 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplicitly Trained Spiking Sparsity in Spiking Neural Networks with Backpropagation
Paper and Code
Mar 02, 2020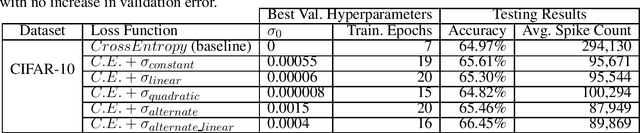
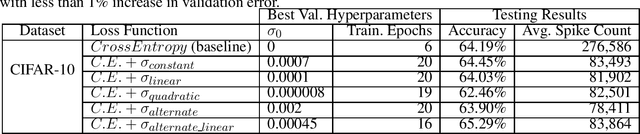
Spiking Neural Networks (SNNs) are being explored for their potential energy efficiency resulting from sparse, event-driven computations. Many recent works have demonstrated effective backpropagation for deep Spiking Neural Networks (SNNs) by approximating gradients over discontinuous neuron spikes or firing events. A beneficial side-effect of these surrogate gradient spiking backpropagation algorithms is that the spikes, which trigger additional computations, may now themselves be directly considered in the gradient calculations. We propose an explicit inclusion of spike counts in the loss function, along with a traditional error loss, causing the backpropagation learning algorithms to optimize weight parameters for both accuracy and spiking sparsity. As supported by existing theory of over-parameterized neural networks, there are many solution states with effectively equivalent accuracy. As such, appropriate weighting of the two loss goals during training in this multi-objective optimization process can yield an improvement in spiking sparsity without a significant loss of accuracy. We additionally explore a simulated annealing-inspired loss weighting technique to increase the weighting for sparsity as training time increases. Our preliminary results on the Cifar-10 dataset show up to 70.1% reduction in spiking activity with iso-accuracy compared to an equivalent SNN trained only for accuracy and up to 73.3% reduction in spiking activity if allowed a trade-off of 1% reduction in classification accuracy.