 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplicitly Trained Spiking Sparsity in Spiking Neural Networks with Backpropagation
Mar 02, 2020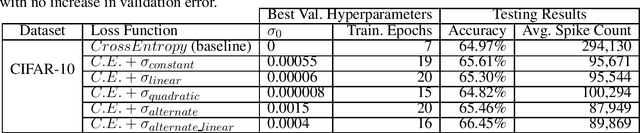
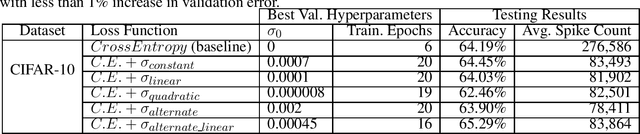
Spiking Neural Networks (SNNs) are being explored for their potential energy efficiency resulting from sparse, event-driven computations. Many recent works have demonstrated effective backpropagation for deep Spiking Neural Networks (SNNs) by approximating gradients over discontinuous neuron spikes or firing events. A beneficial side-effect of these surrogate gradient spiking backpropagation algorithms is that the spikes, which trigger additional computations, may now themselves be directly considered in the gradient calculations. We propose an explicit inclusion of spike counts in the loss function, along with a traditional error loss, causing the backpropagation learning algorithms to optimize weight parameters for both accuracy and spiking sparsity. As supported by existing theory of over-parameterized neural networks, there are many solution states with effectively equivalent accuracy. As such, appropriate weighting of the two loss goals during training in this multi-objective optimization process can yield an improvement in spiking sparsity without a significant loss of accuracy. We additionally explore a simulated annealing-inspired loss weighting technique to increase the weighting for sparsity as training time increases. Our preliminary results on the Cifar-10 dataset show up to 70.1% reduction in spiking activity with iso-accuracy compared to an equivalent SNN trained only for accuracy and up to 73.3% reduction in spiking activity if allowed a trade-off of 1% reduction in classification accuracy.
Stimulating STDP to Exploit Locality for Lifelong Learning without Catastrophic Forgetting
Feb 08, 2019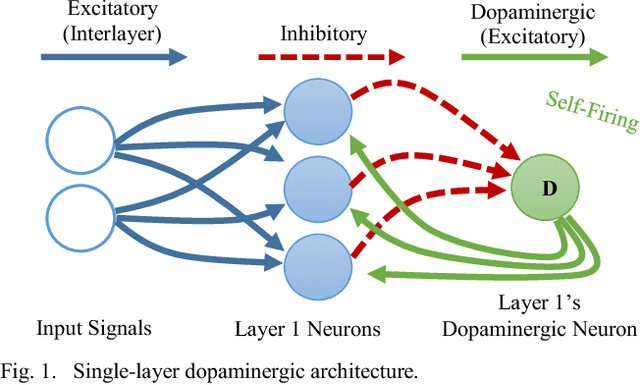
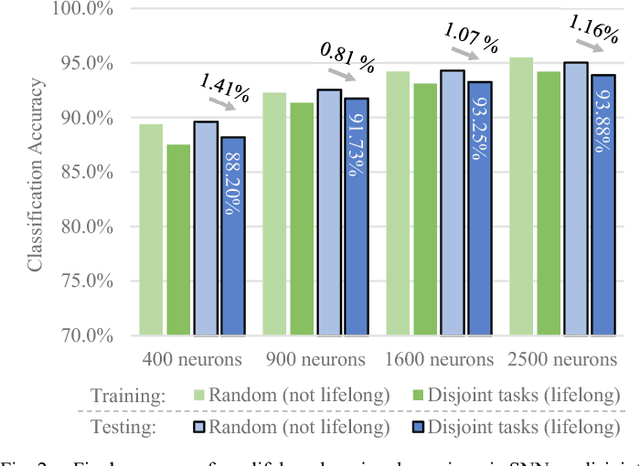
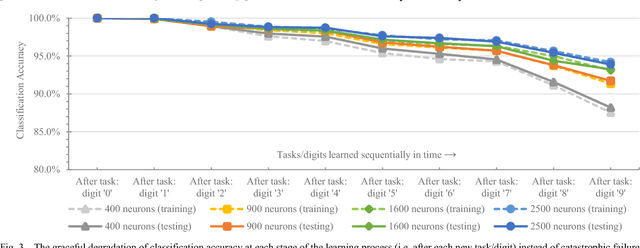
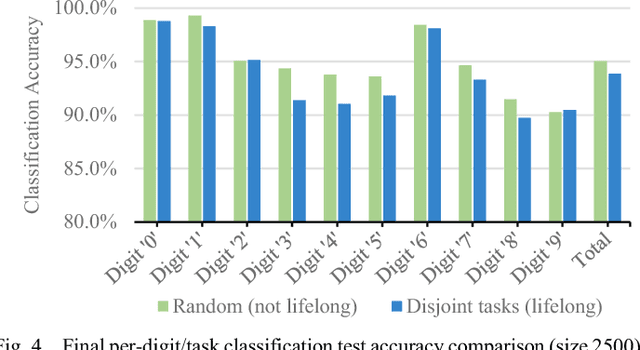
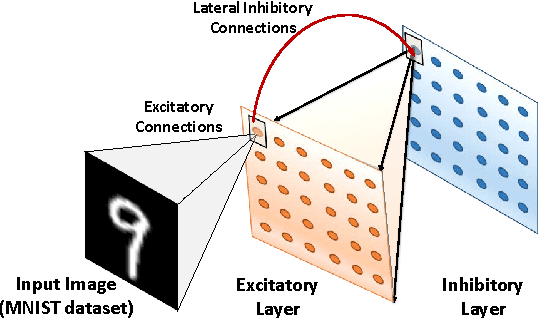
Stochastic gradient descent requires that training samples be drawn from a uniformly random distribution of the data. For a deployed system that must learn online from an uncontrolled and unknown environment, the ordering of input samples often fails to meet this criterion, making lifelong learning a difficult challenge. We exploit the locality of the unsupervised Spike Timing Dependent Plasticity (STDP) learning rule to target subsets of a segmented Spiking Neural Network (SNN) to adapt to novel information while protecting the information in the remainder of the SNN from catastrophic forgetting. In our system, novel information triggers stimulated firing, inspired by biological dopamine signals, to boost STDP in the synapses of neurons associated with outlier information. This targeting controls the forgetting process in a way that reduces accuracy degradation while learning new information. Our preliminary results on the MNIST dataset validate the capability of such a system to learn successfully over time from an unknown, changing environment, achieving up to 93.88% accuracy for a completely disjoint dataset.
ASP: Learning to Forget with Adaptive Synaptic Plasticity in Spiking Neural Networks
Jun 08, 2018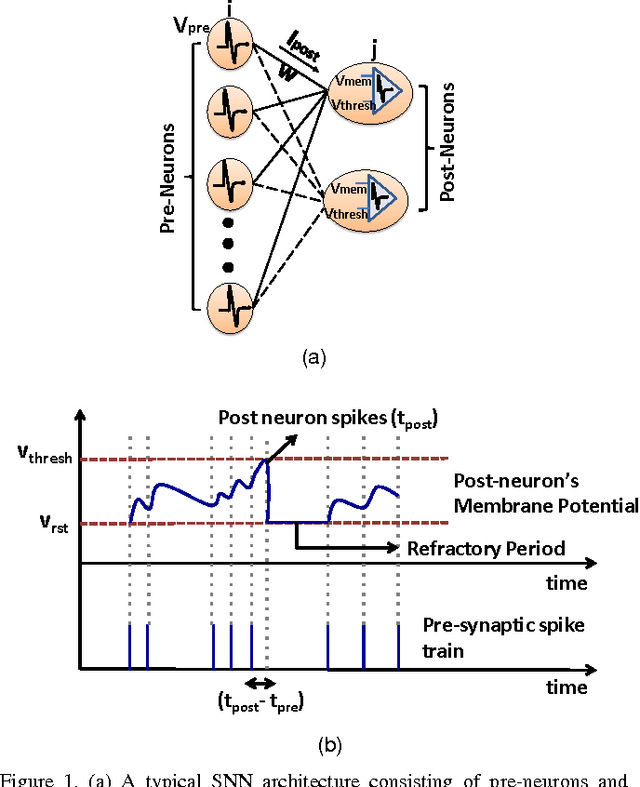
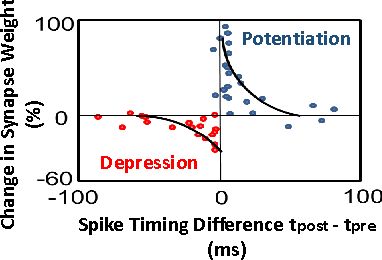

A fundamental feature of learning in animals is the "ability to forget" that allows an organism to perceive, model and make decisions from disparate streams of information and adapt to changing environments. Against this backdrop, we present a novel unsupervised learning mechanism ASP (Adaptive Synaptic Plasticity) for improved recognition with Spiking Neural Networks (SNNs) for real time on-line learning in a dynamic environment. We incorporate an adaptive weight decay mechanism with the traditional Spike Timing Dependent Plasticity (STDP) learning to model adaptivity in SNNs. The leak rate of the synaptic weights is modulated based on the temporal correlation between the spiking patterns of the pre- and post-synaptic neurons. This mechanism helps in gradual forgetting of insignificant data while retaining significant, yet old, information. ASP, thus, maintains a balance between forgetting and immediate learning to construct a stable-plastic self-adaptive SNN for continuously changing inputs. We demonstrate that the proposed learning methodology addresses catastrophic forgetting while yielding significantly improved accuracy over the conventional STDP learning method for digit recognition applications. Additionally, we observe that the proposed learning model automatically encodes selective attention towards relevant features in the input data while eliminating the influence of background noise (or denoising) further improving the robustness of the ASP learning.
* 14 pages, 14 figures