic Arms
Nov 10, 2018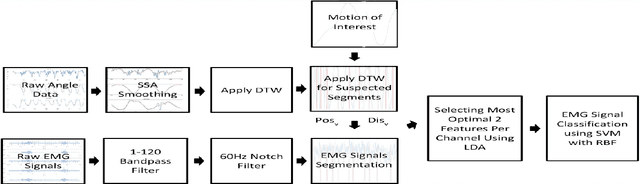
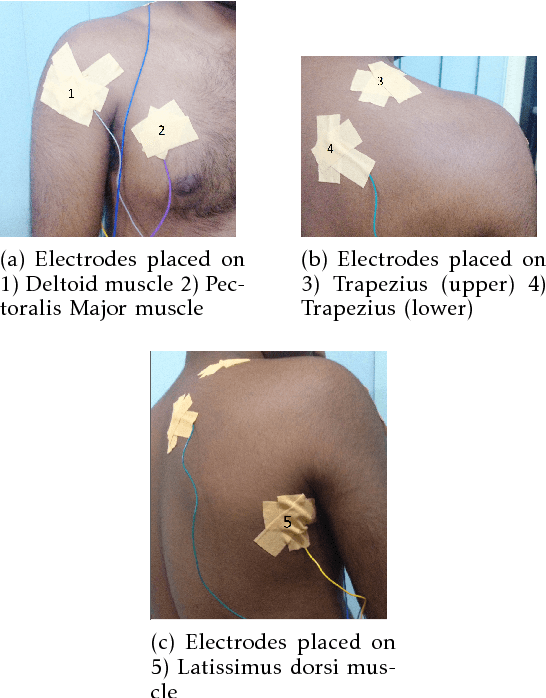
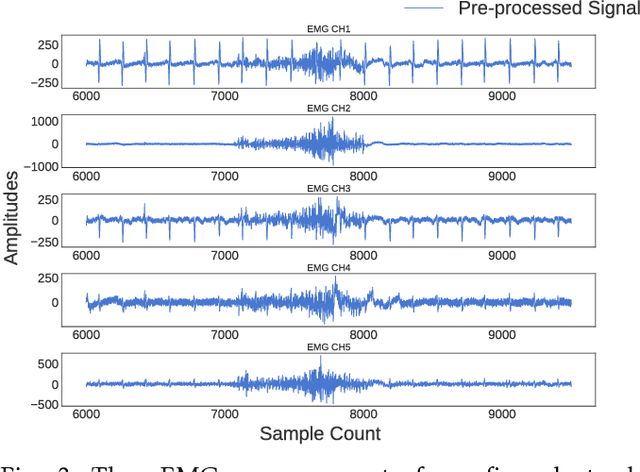
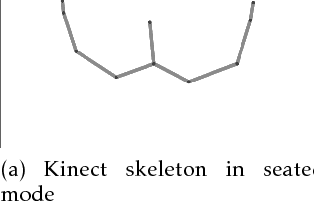
Recognizing sEMG (Surface Electromyography) signals belonging to a particular action (e.g., lateral arm raise) automatically is a challenging task as EMG signals themselves have a lot of variation even for the same action due to several factors. To overcome this issue, there should be a proper separation which indicates similar patterns repetitively for a particular action in raw signals. A repetitive pattern is not always matched because the same action can be carried out with different time duration. Thus, a depth sensor (Kinect) was used for pattern identification where three joint angles were recording continuously which is clearly separable for a particular action while recording sEMG signals. To Segment out a repetitive pattern in angle data, MDTW (Moving Dynamic Time Warping) approach is introduced. This technique is allowed to retrieve suspected motion of interest from raw signals. MDTW based on DTW algorithm, but it will be moving through the whole dataset in a pre-defined manner which is capable of picking up almost all the suspected segments inside a given dataset an optimal way. Elevated bicep curl and lateral arm raise movements are taken as motions of interest to show how the proposed technique can be employed to achieve auto identification and labelling. The full implementation is available at https://github.com/GPrathap/OpenBCIPython
High Throughput Virtual Screening with Data Level Parallelism in Multi-core Processors
Dec 04, 2013
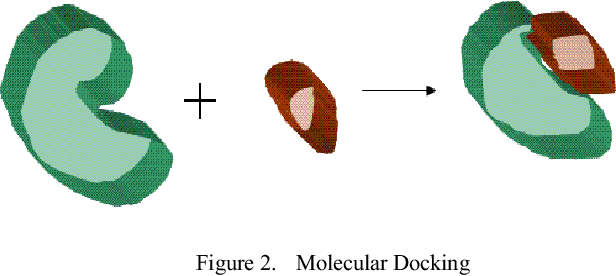
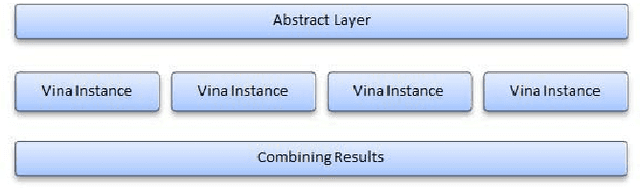
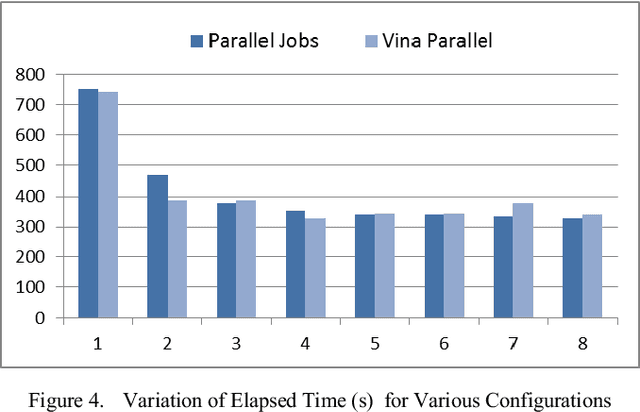
Improving the throughput of molecular docking, a computationally intensive phase of the virtual screening process, is a highly sought area of research since it has a significant weight in the drug designing process. With such improvements, the world might find cures for incurable diseases like HIV disease and Cancer sooner. Our approach presented in this paper is to utilize a multi-core environment to introduce Data Level Parallelism (DLP) to the Autodock Vina software, which is a widely used for molecular docking software. Autodock Vina already exploits Instruction Level Parallelism (ILP) in multi-core environments and therefore optimized for such environments. However, with the results we have obtained, it can be clearly seen that our approach has enhanced the throughput of the already optimized software by more than six times. This will dramatically reduce the time consumed for the lead identification phase in drug designing along with the shift in the processor technology from multi-core to many-core of the current era. Therefore, we believe that the contribution of this project will effectively make it possible to expand the number of small molecules docked against a drug target and improving the chances to design drugs for incurable diseases.