 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of STT-MRAM as a Scratchpad for Training in ML Accelerators
Aug 03, 2023Progress in artificial intelligence and machine learning over the past decade has been driven by the ability to train larger deep neural networks (DNNs), leading to a compute demand that far exceeds the growth in hardware performance afforded by Moore's law. Training DNNs is an extremely memory-intensive process, requiring not just the model weights but also activations and gradients for an entire minibatch to be stored. The need to provide high-density and low-leakage on-chip memory motivates the exploration of emerging non-volatile memory for training accelerators. Spin-Transfer-Torque MRAM (STT-MRAM) offers several desirable properties for training accelerators, including 3-4x higher density than SRAM, significantly reduced leakage power, high endurance and reasonable access time. On the one hand, MRAM write operations require high write energy and latency due to the need to ensure reliable switching. In this study, we perform a comprehensive device-to-system evaluation and co-optimization of STT-MRAM for efficient ML training accelerator design. We devised a cross-layer simulation framework to evaluate the effectiveness of STT-MRAM as a scratchpad replacing SRAM in a systolic-array-based DNN accelerator. To address the inefficiency of writes in STT-MRAM, we propose to reduce write voltage and duration. To evaluate the ensuing accuracy-efficiency trade-off, we conduct a thorough analysis of the error tolerance of input activations, weights, and errors during the training. We propose heterogeneous memory configurations that enable training convergence with good accuracy. We show that MRAM provide up to 15-22x improvement in system level energy across a suite of DNN benchmarks under iso-capacity and iso-area scenarios. Further optimizing STT-MRAM write operations can provide over 2x improvement in write energy for minimal degradation in application-level training accuracy.
PIM-DRAM: Accelerating Machine Learning Workloads using Processing in Commodity DRAM
May 14, 2021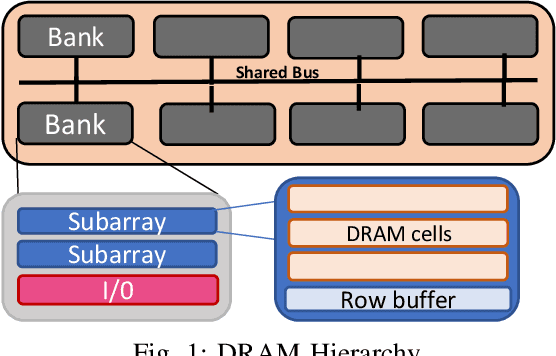
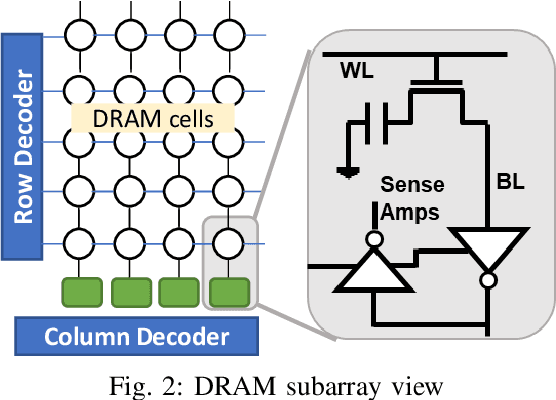
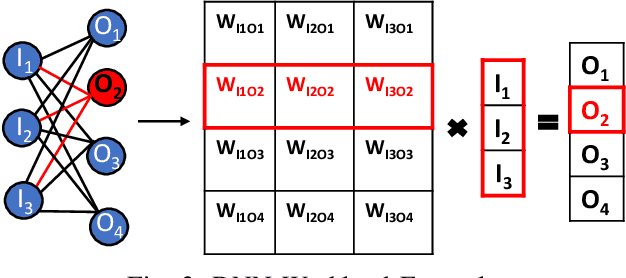
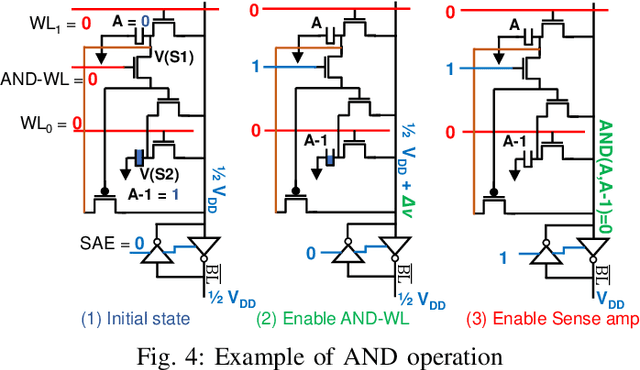
Deep Neural Networks (DNNs) have transformed the field of machine learning and are widely deployed in many applications involving image, video, speech and natural language processing. The increasing compute demands of DNNs have been widely addressed through Graphics Processing Units (GPUs) and specialized accelerators. However, as model sizes grow, these von Neumann architectures require very high memory bandwidth to keep the processing elements utilized as a majority of the data resides in the main memory. Processing in memory has been proposed as a promising solution for the memory wall bottleneck for ML workloads. In this work, we propose a new DRAM-based processing-in-memory (PIM) multiplication primitive coupled with intra-bank accumulation to accelerate matrix vector operations in ML workloads. The proposed multiplication primitive adds < 1% area overhead and does not require any change in the DRAM peripherals. Therefore, the proposed multiplication can be easily adopted in commodity DRAM chips. Subsequently, we design a DRAM-based PIM architecture, data mapping scheme and dataflow for executing DNNs within DRAM. System evaluations performed on networks like AlexNet, VGG16 and ResNet18 show that the proposed architecture, mapping, and data flow can provide up to 23x speedup over an NVIDIA Titan Xp GPU. Furthermore, it achieves upto 6.5x speedup over an ideal von Neumann architecture with infinite computational throughput, highlighting the need to overcome the memory bottleneck in future generations of DNN hardware.
Pruning Filters while Training for Efficiently Optimizing Deep Learning Networks
Mar 05, 2020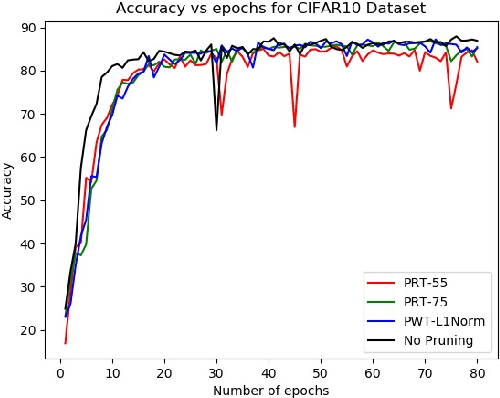
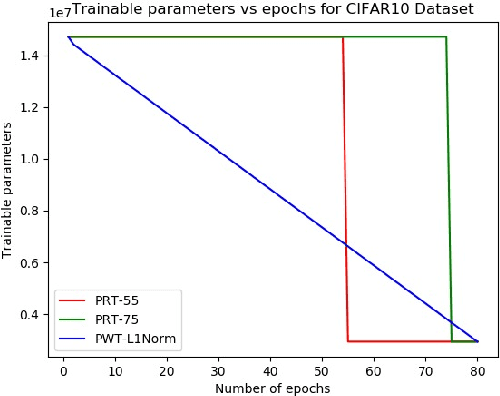
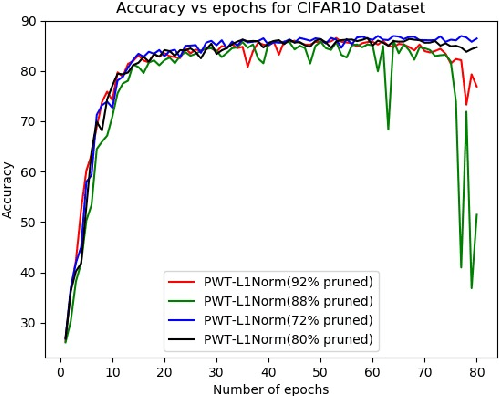
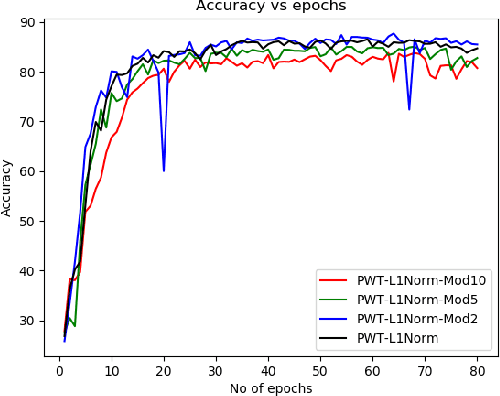
Modern deep networks have millions to billions of parameters, which leads to high memory and energy requirements during training as well as during inference on resource-constrained edge devices. Consequently, pruning techniques have been proposed that remove less significant weights in deep networks, thereby reducing their memory and computational requirements. Pruning is usually performed after training the original network, and is followed by further retraining to compensate for the accuracy loss incurred during pruning. The prune-and-retrain procedure is repeated iteratively until an optimum tradeoff between accuracy and efficiency is reached. However, such iterative retraining adds to the overall training complexity of the network. In this work, we propose a dynamic pruning-while-training procedure, wherein we prune filters of the convolutional layers of a deep network during training itself, thereby precluding the need for separate retraining. We evaluate our dynamic pruning-while-training approach with three different pre-existing pruning strategies, viz. mean activation-based pruning, random pruning, and L1 normalization-based pruning. Our results for VGG-16 trained on CIFAR10 shows that L1 normalization provides the best performance among all the techniques explored in this work with less than 1% drop in accuracy after pruning 80% of the filters compared to the original network. We further evaluated the L1 normalization based pruning mechanism on CIFAR100. Results indicate that pruning while training yields a compressed network with almost no accuracy loss after pruning 50% of the filters compared to the original network and ~5% loss for high pruning rates (>80%). The proposed pruning methodology yields 41% reduction in the number of computations and memory accesses during training for CIFAR10, CIFAR100 and ImageNet compared to training with retraining for 10 epochs .
TxSim:Modeling Training of Deep Neural Networks on Resistive Crossbar Systems
Feb 25, 2020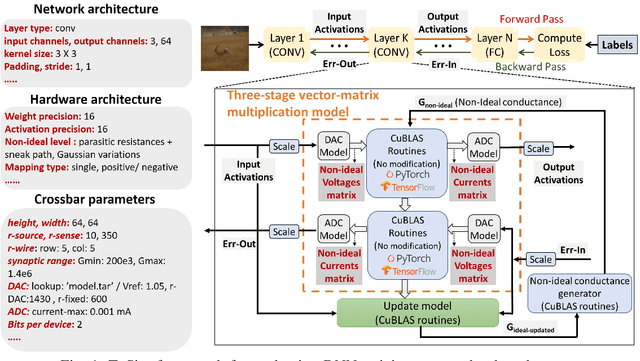
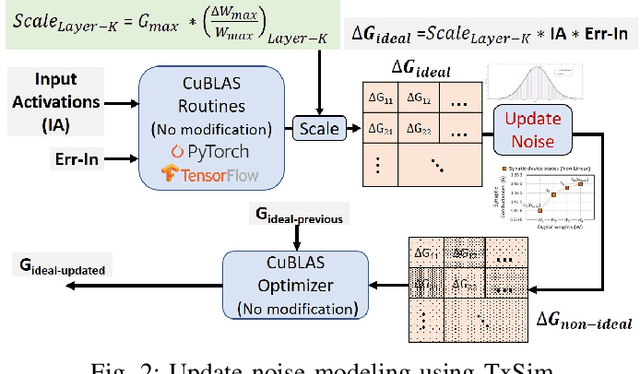
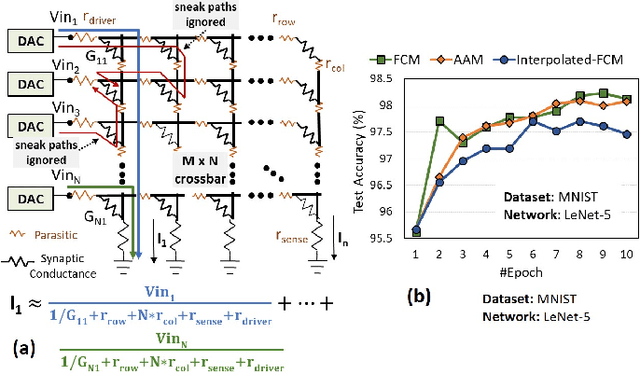
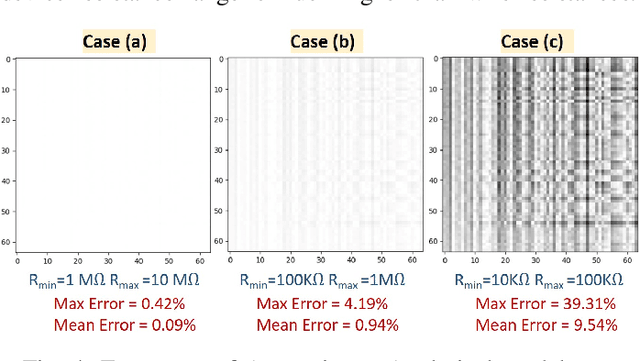
Resistive crossbars have attracted significant interest in the design of Deep Neural Network (DNN) accelerators due to their ability to natively execute massively parallel vector-matrix multiplications within dense memory arrays. However, crossbar-based computations face a major challenge due to a variety of device and circuit-level non-idealities, which manifest as errors in the vector-matrix multiplications and eventually degrade DNN accuracy. To address this challenge, there is a need for tools that can model the functional impact of non-idealities on DNN training and inference. Existing efforts towards this goal are either limited to inference, or are too slow to be used for large-scale DNN training. We propose TxSim, a fast and customizable modeling framework to functionally evaluate DNN training on crossbar-based hardware considering the impact of non-idealities. The key features of TxSim that differentiate it from prior efforts are: (i) It comprehensively models non-idealities during all training operations (forward propagation, backward propagation, and weight update) and (ii) it achieves computational efficiency by mapping crossbar evaluations to well-optimized BLAS routines and incorporates speedup techniques to further reduce simulation time with minimal impact on accuracy. TxSim achieves orders-of-magnitude improvement in simulation speed over prior works, and thereby makes it feasible to evaluate training of large-scale DNNs on crossbars. Our experiments using TxSim reveal that the accuracy degradation in DNN training due to non-idealities can be substantial (3%-10%) for large-scale DNNs, underscoring the need for further research in mitigation techniques. We also analyze the impact of various device and circuit-level parameters and the associated non-idealities to provide key insights that can guide the design of crossbar-based DNN training accelerators.
Gradual Channel Pruning while Training using Feature Relevance Scores for Convolutional Neural Networks
Feb 23, 2020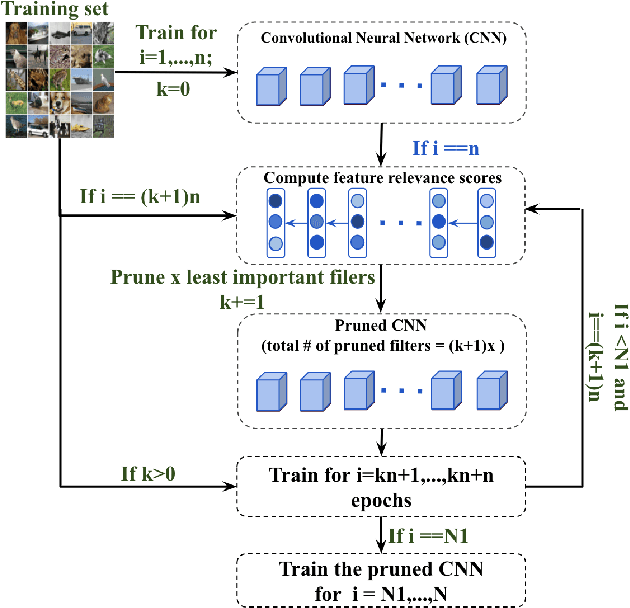
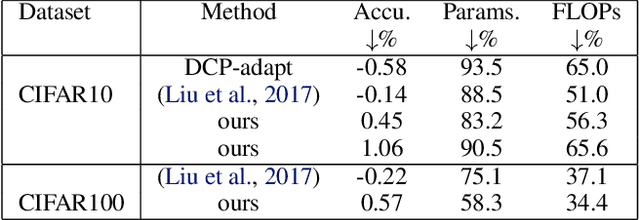
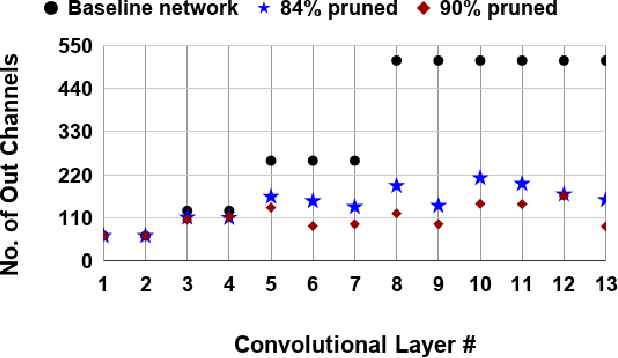
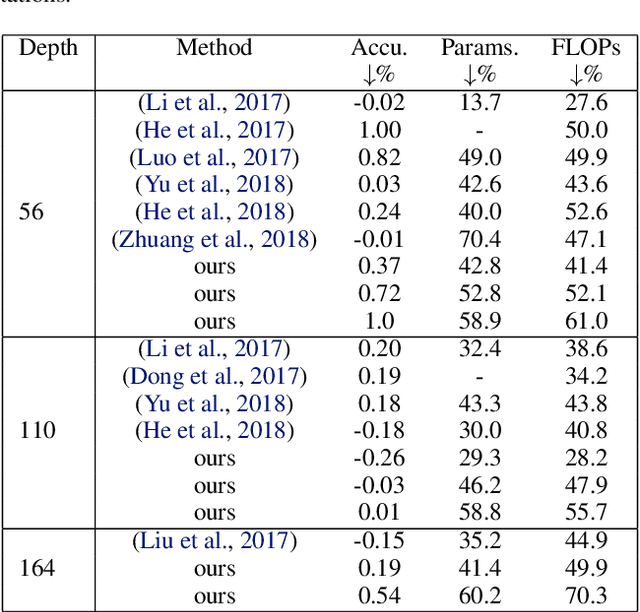
The enormous inference cost of deep neural networks can be scaled down by network compression. Pruning is one of the predominant approaches used for deep network compression. However, existing pruning techniques have one or more of the following limitations: 1) Additional energy cost on top of the compute heavy training stage due to pruning and fine-tuning stages, 2) Layer-wise pruning based on the statistics of a particular, ignoring the effect of error propagation in the network, 3) Lack of an efficient estimate for determining the important channels globally, 4) Unstructured pruning requires specialized hardware for effective use. To address all the above issues, we present a simple-yet-effective gradual channel pruning while training methodology using a novel data driven metric referred as Feature relevance score. The proposed technique gets rid of the additional retraining cycles by pruning least important channels in a structured fashion at fixed intervals during the actual training phase. Feature relevance scores help in efficiently evaluating the contribution of each channel towards the discriminative power of the network. We demonstrate the effectiveness of the proposed methodology on architectures such as VGG and ResNet using datasets such as CIFAR-10, CIFAR-100 and ImageNet, and successfully achieve significant model compression while trading off less than $1\%$ accuracy. Notably on CIFAR-10 dataset trained on ResNet-110, our approach achieves $2.4\times$ compression and a $56\%$ reduction in FLOPs with an accuracy drop of $0.01\%$ compared to the unpruned network.
Proposal for a Leaky-Integrate-Fire Spiking Neuron based on Magneto-Electric Switching of Ferro-magnets
Sep 29, 2016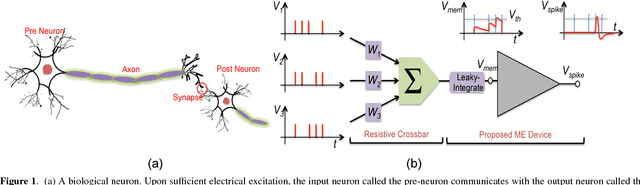
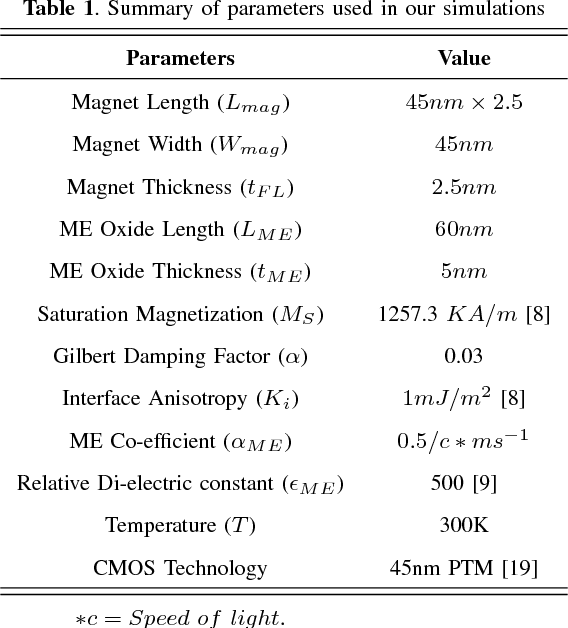
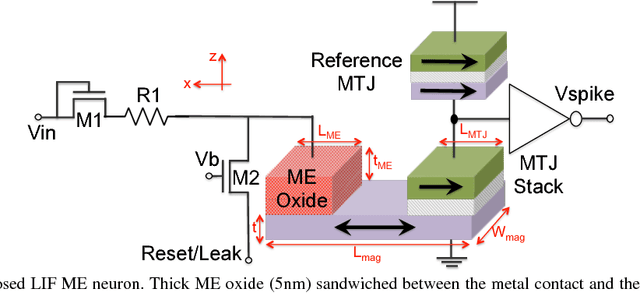
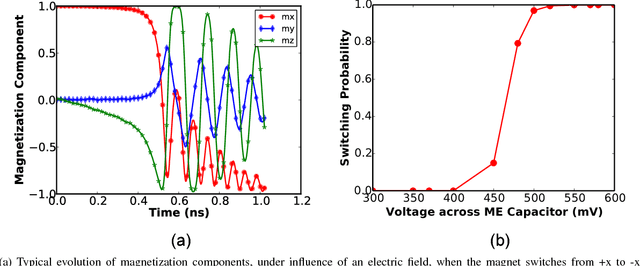
The efficiency of the human brain in performing classification tasks has attracted considerable research interest in brain-inspired neuromorphic computing. Hardware implementations of a neuromorphic system aims to mimic the computations in the brain through interconnection of neurons and synaptic weights. A leaky-integrate-fire (LIF) spiking model is widely used to emulate the dynamics of neuronal action potentials. In this work, we propose a spin based LIF spiking neuron using the magneto-electric (ME) switching of ferro-magnets. The voltage across the ME oxide exhibits a typical leaky-integrate behavior, which in turn switches an underlying ferro-magnet. Due to the effect of thermal noise, the ferro-magnet exhibits probabilistic switching dynamics, which is reminiscent of the stochasticity exhibited by biological neurons. The energy-efficiency of the ME switching mechanism coupled with the intrinsic non-volatility of ferro-magnets result in lower energy consumption, when compared to a CMOS LIF neuron. A device to system-level simulation framework has been developed to investigate the feasibility of the proposed LIF neuron for a hand-written digit recognition problem