 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Timestep is All You Need: Training Spiking Neural Networks with Ultra Low Latency
Oct 01, 2021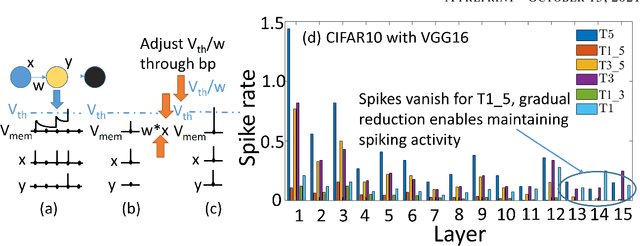
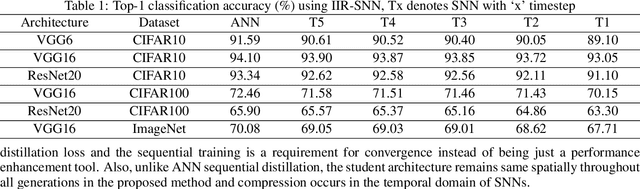
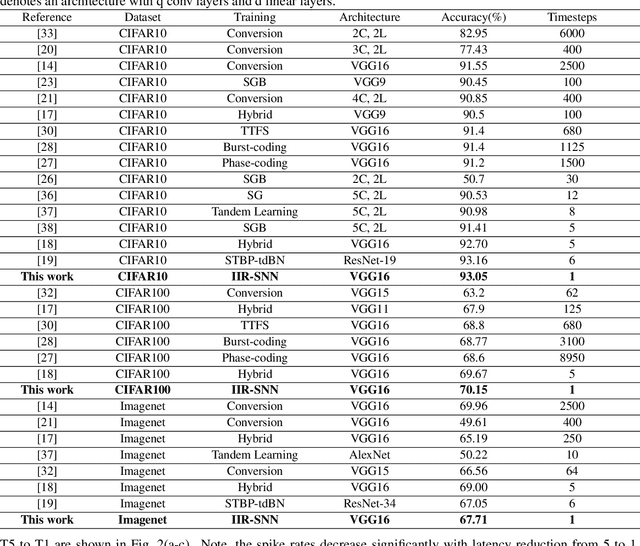
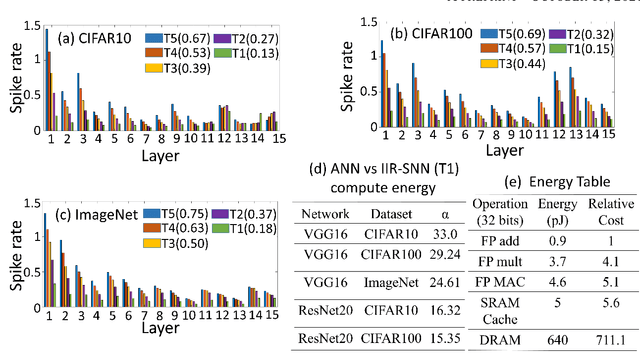
Spiking Neural Networks (SNNs) are energy efficient alternatives to commonly used deep neural networks (DNNs). Through event-driven information processing, SNNs can reduce the expensive compute requirements of DNNs considerably, while achieving comparable performance. However, high inference latency is a significant hindrance to the edge deployment of deep SNNs. Computation over multiple timesteps not only increases latency as well as overall energy budget due to higher number of operations, but also incurs memory access overhead of fetching membrane potentials, both of which lessen the energy benefits of SNNs. To overcome this bottleneck and leverage the full potential of SNNs, we propose an Iterative Initialization and Retraining method for SNNs (IIR-SNN) to perform single shot inference in the temporal axis. The method starts with an SNN trained with T timesteps (T>1). Then at each stage of latency reduction, the network trained at previous stage with higher timestep is utilized as initialization for subsequent training with lower timestep. This acts as a compression method, as the network is gradually shrunk in the temporal domain. In this paper, we use direct input encoding and choose T=5, since as per literature, it is the minimum required latency to achieve satisfactory performance on ImageNet. The proposed scheme allows us to obtain SNNs with up to unit latency, requiring a single forward pass during inference. We achieve top-1 accuracy of 93.05%, 70.15% and 67.71% on CIFAR-10, CIFAR-100 and ImageNet, respectively using VGG16, with just 1 timestep. In addition, IIR-SNNs perform inference with 5-2500X reduced latency compared to other state-of-the-art SNNs, maintaining comparable or even better accuracy. Furthermore, in comparison with standard DNNs, the proposed IIR-SNNs provide25-33X higher energy efficiency, while being comparable to them in classification performance.
DIET-SNN: Direct Input Encoding With Leakage and Threshold Optimization in Deep Spiking Neural Networks
Aug 09, 2020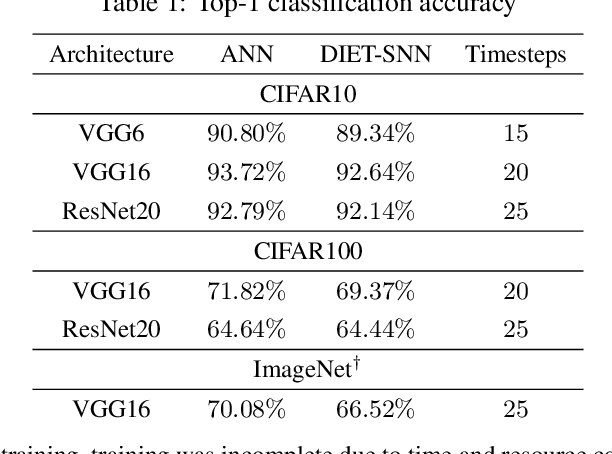
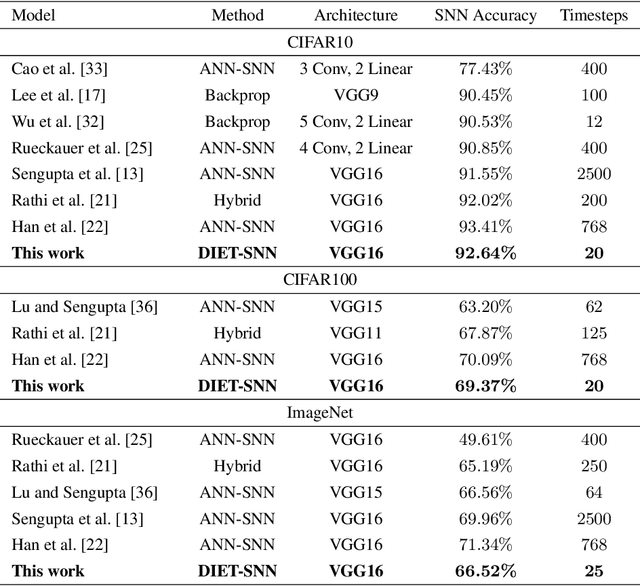
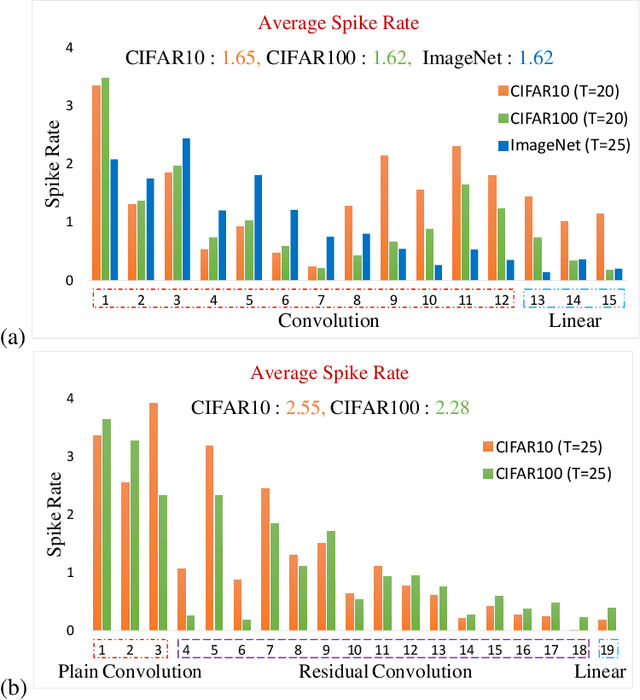
Bio-inspired spiking neural networks (SNNs), operating with asynchronous binary signals (or spikes) distributed over time, can potentially lead to greater computational efficiency on event-driven hardware. The state-of-the-art SNNs suffer from high inference latency, resulting from inefficient input encoding, and sub-optimal settings of the neuron parameters (firing threshold, and membrane leak). We propose DIET-SNN, a low latency deep spiking network that is trained with gradient descent to optimize the membrane leak and the firing threshold along with other network parameters (weights). The membrane leak and threshold for each layer of the SNN are optimized with end-to-end backpropagation to achieve competitive accuracy at reduced latency. The analog pixel values of an image are directly applied to the input layer of DIET-SNN without the need to convert to spike-train. The information is converted into spikes in the first convolutional layer where leaky-integrate-and-fire (LIF) neurons integrate the weighted inputs and generate an output spike when the membrane potential crosses the trained firing threshold. The trained membrane leak controls the flow of input information and attenuates irrelevant inputs to increase the activation sparsity in the convolutional and linear layers of the network. The reduced latency combined with high activation sparsity provides large improvements in computational efficiency. We evaluate DIET-SNN on image classification tasks from CIFAR and ImageNet datasets on VGG and ResNet architectures. We achieve top-1 accuracy of 66.52% with 25 timesteps (inference latency) on the ImageNet dataset with 3.1X less compute energy than an equivalent standard ANN. Additionally, DIET-SNN performs 5-100X faster inference compared to other state-of-the-art SNN models.
Enabling Deep Spiking Neural Networks with Hybrid Conversion and Spike Timing Dependent Backpropagation
May 04, 2020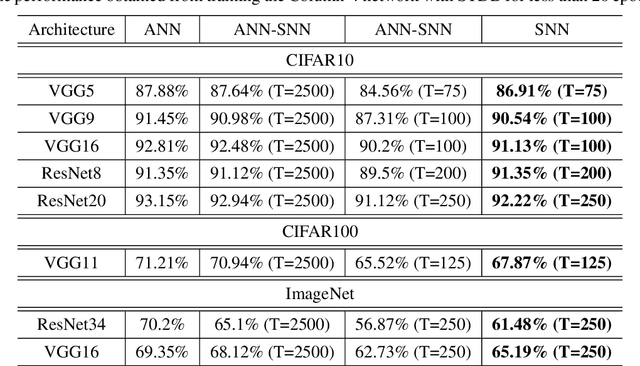
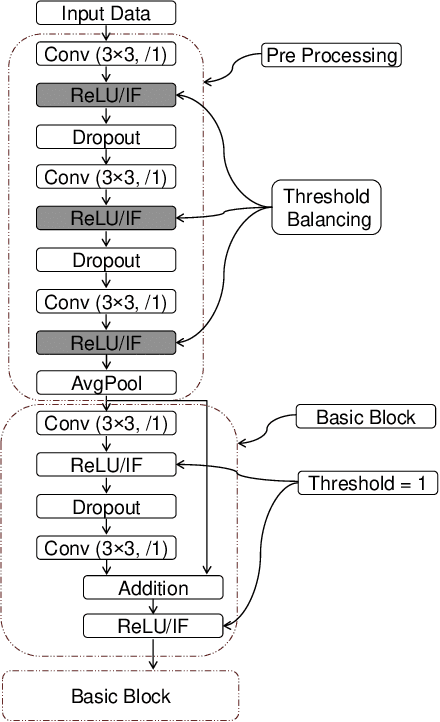
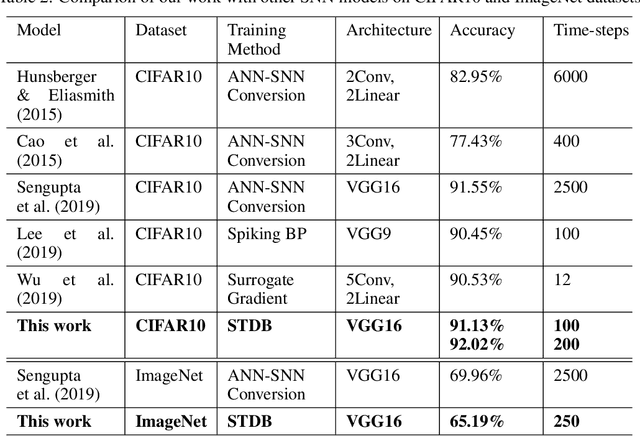
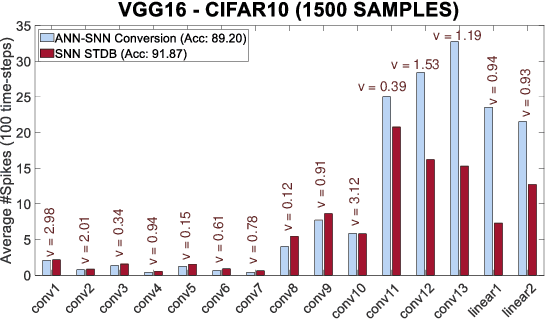
Spiking Neural Networks (SNNs) operate with asynchronous discrete events (or spikes) which can potentially lead to higher energy-efficiency in neuromorphic hardware implementations. Many works have shown that an SNN for inference can be formed by copying the weights from a trained Artificial Neural Network (ANN) and setting the firing threshold for each layer as the maximum input received in that layer. These type of converted SNNs require a large number of time steps to achieve competitive accuracy which diminishes the energy savings. The number of time steps can be reduced by training SNNs with spike-based backpropagation from scratch, but that is computationally expensive and slow. To address these challenges, we present a computationally-efficient training technique for deep SNNs. We propose a hybrid training methodology: 1) take a converted SNN and use its weights and thresholds as an initialization step for spike-based backpropagation, and 2) perform incremental spike-timing dependent backpropagation (STDB) on this carefully initialized network to obtain an SNN that converges within few epochs and requires fewer time steps for input processing. STDB is performed with a novel surrogate gradient function defined using neuron's spike time. The proposed training methodology converges in less than 20 epochs of spike-based backpropagation for most standard image classification datasets, thereby greatly reducing the training complexity compared to training SNNs from scratch. We perform experiments on CIFAR-10, CIFAR-100, and ImageNet datasets for both VGG and ResNet architectures. We achieve top-1 accuracy of 65.19% for ImageNet dataset on SNN with 250 time steps, which is 10X faster compared to converted SNNs with similar accuracy.
Inherent Adversarial Robustness of Deep Spiking Neural Networks: Effects of Discrete Input Encoding and Non-Linear Activations
Mar 23, 2020



In the recent quest for trustworthy neural networks, we present Spiking Neural Network (SNN) as a potential candidate for inherent robustness against adversarial attacks. In this work, we demonstrate that accuracy degradation is less severe in SNNs than in their non-spiking counterparts for CIFAR10 and CIFAR100 datasets on deep VGG architectures. We attribute this robustness to two fundamental characteristics of SNNs and analyze their effects. First, we exhibit that input discretization introduced by the Poisson encoder improves adversarial robustness with reduced number of timesteps. Second, we quantify the amount of adversarial accuracy with increased leak rate in Leaky-Integrate-Fire (LIF) neurons. Our results suggest that SNNs trained with LIF neurons and smaller number of timesteps are more robust than the ones with IF (Integrate-Fire) neurons and larger number of timesteps. We overcome the bottleneck of creating gradient-based adversarial inputs in temporal domain by proposing a technique for crafting attacks from SNN.
STDP Based Pruning of Connections and Weight Quantization in Spiking Neural Networks for Energy Efficient Recognition
Oct 12, 2017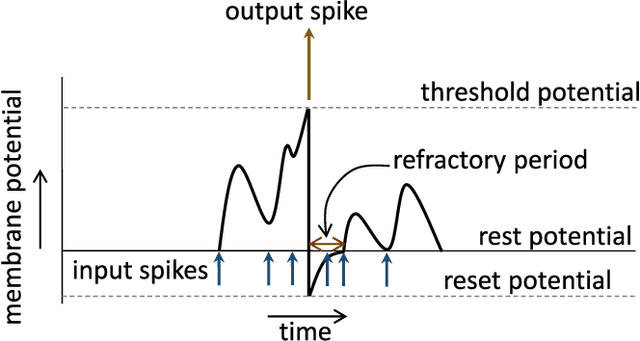
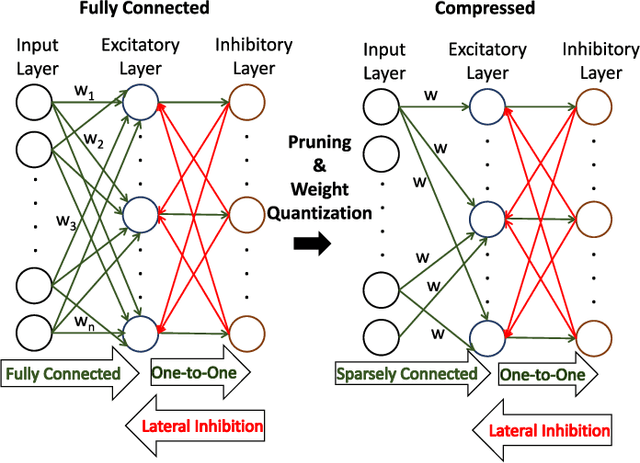
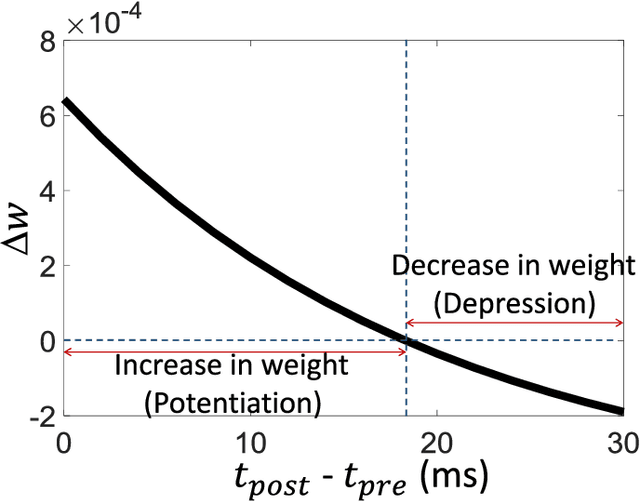
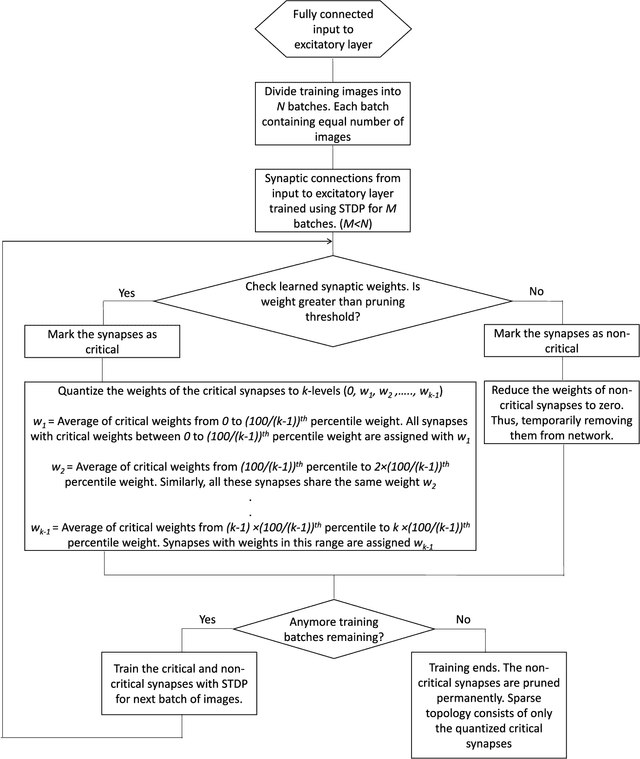
Spiking Neural Networks (SNNs) with a large number of weights and varied weight distribution can be difficult to implement in emerging in-memory computing hardware due to the limitations on crossbar size (implementing dot product), the constrained number of conductance levels in non-CMOS devices and the power budget. We present a sparse SNN topology where non-critical connections are pruned to reduce the network size and the remaining critical synapses are weight quantized to accommodate for limited conductance levels. Pruning is based on the power law weight-dependent Spike Timing Dependent Plasticity (STDP) model; synapses between pre- and post-neuron with high spike correlation are retained, whereas synapses with low correlation or uncorrelated spiking activity are pruned. The weights of the retained connections are quantized to the available number of conductance levels. The process of pruning non-critical connections and quantizing the weights of critical synapses is performed at regular intervals during training. We evaluated our sparse and quantized network on MNIST dataset and on a subset of images from Caltech-101 dataset. The compressed topology achieved a classification accuracy of 90.1% (91.6%) on the MNIST (Caltech-101) dataset with 3.1x (2.2x) and 4x (2.6x) improvement in energy and area, respectively. The compressed topology is energy and area efficient while maintaining the same classification accuracy of a 2-layer fully connected SNN topology.