 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Long-Tail Bias via Prompt-Controlled Diffusion Augmentation
Feb 04, 2026Semantic segmentation of high-resolution remote-sensing imagery is critical for urban mapping and land-cover monitoring, yet training data typically exhibits severe long-tailed pixel imbalance. In the dataset LoveDA, this challenge is compounded by an explicit Urban/Rural split with distinct appearance and inconsistent class-frequency statistics across domains. We present a prompt-controlled diffusion augmentation framework that synthesizes paired label--image samples with explicit control of both domain and semantic composition. Stage~A uses a domain-aware, masked ratio-conditioned discrete diffusion model to generate layouts that satisfy user-specified class-ratio targets while respecting learned co-occurrence structure. Stage~B translates layouts into photorealistic, domain-consistent images using Stable Diffusion with ControlNet guidance. Mixing the resulting ratio and domain-controlled synthetic pairs with real data yields consistent improvements across multiple segmentation backbones, with gains concentrated on minority classes and improved Urban and Rural generalization, demonstrating controllable augmentation as a practical mechanism to mitigate long-tail bias in remote-sensing segmentation. Source codes, pretrained models, and synthetic datasets are available at \href{https://github.com/Buddhi19/SyntheticGen.git}{Github}
Mamba-FCS: Joint Spatio- Frequency Feature Fusion, Change-Guided Attention, and SeK Loss for Enhanced Semantic Change Detection in Remote Sensing
Aug 11, 2025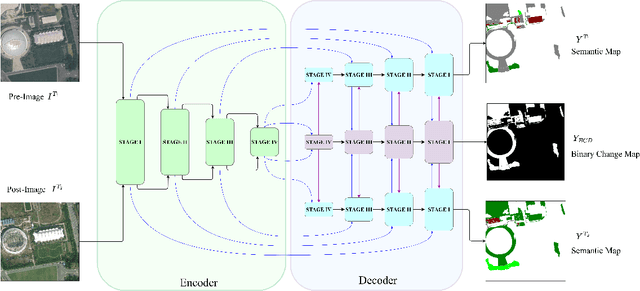
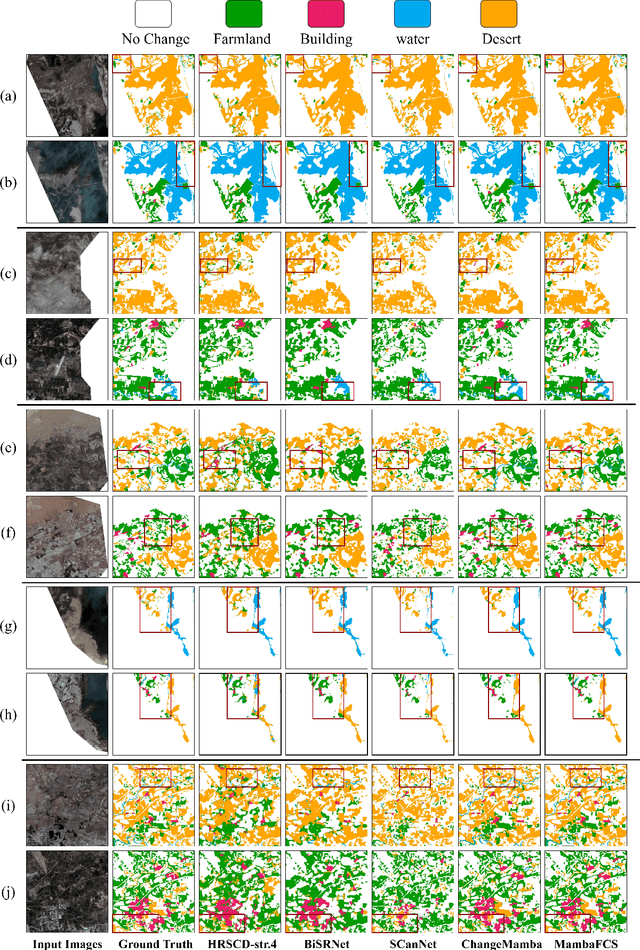
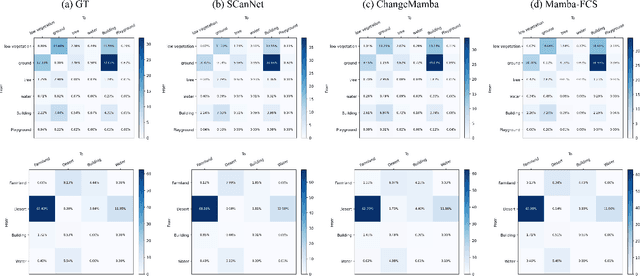
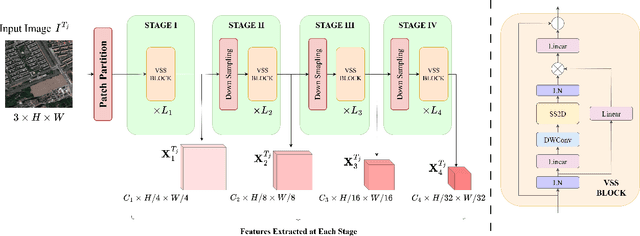
Semantic Change Detection (SCD) from remote sensing imagery requires models balancing extensive spatial context, computational efficiency, and sensitivity to class-imbalanced land-cover transitions. While Convolutional Neural Networks excel at local feature extraction but lack global context, Transformers provide global modeling at high computational costs. Recent Mamba architectures based on state-space models offer compelling solutions through linear complexity and efficient long-range modeling. In this study, we introduce Mamba-FCS, a SCD framework built upon Visual State Space Model backbone incorporating, a Joint Spatio-Frequency Fusion block incorporating log-amplitude frequency domain features to enhance edge clarity and suppress illumination artifacts, a Change-Guided Attention (CGA) module that explicitly links the naturally intertwined BCD and SCD tasks, and a Separated Kappa (SeK) loss tailored for class-imbalanced performance optimization. Extensive evaluation on SECOND and Landsat-SCD datasets shows that Mamba-FCS achieves state-of-the-art metrics, 88.62% Overall Accuracy, 65.78% F_scd, and 25.50% SeK on SECOND, 96.25% Overall Accuracy, 89.27% F_scd, and 60.26% SeK on Landsat-SCD. Ablation analyses confirm distinct contributions of each novel component, with qualitative assessments highlighting significant improvements in SCD. Our results underline the substantial potential of Mamba architectures, enhanced by proposed techniques, setting a new benchmark for effective and scalable semantic change detection in remote sensing applications. The complete source code, configuration files, and pre-trained models will be publicly available upon publication.
Preprocessing Algorithm Leveraging Geometric Modeling for Scale Correction in Hyperspectral Images for Improved Unmixing Performance
Aug 11, 2025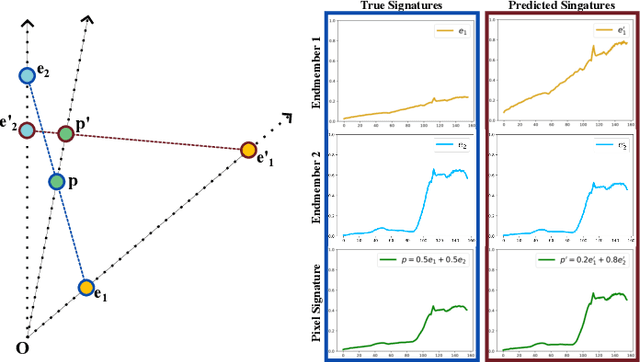
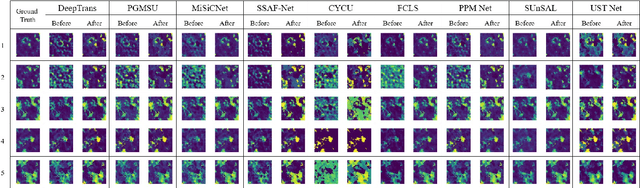
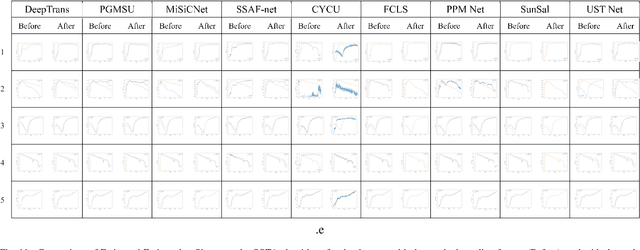
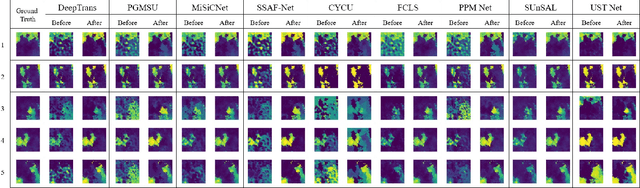
Spectral variability significantly impacts the accuracy and convergence of hyperspectral unmixing algorithms. While many methods address complex spectral variability, large-scale variations in spectral signature scale caused by factors such as topography, illumination, and shadowing remain a major challenge. These variations often degrade unmixing performance and complicate model fitting. In this paper, we propose a novel preprocessing algorithm that corrects scale-induced spectral variability prior to unmixing. By isolating and compensating for these large-scale multiplicative effects, the algorithm provides a cleaner input, enabling unmixing methods to focus more effectively on modeling nonlinear spectral variability and abundance estimation. We present a rigorous mathematical framework to describe scale variability and extensive experimental validation of the proposed algorithm. Furthermore, the algorithm's impact is evaluated across a broad spectrum of state-of-the-art unmixing algorithms on two synthetic and two real hyperspectral datasets. The proposed preprocessing step consistently improves the performance of these algorithms, including those specifically designed to handle spectral variability, with error reductions close to 50% in many cases. This demonstrates that scale correction acts as a complementary step, facilitating more accurate unmixing by existing methods. The algorithm's generality and significant impact highlight its potential as a key component in practical hyperspectral unmixing pipelines. The implementation code will be made publicly available upon publication.
Precision Spatio-Temporal Feature Fusion for Robust Remote Sensing Change Detection
Jul 15, 2025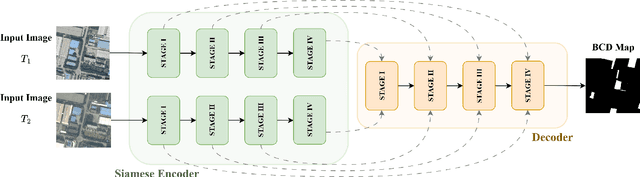
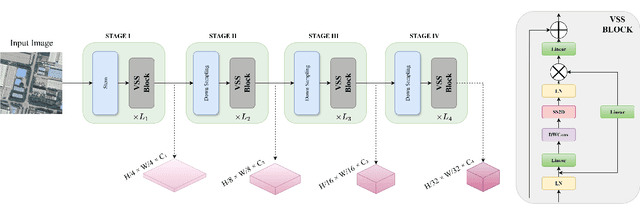
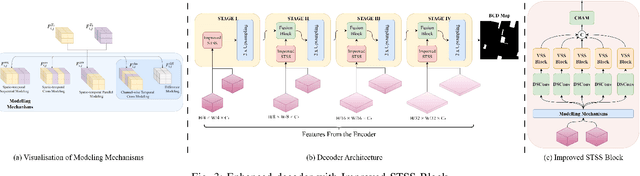

Remote sensing change detection is vital for monitoring environmental and urban transformations but faces challenges like manual feature extraction and sensitivity to noise. Traditional methods and early deep learning models, such as convolutional neural networks (CNNs), struggle to capture long-range dependencies and global context essential for accurate change detection in complex scenes. While Transformer-based models mitigate these issues, their computational complexity limits their applicability in high-resolution remote sensing. Building upon ChangeMamba architecture, which leverages state space models for efficient global context modeling, this paper proposes precision fusion blocks to capture channel-wise temporal variations and per-pixel differences for fine-grained change detection. An enhanced decoder pipeline, incorporating lightweight channel reduction mechanisms, preserves local details with minimal computational cost. Additionally, an optimized loss function combining Cross Entropy, Dice and Lovasz objectives addresses class imbalance and boosts Intersection-over-Union (IoU). Evaluations on SYSU-CD, LEVIR-CD+, and WHU-CD datasets demonstrate superior precision, recall, F1 score, IoU, and overall accuracy compared to state-of-the-art methods, highlighting the approach's robustness for remote sensing change detection. For complete transparency, the codes and pretrained models are accessible at https://github.com/Buddhi19/MambaCD.git
BandRC: Band Shifted Raised Cosine Activated Implicit Neural Representations
May 16, 2025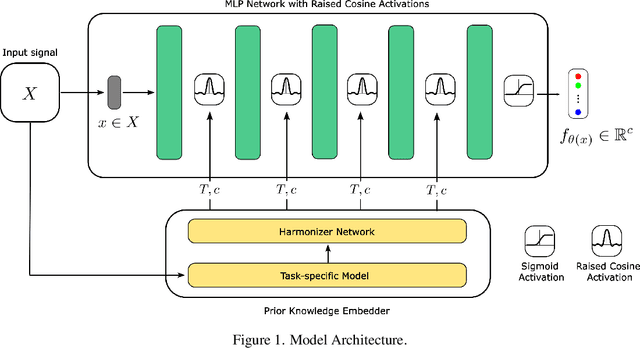
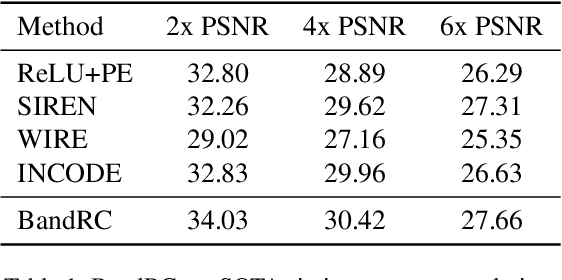

In recent years, implicit neural representations(INRs) have gained popularity in the computer vision community. This is mainly due to the strong performance of INRs in many computer vision tasks. These networks can extract a continuous signal representation given a discrete signal representation. In previous studies, it has been repeatedly shown that INR performance has a strong correlation with the activation functions used in its multilayer perceptrons. Although numerous activation functions have been proposed that are competitive with one another, they share some common set of challenges such as spectral bias(Lack of sensitivity to high-frequency content in signals), limited robustness to signal noise and difficulties in simultaneous capturing both local and global features. and furthermore, the requirement for manual parameter tuning. To address these issues, we introduce a novel activation function, Band Shifted Raised Cosine Activated Implicit Neural Networks \textbf{(BandRC)} tailored to enhance signal representation capacity further. We also incorporate deep prior knowledge extracted from the signal to adjust the activation functions through a task-specific model. Through a mathematical analysis and a series of experiments which include image reconstruction (with a +8.93 dB PSNR improvement over the nearest counterpart), denoising (with a +0.46 dB increase in PSNR), super-resolution (with a +1.03 dB improvement over the nearest State-Of-The-Art (SOTA) method for 6X super-resolution), inpainting, and 3D shape reconstruction we demonstrate the dominance of BandRC over existing state of the art activation functions.
Enhanced SCanNet with CBAM and Dice Loss for Semantic Change Detection
May 07, 2025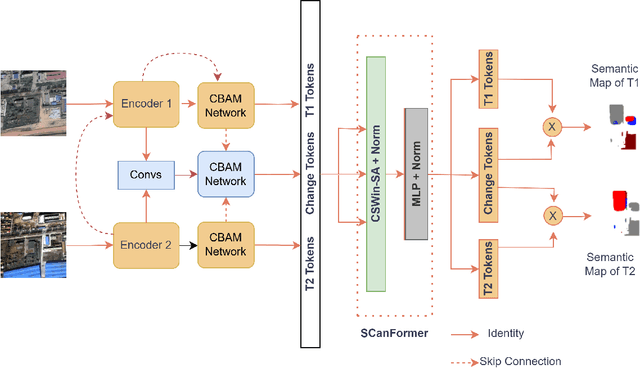
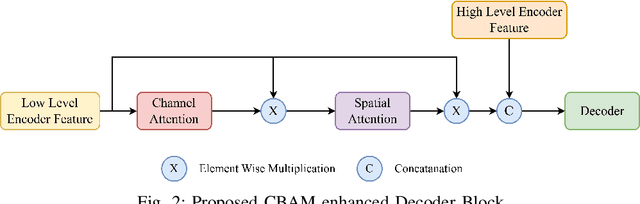

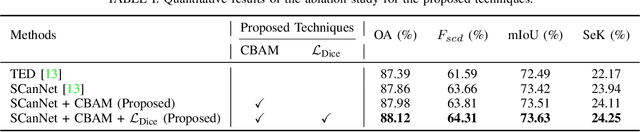
Semantic Change Detection (SCD) in remote sensing imagery requires accurately identifying land-cover changes across multi-temporal image pairs. Despite substantial advancements, including the introduction of transformer-based architectures, current SCD models continue to struggle with challenges such as noisy inputs, subtle class boundaries, and significant class imbalance. In this study, we propose enhancing the Semantic Change Network (SCanNet) by integrating the Convolutional Block Attention Module (CBAM) and employing Dice loss during training. CBAM sequentially applies channel attention to highlight feature maps with the most meaningful content, followed by spatial attention to pinpoint critical regions within these maps. This sequential approach ensures precise suppression of irrelevant features and spatial noise, resulting in more accurate and robust detection performance compared to attention mechanisms that apply both processes simultaneously or independently. Dice loss, designed explicitly for handling class imbalance, further boosts sensitivity to minority change classes. Quantitative experiments conducted on the SECOND dataset demonstrate consistent improvements. Qualitative analysis confirms these improvements, showing clearer segmentation boundaries and more accurate recovery of small-change regions. These findings highlight the effectiveness of attention mechanisms and Dice loss in improving feature representation and addressing class imbalance in semantic change detection tasks.
Performance Benchmarking of Psychomotor Skills Using Wearable Devices: An Application in Sport
Nov 25, 2024
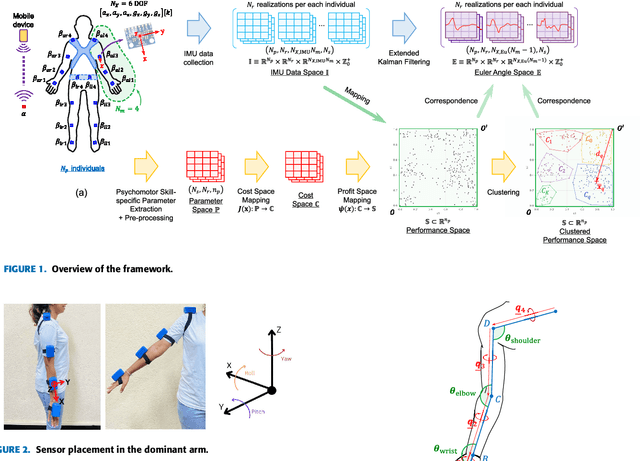


This study proposes a versatile framework for optimizing psychomotor learning through human motion analysis. Utilizing a wearable IMU sensor system, the motion trajectories of a given psychomotor task are acquired and then linked to points in a performance space using a predefined set of quality metrics specific to the psychomotor skill. This enables the identification of a benchmark cluster in the performance space, allowing correspondences to be established between the performance clusters and sets of trajectories in the motion space. As a result, common or specific deviations in the performance space can be identified, enabling remedial actions in the motion space to optimize performance. A thorough validation of the proposed framework is done in this paper using a Table Tennis forehand stroke as a case study. The resulting quantitative and visual representation of performance empowers individuals to optimize their skills and achieve peak performance.
Iso-Diffusion: Improving Diffusion Probabilistic Models Using the Isotropy of the Additive Gaussian Noise
Mar 25, 2024Denoising Diffusion Probabilistic Models (DDPMs) have accomplished much in the realm of generative AI. Despite their high performance, there is room for improvement, especially in terms of sample fidelity by utilizing statistical properties that impose structural integrity, such as isotropy. Minimizing the mean squared error between the additive and predicted noise alone does not impose constraints on the predicted noise to be isotropic. Thus, we were motivated to utilize the isotropy of the additive noise as a constraint on the objective function to enhance the fidelity of DDPMs. Our approach is simple and can be applied to any DDPM variant. We validate our approach by presenting experiments conducted on four synthetic 2D datasets as well as on unconditional image generation. As demonstrated by the results, the incorporation of this constraint improves the fidelity metrics, Precision and Density for the 2D datasets as well as for the unconditional image generation.
GAUSS: Guided Encoder-Decoder Architecture for Hyperspectral Unmixing with Spatial Smoothness
Apr 16, 2022
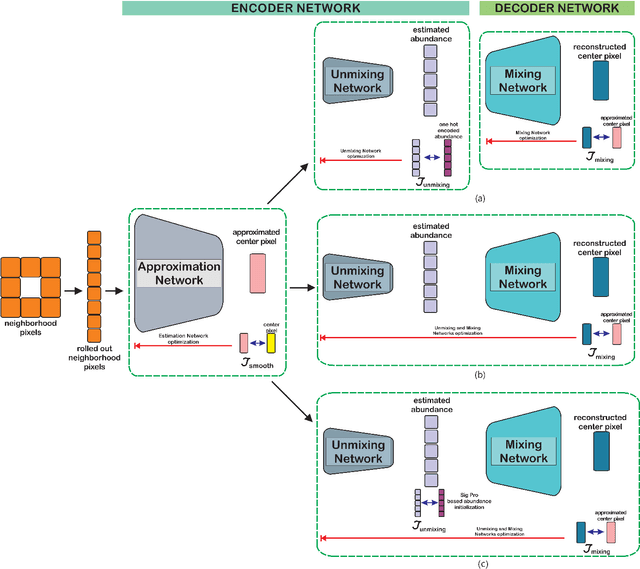

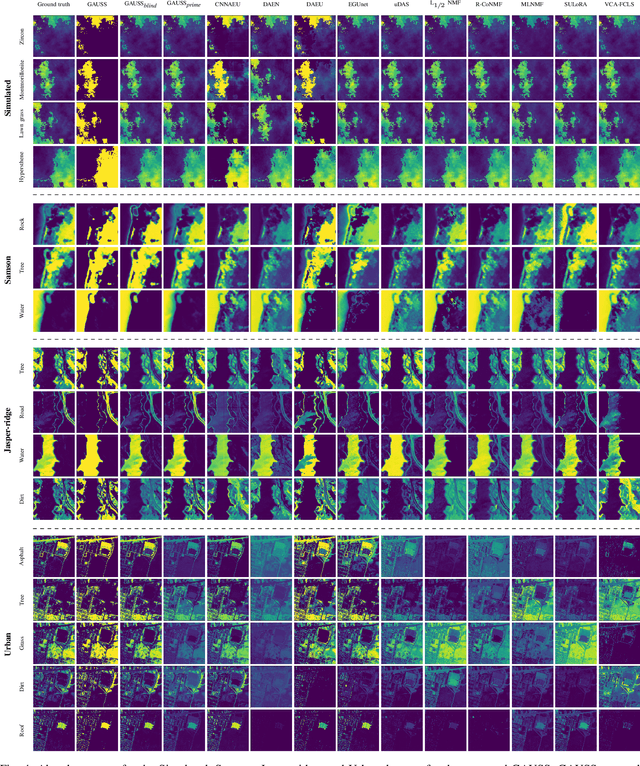
In recent hyperspectral unmixing (HU) literature, the application of deep learning (DL) has become more prominent, especially with the autoencoder (AE) architecture. We propose a split architecture and use a pseudo-ground truth for abundances to guide the `unmixing network' (UN) optimization. Preceding the UN, an `approximation network' (AN) is proposed, which will improve the association between the centre pixel and its neighbourhood. Hence, it will accentuate spatial correlation in the abundances as its output is the input to the UN and the reference for the `mixing network' (MN). In the Guided Encoder-Decoder Architecture for Hyperspectral Unmixing with Spatial Smoothness (GAUSS), we proposed using one-hot encoded abundances as the pseudo-ground truth to guide the UN; computed using the k-means algorithm to exclude the use of prior HU methods. Furthermore, we release the single-layer constraint on MN by introducing the UN generated abundances in contrast to the standard AE for HU. Secondly, we experimented with two modifications on the pre-trained network using the GAUSS method. In GAUSS$_\textit{blind}$, we have concatenated the UN and the MN to back-propagate the reconstruction error gradients to the encoder. Then, in the GAUSS$_\textit{prime}$, abundance results of a signal processing (SP) method with reliable abundance results were used as the pseudo-ground truth with the GAUSS architecture. According to quantitative and graphical results for four experimental datasets, the three architectures either transcended or equated the performance of existing HU algorithms from both DL and SP domains.
Holistic Interpretation of Public Scenes Using Computer Vision and Temporal Graphs to Identify Social Distancing Violations
Dec 13, 2021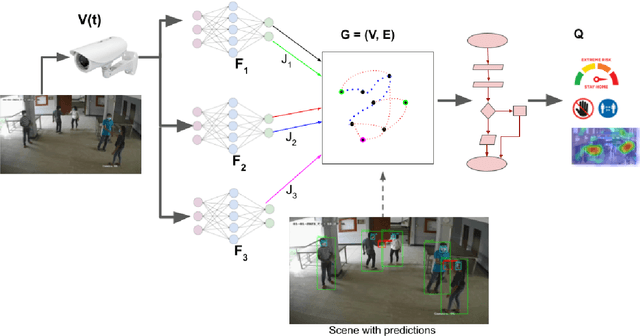

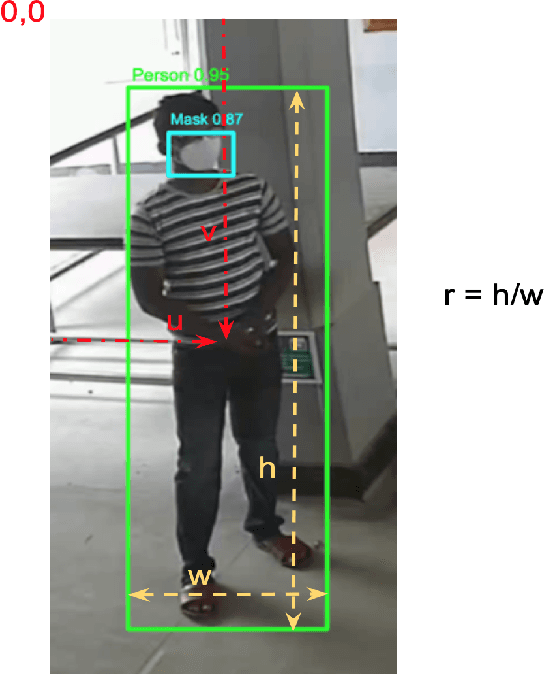

The COVID-19 pandemic has caused an unprecedented global public health crisis. Given its inherent nature, social distancing measures are proposed as the primary strategies to curb the spread of this pandemic. Therefore, identifying situations where these protocols are violated, has implications for curtailing the spread of the disease and promoting a sustainable lifestyle. This paper proposes a novel computer vision-based system to analyze CCTV footage to provide a threat level assessment of COVID-19 spread. The system strives to holistically capture and interpret the information content of CCTV footage spanning multiple frames to recognize instances of various violations of social distancing protocols, across time and space, as well as identification of group behaviors. This functionality is achieved primarily by utilizing a temporal graph-based structure to represent the information of the CCTV footage and a strategy to holistically interpret the graph and quantify the threat level of the given scene. The individual components are tested and validated on a range of scenarios and the complete system is tested against human expert opinion. The results reflect the dependence of the threat level on people, their physical proximity, interactions, protective clothing, and group dynamics. The system performance has an accuracy of 76%, thus enabling a deployable threat monitoring system in cities, to permit normalcy and sustainability in the society.