 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEv-Edge: Efficient Execution of Event-based Vision Algorithms on Commodity Edge Platforms
Mar 23, 2024Event cameras have emerged as a promising sensing modality for autonomous navigation systems, owing to their high temporal resolution, high dynamic range and negligible motion blur. To process the asynchronous temporal event streams from such sensors, recent research has shown that a mix of Artificial Neural Networks (ANNs), Spiking Neural Networks (SNNs) as well as hybrid SNN-ANN algorithms are necessary to achieve high accuracies across a range of perception tasks. However, we observe that executing such workloads on commodity edge platforms which feature heterogeneous processing elements such as CPUs, GPUs and neural accelerators results in inferior performance. This is due to the mismatch between the irregular nature of event streams and diverse characteristics of algorithms on the one hand and the underlying hardware platform on the other. We propose Ev-Edge, a framework that contains three key optimizations to boost the performance of event-based vision systems on edge platforms: (1) An Event2Sparse Frame converter directly transforms raw event streams into sparse frames, enabling the use of sparse libraries with minimal encoding overheads (2) A Dynamic Sparse Frame Aggregator merges sparse frames at runtime by trading off the temporal granularity of events and computational demand thereby improving hardware utilization (3) A Network Mapper maps concurrently executing tasks to different processing elements while also selecting layer precision by considering both compute and communication overheads. On several state-of-art networks for a range of autonomous navigation tasks, Ev-Edge achieves 1.28x-2.05x improvements in latency and 1.23x-2.15x in energy over an all-GPU implementation on the NVIDIA Jetson Xavier AGX platform for single-task execution scenarios. Ev-Edge also achieves 1.43x-1.81x latency improvements over round-robin scheduling methods in multi-task execution scenarios.
X-Former: In-Memory Acceleration of Transformers
Mar 13, 2023Transformers have achieved great success in a wide variety of natural language processing (NLP) tasks due to the attention mechanism, which assigns an importance score for every word relative to other words in a sequence. However, these models are very large, often reaching hundreds of billions of parameters, and therefore require a large number of DRAM accesses. Hence, traditional deep neural network (DNN) accelerators such as GPUs and TPUs face limitations in processing Transformers efficiently. In-memory accelerators based on non-volatile memory promise to be an effective solution to this challenge, since they provide high storage density while performing massively parallel matrix vector multiplications within memory arrays. However, attention score computations, which are frequently used in Transformers (unlike CNNs and RNNs), require matrix vector multiplications (MVM) where both operands change dynamically for each input. As a result, conventional NVM-based accelerators incur high write latency and write energy when used for Transformers, and further suffer from the low endurance of most NVM technologies. To address these challenges, we present X-Former, a hybrid in-memory hardware accelerator that consists of both NVM and CMOS processing elements to execute transformer workloads efficiently. To improve the hardware utilization of X-Former, we also propose a sequence blocking dataflow, which overlaps the computations of the two processing elements and reduces execution time. Across several benchmarks, we show that X-Former achieves upto 85x and 7.5x improvements in latency and energy over a NVIDIA GeForce GTX 1060 GPU and upto 10.7x and 4.6x improvements in latency and energy over a state-of-the-art in-memory NVM accelerator.
TxSim:Modeling Training of Deep Neural Networks on Resistive Crossbar Systems
Feb 25, 2020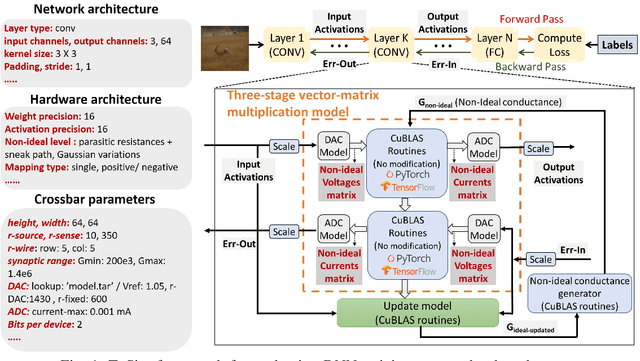
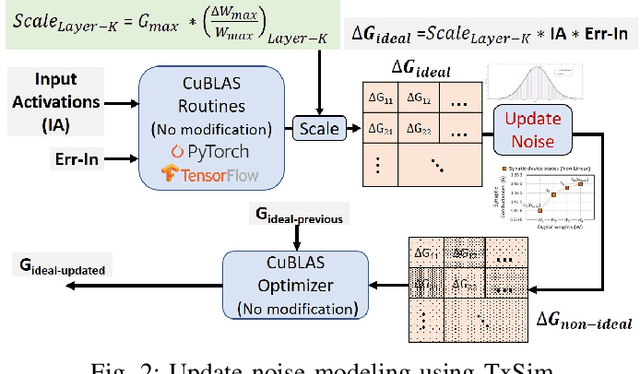
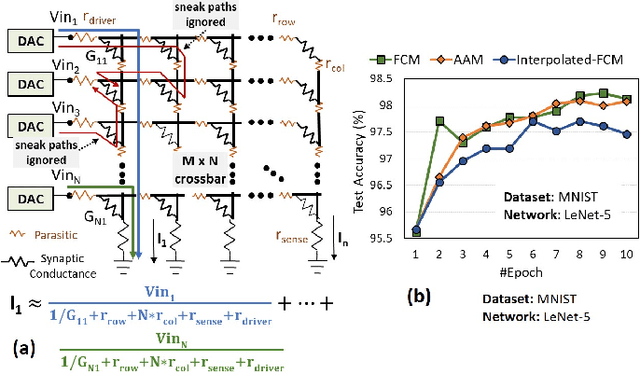
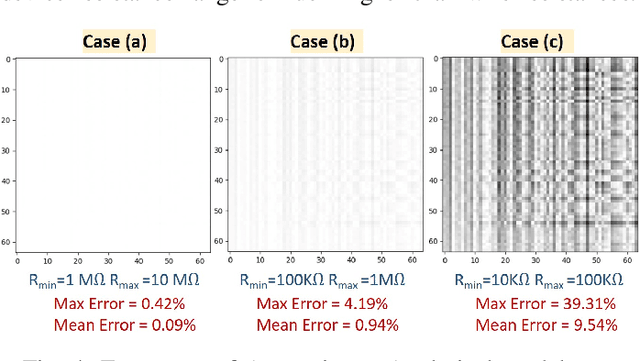
Resistive crossbars have attracted significant interest in the design of Deep Neural Network (DNN) accelerators due to their ability to natively execute massively parallel vector-matrix multiplications within dense memory arrays. However, crossbar-based computations face a major challenge due to a variety of device and circuit-level non-idealities, which manifest as errors in the vector-matrix multiplications and eventually degrade DNN accuracy. To address this challenge, there is a need for tools that can model the functional impact of non-idealities on DNN training and inference. Existing efforts towards this goal are either limited to inference, or are too slow to be used for large-scale DNN training. We propose TxSim, a fast and customizable modeling framework to functionally evaluate DNN training on crossbar-based hardware considering the impact of non-idealities. The key features of TxSim that differentiate it from prior efforts are: (i) It comprehensively models non-idealities during all training operations (forward propagation, backward propagation, and weight update) and (ii) it achieves computational efficiency by mapping crossbar evaluations to well-optimized BLAS routines and incorporates speedup techniques to further reduce simulation time with minimal impact on accuracy. TxSim achieves orders-of-magnitude improvement in simulation speed over prior works, and thereby makes it feasible to evaluate training of large-scale DNNs on crossbars. Our experiments using TxSim reveal that the accuracy degradation in DNN training due to non-idealities can be substantial (3%-10%) for large-scale DNNs, underscoring the need for further research in mitigation techniques. We also analyze the impact of various device and circuit-level parameters and the associated non-idealities to provide key insights that can guide the design of crossbar-based DNN training accelerators.