 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuAKE: Speeding up Model Inference Using Quick and Approximate Kernels for Exponential Non-Linearities
Nov 30, 2024
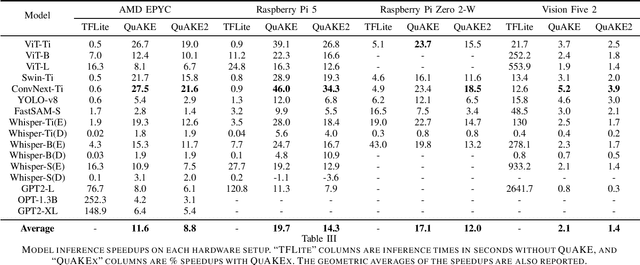
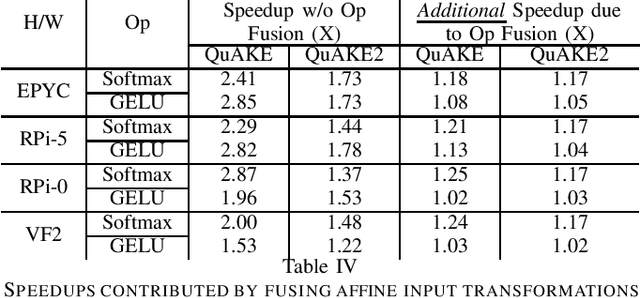
As machine learning gets deployed more and more widely, and model sizes continue to grow, improving computational efficiency during model inference has become a key challenge. In many commonly used model architectures, including Transformers, a significant portion of the inference computation is comprised of exponential non-linearities such as Softmax. In this work, we develop QuAKE, a collection of novel operators that leverage certain properties of IEEE-754 floating point representations to quickly approximate the exponential function without requiring specialized hardware, extra memory, or precomputation. We propose optimizations that enhance the efficiency of QuAKE in commonly used exponential non-linearities such as Softmax, GELU, and the Logistic function. Our benchmarks demonstrate substantial inference speed improvements between 10% and 35% on server CPUs, and 5% and 45% on embedded and mobile-scale CPUs for a variety of model architectures and sizes. Evaluations of model performance on standard datasets and tasks from various domains show that QuAKE operators are able to provide sizable speed benefits with little to no loss of performance on downstream tasks.
An Active Learning Framework for Efficient Robust Policy Search
Jan 01, 2019
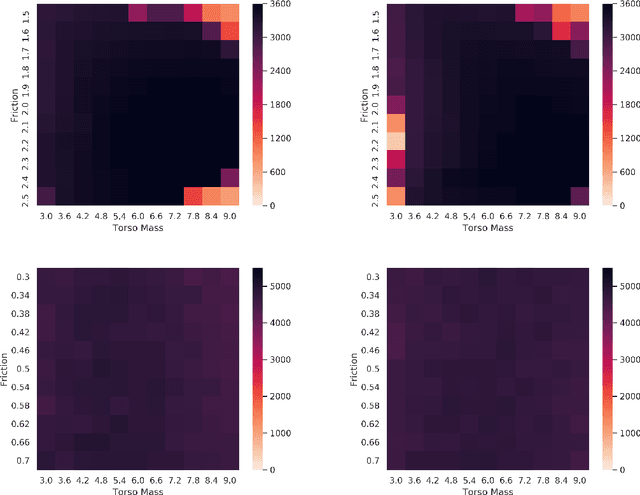
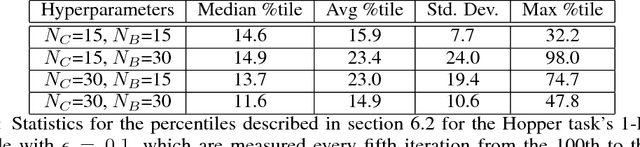
Robust Policy Search is the problem of learning policies that do not degrade in performance when subject to unseen environment model parameters. It is particularly relevant for transferring policies learned in a simulation environment to the real world. Several existing approaches involve sampling large batches of trajectories which reflect the differences in various possible environments, and then selecting some subset of these to learn robust policies, such as the ones that result in the worst performance. We propose an active learning based framework, EffAcTS, to selectively choose model parameters for this purpose so as to collect only as much data as necessary to select such a subset. We apply this framework to an existing method, namely EPOpt, and experimentally validate the gains in sample efficiency and the performance of our approach on standard continuous control tasks. We also present a Multi-Task Learning perspective to the problem of Robust Policy Search, and draw connections from our proposed framework to existing work on Multi-Task Learning.