 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuroFlex: Column-Exact ANN-SNN Co-Execution Accelerator with Cost-Guided Scheduling
Nov 07, 2025



NeuroFlex is a column-level accelerator that co-executes artificial and spiking neural networks to minimize energy-delay product on sparse edge workloads with competitive accuracy. The design extends integer-exact QCFS ANN-SNN conversion from layers to independent columns. It unifies INT8 storage with on-the-fly spike generation using an offline cost model to assign columns to ANN or SNN cores and pack work across processing elements with deterministic runtime. Our cost-guided scheduling algorithm improves throughput by 16-19% over random mapping and lowers EDP by 57-67% versus a strong ANN-only baseline across VGG-16, ResNet-34, GoogLeNet, and BERT models. NeuroFlex also delivers up to 2.5x speedup over LoAS and 2.51x energy reduction over SparTen. These results indicate that fine-grained and integer-exact hybridization outperforms single-mode designs on energy and latency without sacrificing accuracy.
PASCAL: Precise and Efficient ANN- SNN Conversion using Spike Accumulation and Adaptive Layerwise Activation
May 03, 2025
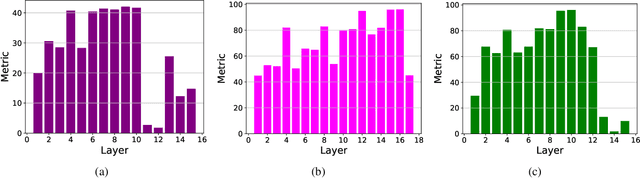


Spiking Neural Networks (SNNs) have been put forward as an energy-efficient alternative to Artificial Neural Networks (ANNs) since they perform sparse Accumulate operations instead of the power-hungry Multiply-and-Accumulate operations. ANN-SNN conversion is a widely used method to realize deep SNNs with accuracy comparable to that of ANNs.~\citeauthor{bu2023optimal} recently proposed the Quantization-Clip-Floor-Shift (QCFS) activation as an alternative to ReLU to minimize the accuracy loss during ANN-SNN conversion. Nevertheless, SNN inferencing requires a large number of timesteps to match the accuracy of the source ANN for real-world datasets. In this work, we propose PASCAL, which performs ANN-SNN conversion in such a way that the resulting SNN is mathematically equivalent to an ANN with QCFS-activation, thereby yielding similar accuracy as the source ANN with minimal inference timesteps. In addition, we propose a systematic method to configure the quantization step of QCFS activation in a layerwise manner, which effectively determines the optimal number of timesteps per layer for the converted SNN. Our results show that the ResNet-34 SNN obtained using PASCAL achieves an accuracy of $\approx$74\% on ImageNet with a 64$\times$ reduction in the number of inference timesteps compared to existing approaches.
QuAKE: Speeding up Model Inference Using Quick and Approximate Kernels for Exponential Non-Linearities
Nov 30, 2024
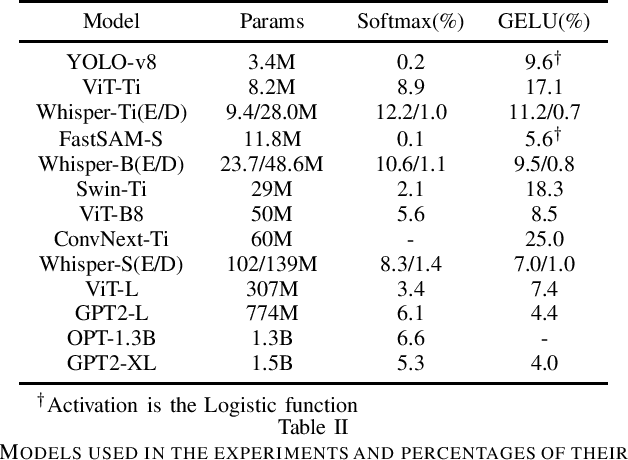
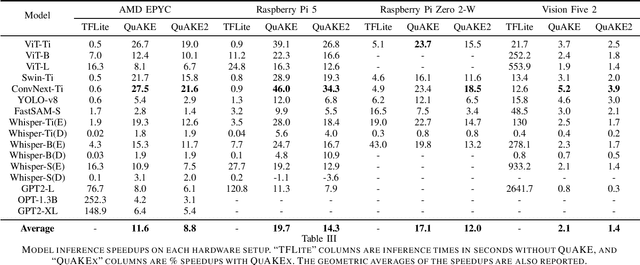
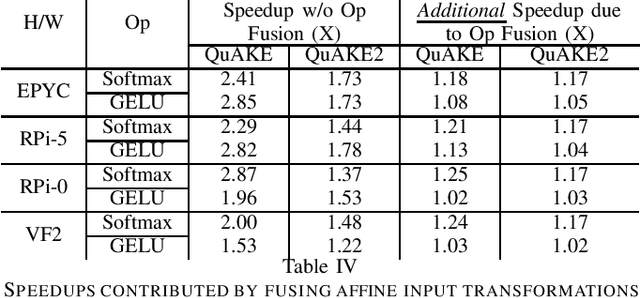
As machine learning gets deployed more and more widely, and model sizes continue to grow, improving computational efficiency during model inference has become a key challenge. In many commonly used model architectures, including Transformers, a significant portion of the inference computation is comprised of exponential non-linearities such as Softmax. In this work, we develop QuAKE, a collection of novel operators that leverage certain properties of IEEE-754 floating point representations to quickly approximate the exponential function without requiring specialized hardware, extra memory, or precomputation. We propose optimizations that enhance the efficiency of QuAKE in commonly used exponential non-linearities such as Softmax, GELU, and the Logistic function. Our benchmarks demonstrate substantial inference speed improvements between 10% and 35% on server CPUs, and 5% and 45% on embedded and mobile-scale CPUs for a variety of model architectures and sizes. Evaluations of model performance on standard datasets and tasks from various domains show that QuAKE operators are able to provide sizable speed benefits with little to no loss of performance on downstream tasks.
Complexity-aware Adaptive Training and Inference for Edge-Cloud Distributed AI Systems
Sep 14, 2021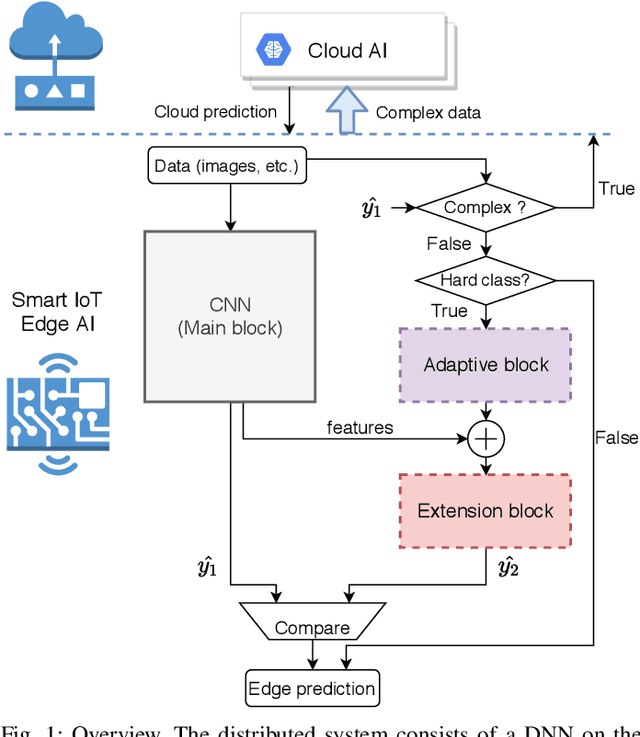
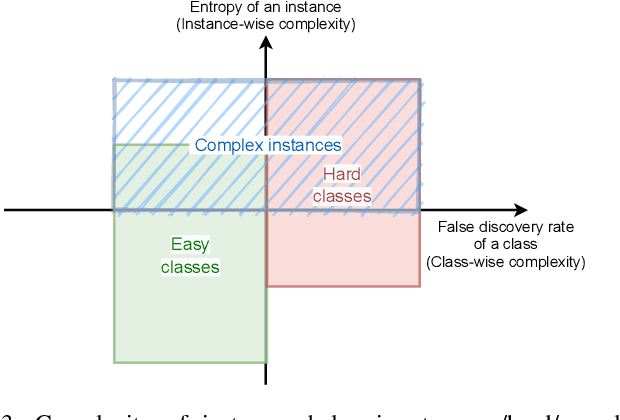
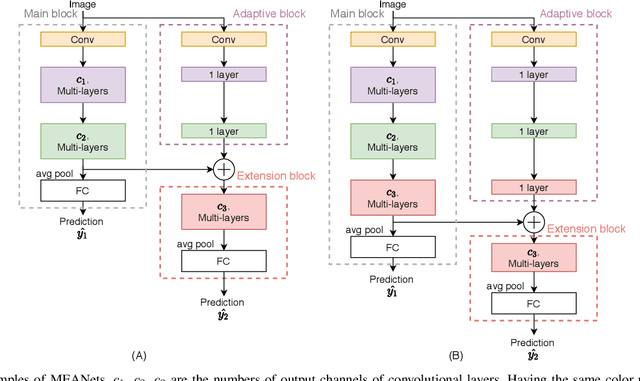
The ubiquitous use of IoT and machine learning applications is creating large amounts of data that require accurate and real-time processing. Although edge-based smart data processing can be enabled by deploying pretrained models, the energy and memory constraints of edge devices necessitate distributed deep learning between the edge and the cloud for complex data. In this paper, we propose a distributed AI system to exploit both the edge and the cloud for training and inference. We propose a new architecture, MEANet, with a main block, an extension block, and an adaptive block for the edge. The inference process can terminate at either the main block, the extension block, or the cloud. The MEANet is trained to categorize inputs into easy/hard/complex classes. The main block identifies instances of easy/hard classes and classifies easy classes with high confidence. Only data with high probabilities of belonging to hard classes would be sent to the extension block for prediction. Further, only if the neural network at the edge shows low confidence in the prediction, the instance is considered complex and sent to the cloud for further processing. The training technique lends to the majority of inference on edge devices while going to the cloud only for a small set of complex jobs, as determined by the edge. The performance of the proposed system is evaluated via extensive experiments using modified models of ResNets and MobileNetV2 on CIFAR-100 and ImageNet datasets. The results show that the proposed distributed model has improved accuracy and energy consumption, indicating its capacity to adapt.
Enabling Deep Spiking Neural Networks with Hybrid Conversion and Spike Timing Dependent Backpropagation
May 04, 2020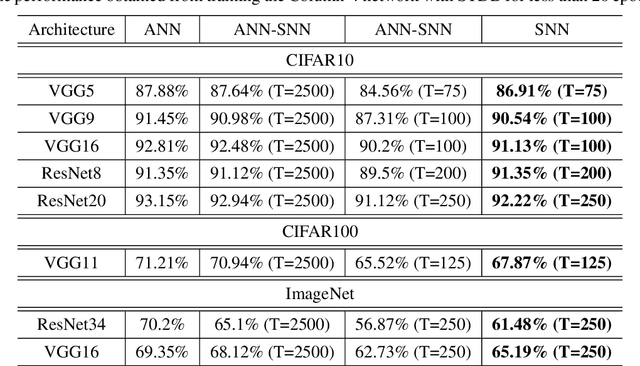
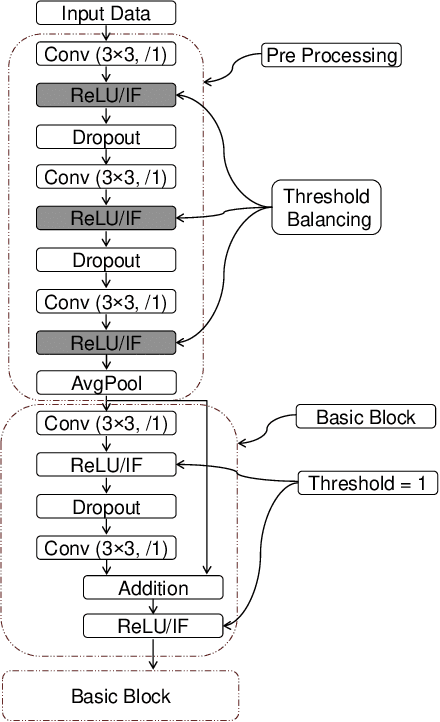
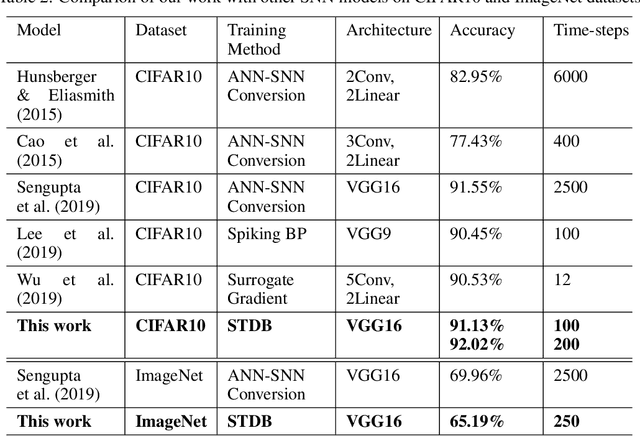
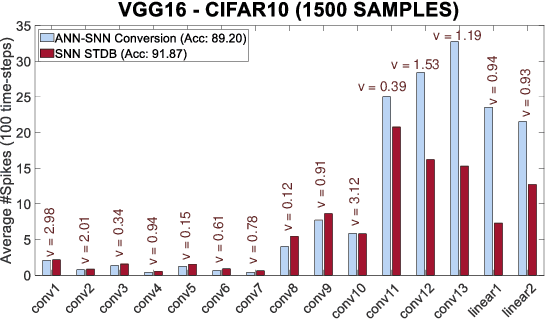
Spiking Neural Networks (SNNs) operate with asynchronous discrete events (or spikes) which can potentially lead to higher energy-efficiency in neuromorphic hardware implementations. Many works have shown that an SNN for inference can be formed by copying the weights from a trained Artificial Neural Network (ANN) and setting the firing threshold for each layer as the maximum input received in that layer. These type of converted SNNs require a large number of time steps to achieve competitive accuracy which diminishes the energy savings. The number of time steps can be reduced by training SNNs with spike-based backpropagation from scratch, but that is computationally expensive and slow. To address these challenges, we present a computationally-efficient training technique for deep SNNs. We propose a hybrid training methodology: 1) take a converted SNN and use its weights and thresholds as an initialization step for spike-based backpropagation, and 2) perform incremental spike-timing dependent backpropagation (STDB) on this carefully initialized network to obtain an SNN that converges within few epochs and requires fewer time steps for input processing. STDB is performed with a novel surrogate gradient function defined using neuron's spike time. The proposed training methodology converges in less than 20 epochs of spike-based backpropagation for most standard image classification datasets, thereby greatly reducing the training complexity compared to training SNNs from scratch. We perform experiments on CIFAR-10, CIFAR-100, and ImageNet datasets for both VGG and ResNet architectures. We achieve top-1 accuracy of 65.19% for ImageNet dataset on SNN with 250 time steps, which is 10X faster compared to converted SNNs with similar accuracy.
Pruning Filters while Training for Efficiently Optimizing Deep Learning Networks
Mar 05, 2020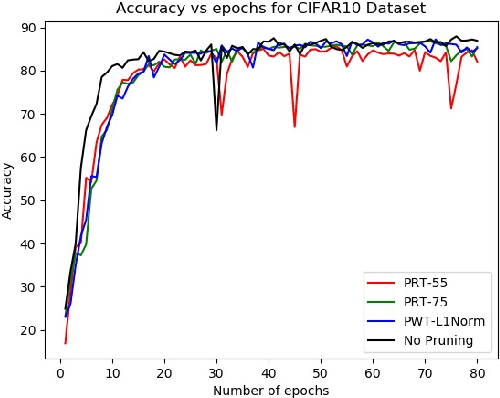
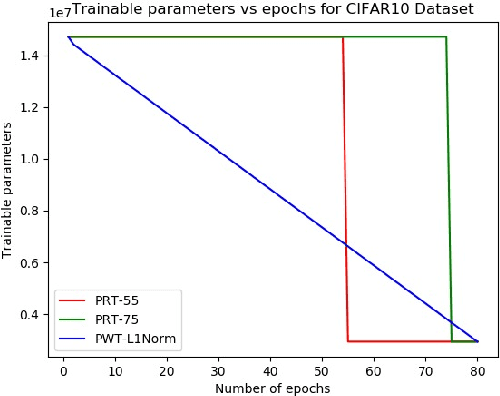
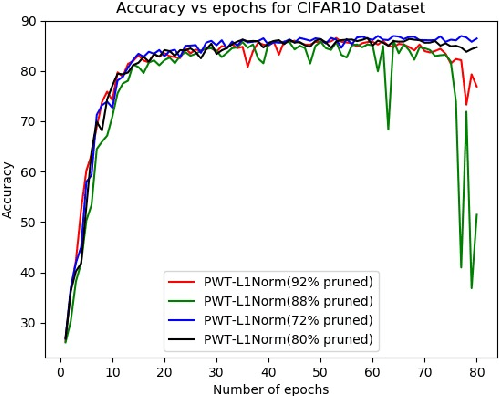
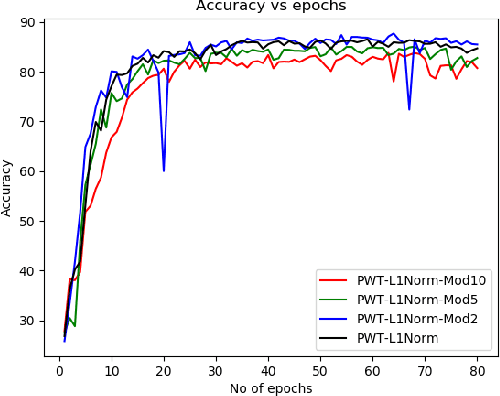
Modern deep networks have millions to billions of parameters, which leads to high memory and energy requirements during training as well as during inference on resource-constrained edge devices. Consequently, pruning techniques have been proposed that remove less significant weights in deep networks, thereby reducing their memory and computational requirements. Pruning is usually performed after training the original network, and is followed by further retraining to compensate for the accuracy loss incurred during pruning. The prune-and-retrain procedure is repeated iteratively until an optimum tradeoff between accuracy and efficiency is reached. However, such iterative retraining adds to the overall training complexity of the network. In this work, we propose a dynamic pruning-while-training procedure, wherein we prune filters of the convolutional layers of a deep network during training itself, thereby precluding the need for separate retraining. We evaluate our dynamic pruning-while-training approach with three different pre-existing pruning strategies, viz. mean activation-based pruning, random pruning, and L1 normalization-based pruning. Our results for VGG-16 trained on CIFAR10 shows that L1 normalization provides the best performance among all the techniques explored in this work with less than 1% drop in accuracy after pruning 80% of the filters compared to the original network. We further evaluated the L1 normalization based pruning mechanism on CIFAR100. Results indicate that pruning while training yields a compressed network with almost no accuracy loss after pruning 50% of the filters compared to the original network and ~5% loss for high pruning rates (>80%). The proposed pruning methodology yields 41% reduction in the number of computations and memory accesses during training for CIFAR10, CIFAR100 and ImageNet compared to training with retraining for 10 epochs .
Explicitly Trained Spiking Sparsity in Spiking Neural Networks with Backpropagation
Mar 02, 2020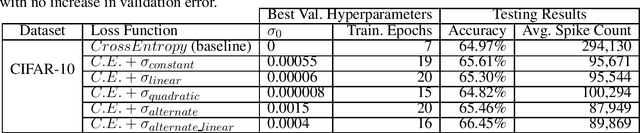
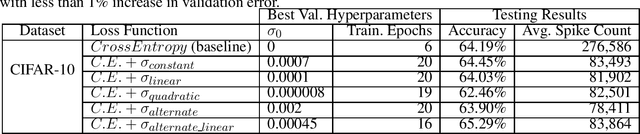
Spiking Neural Networks (SNNs) are being explored for their potential energy efficiency resulting from sparse, event-driven computations. Many recent works have demonstrated effective backpropagation for deep Spiking Neural Networks (SNNs) by approximating gradients over discontinuous neuron spikes or firing events. A beneficial side-effect of these surrogate gradient spiking backpropagation algorithms is that the spikes, which trigger additional computations, may now themselves be directly considered in the gradient calculations. We propose an explicit inclusion of spike counts in the loss function, along with a traditional error loss, causing the backpropagation learning algorithms to optimize weight parameters for both accuracy and spiking sparsity. As supported by existing theory of over-parameterized neural networks, there are many solution states with effectively equivalent accuracy. As such, appropriate weighting of the two loss goals during training in this multi-objective optimization process can yield an improvement in spiking sparsity without a significant loss of accuracy. We additionally explore a simulated annealing-inspired loss weighting technique to increase the weighting for sparsity as training time increases. Our preliminary results on the Cifar-10 dataset show up to 70.1% reduction in spiking activity with iso-accuracy compared to an equivalent SNN trained only for accuracy and up to 73.3% reduction in spiking activity if allowed a trade-off of 1% reduction in classification accuracy.
RMP-SNNs: Residual Membrane Potential Neuron for Enabling Deeper High-Accuracy and Low-Latency Spiking Neural Networks
Feb 25, 2020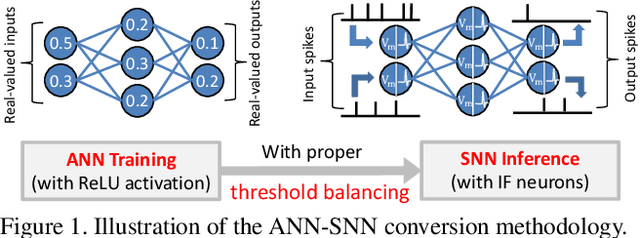
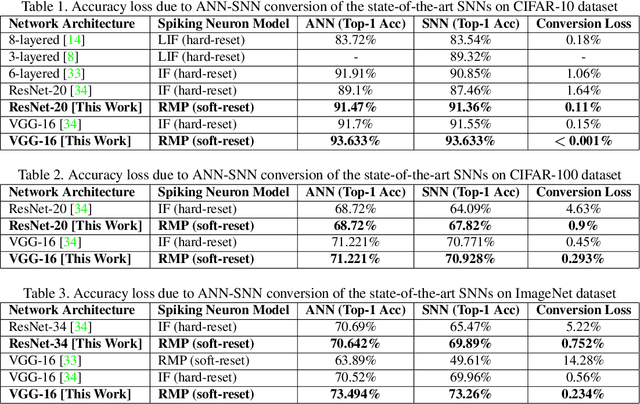
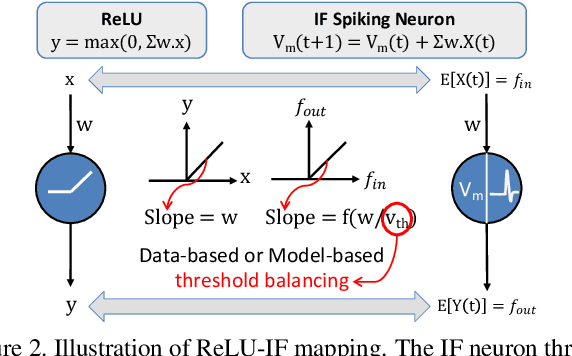
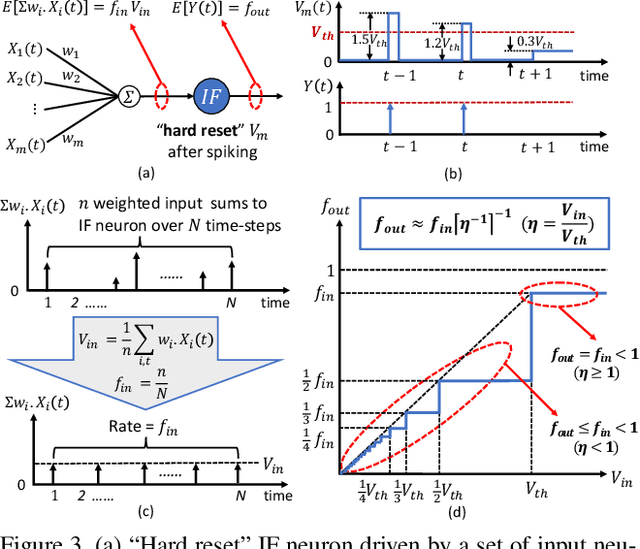
Spiking Neural Networks (SNNs) have recently attracted significant research interest as the third generation of artificial neural networks that can enable low-power event-driven data analytics. The best performing SNNs for image recognition tasks are obtained by converting a trained Analog Neural Network (ANN), consisting of Rectified Linear Units (ReLU), to SNN composed of integrate-and-fire neurons with "proper" firing thresholds. The converted SNNs typically incur loss in accuracy compared to that provided by the original ANN and require sizable number of inference time-steps to achieve the best accuracy. We find that performance degradation in the converted SNN stems from using "hard reset" spiking neuron that is driven to fixed reset potential once its membrane potential exceeds the firing threshold, leading to information loss during SNN inference. We propose ANN-SNN conversion using "soft reset" spiking neuron model, referred to as Residual Membrane Potential (RMP) spiking neuron, which retains the "residual" membrane potential above threshold at the firing instants. We demonstrate near loss-less ANN-SNN conversion using RMP neurons for VGG-16, ResNet-20, and ResNet-34 SNNs on challenging datasets including CIFAR-10 (93.63% top-1), CIFAR-100 (70.928% top-1), and ImageNet (73.26% top-1 accuracy). Our results also show that RMP-SNN achieves comparable accuracy to that provided by the converted SNN with "hard reset" spiking neurons using 2-8 times fewer inference time-steps across datasets.
Reinforcement Learning with Low-Complexity Liquid State Machines
Jun 04, 2019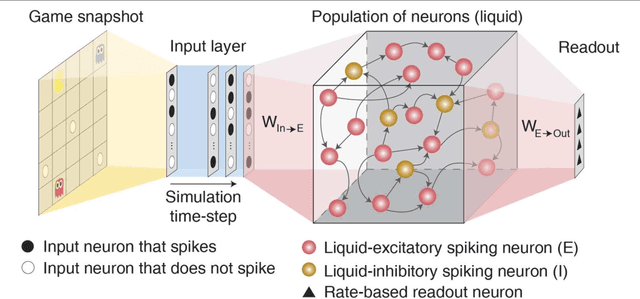


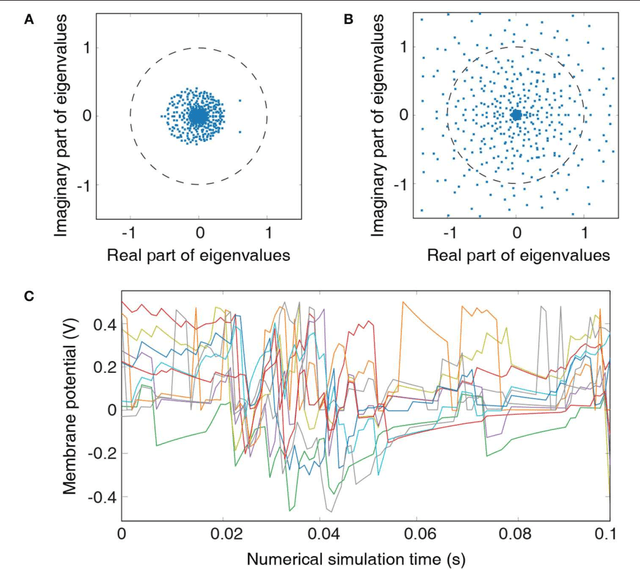
We propose reinforcement learning on simple networks consisting of random connections of spiking neurons (both recurrent and feed-forward) that can learn complex tasks with very little trainable parameters. Such sparse and randomly interconnected recurrent spiking networks exhibit highly non-linear dynamics that transform the inputs into rich high-dimensional representations based on past context. The random input representations can be efficiently interpreted by an output (or readout) layer with trainable parameters. Systematic initialization of the random connections and training of the readout layer using Q-learning algorithm enable such small random spiking networks to learn optimally and achieve the same learning efficiency as humans on complex reinforcement learning tasks like Atari games. The spike-based approach using small random recurrent networks provides a computationally efficient alternative to state-of-the-art deep reinforcement learning networks with several layers of trainable parameters. The low-complexity spiking networks can lead to improved energy efficiency in event-driven neuromorphic hardware for complex reinforcement learning tasks.
ReStoCNet: Residual Stochastic Binary Convolutional Spiking Neural Network for Memory-Efficient Neuromorphic Computing
Feb 11, 2019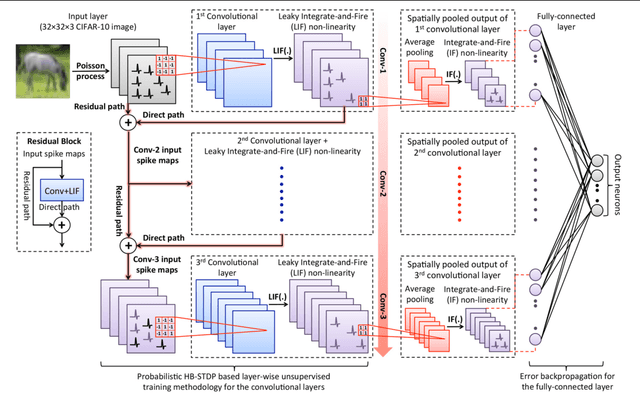

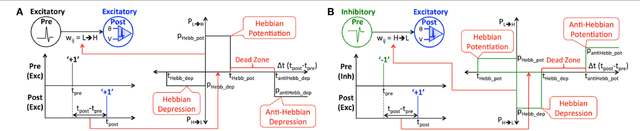

In this work, we propose ReStoCNet, a residual stochastic multilayer convolutional Spiking Neural Network (SNN) composed of binary kernels, to reduce the synaptic memory footprint and enhance the computational efficiency of SNNs for complex pattern recognition tasks. ReStoCNet consists of an input layer followed by stacked convolutional layers for hierarchical input feature extraction, pooling layers for dimensionality reduction, and fully-connected layer for inference. In addition, we introduce residual connections between the stacked convolutional layers to improve the hierarchical feature learning capability of deep SNNs. We propose Spike Timing Dependent Plasticity (STDP) based probabilistic learning algorithm, referred to as Hybrid-STDP (HB-STDP), incorporating Hebbian and anti-Hebbian learning mechanisms, to train the binary kernels forming ReStoCNet in a layer-wise unsupervised manner. We demonstrate the efficacy of ReStoCNet and the presented HB-STDP based unsupervised training methodology on the MNIST and CIFAR-10 datasets. We show that residual connections enable the deeper convolutional layers to self-learn useful high-level input features and mitigate the accuracy loss observed in deep SNNs devoid of residual connections. The proposed ReStoCNet offers >20x kernel memory compression compared to full-precision (32-bit) SNN while yielding high enough classification accuracy on the chosen pattern recognition tasks.