 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetect Before You Leap: Mirage Detection in Vision-Language Models
May 29, 2026Vision-language models (VLMs) can produce confident visual answers even when the required visual evidence is missing, blank, or unrelated to the question. This failure mode, known as mirage (Asadi et al. 2026), is especially concerning in medical and document visual question answering, where plausible but visually ungrounded responses may be mistaken for image-based evidence. We study pre-release mirage detection: given an image-question pair, the goal is to determine whether a VLM should answer or abstain before producing a response. We propose Text-Conditioned Layer-wise Internal Alignment (TC-LIA), a model-agnostic method that probes patch-token representations across the layers of a CLIP ViT-H/14 vision encoder. TC-LIA projects layer-wise image patch tokens into the final CLIP embedding space and measures their similarity to the question embedding, allowing the method to track whether question-relevant visual evidence emerges across vision layers. The resulting alignment trajectory is summarized using final image-text cosine similarity, late-layer top-k patch-text alignment, early-to-late gain, and layer-wise slope. These features are combined with pixel-statistic blank/noise detection, zero-shot domain routing, and structured VLM self-assessment in an ensemble. Across five VQA domains, three input conditions, and twelve VLM backbones, the best systems achieve approximately 94.6-94.7% three-class detection accuracy with mirage rates below 3%, while baseline mirage rates range from 21.7% to 66.6%.
Who Benefits From Sinus Surgery? Comparing Generative AI and Supervised Machine Learning for Predicting Surgical Outcomes in Chronic Rhinosinusitis
Jan 22, 2026Artificial intelligence has reshaped medical imaging, yet the use of AI on clinical data for prospective decision support remains limited. We study pre-operative prediction of clinically meaningful improvement in chronic rhinosinusitis (CRS), defining success as a more than 8.9-point reduction in SNOT-22 at 6 months (MCID). In a prospectively collected cohort where all patients underwent surgery, we ask whether models using only pre-operative clinical data could have identified those who would have poor outcomes, i.e. those who should have avoided surgery. We benchmark supervised ML (logistic regression, tree ensembles, and an in-house MLP) against generative AI (ChatGPT, Claude, Gemini, Perplexity), giving each the same structured inputs and constraining outputs to binary recommendations with confidence. Our best ML model (MLP) achieves 85 % accuracy with superior calibration and decision-curve net benefit. GenAI models underperform on discrimination and calibration across zero-shot setting. Notably, GenAI justifications align with clinician heuristics and the MLP's feature importance, repeatedly highlighting baseline SNOT-22, CT/endoscopy severity, polyp phenotype, and physchology/pain comorbidities. We provide a reproducible tabular-to-GenAI evaluation protocol and subgroup analyses. Findings support an ML-first, GenAI- augmented workflow: deploy calibrated ML for primary triage of surgical candidacy, with GenAI as an explainer to enhance transparency and shared decision-making.
Who Should Have Surgery? A Comparative Study of GenAI vs Supervised ML for CRS Surgical Outcome Prediction
Jan 20, 2026Artificial intelligence has reshaped medical imaging, yet the use of AI on clinical data for prospective decision support remains limited. We study pre-operative prediction of clinically meaningful improvement in chronic rhinosinusitis (CRS), defining success as a more than 8.9-point reduction in SNOT-22 at 6 months (MCID). In a prospectively collected cohort where all patients underwent surgery, we ask whether models using only pre-operative clinical data could have identified those who would have poor outcomes, i.e. those who should have avoided surgery. We benchmark supervised ML (logistic regression, tree ensembles, and an in-house MLP) against generative AI (ChatGPT, Claude, Gemini, Perplexity), giving each the same structured inputs and constraining outputs to binary recommendations with confidence. Our best ML model (MLP) achieves 85 % accuracy with superior calibration and decision-curve net benefit. GenAI models underperform on discrimination and calibration across zero-shot setting. Notably, GenAI justifications align with clinician heuristics and the MLP's feature importance, repeatedly highlighting baseline SNOT-22, CT/endoscopy severity, polyp phenotype, and physchology/pain comorbidities. We provide a reproducible tabular-to-GenAI evaluation protocol and subgroup analyses. Findings support an ML-first, GenAI- augmented workflow: deploy calibrated ML for primary triage of surgical candidacy, with GenAI as an explainer to enhance transparency and shared decision-making.
Roadmap to Neuromorphic Computing with Emerging Technologies
Jul 02, 2024



The roadmap is organized into several thematic sections, outlining current computing challenges, discussing the neuromorphic computing approach, analyzing mature and currently utilized technologies, providing an overview of emerging technologies, addressing material challenges, exploring novel computing concepts, and finally examining the maturity level of emerging technologies while determining the next essential steps for their advancement.
ViTALS: Vision Transformer for Action Localization in Surgical Nephrectomy
May 04, 2024Surgical action localization is a challenging computer vision problem. While it has promising applications including automated training of surgery procedures, surgical workflow optimization, etc., appropriate model design is pivotal to accomplishing this task. Moreover, the lack of suitable medical datasets adds an additional layer of complexity. To that effect, we introduce a new complex dataset of nephrectomy surgeries called UroSlice. To perform the action localization from these videos, we propose a novel model termed as `ViTALS' (Vision Transformer for Action Localization in Surgical Nephrectomy). Our model incorporates hierarchical dilated temporal convolution layers and inter-layer residual connections to capture the temporal correlations at finer as well as coarser granularities. The proposed approach achieves state-of-the-art performance on Cholec80 and UroSlice datasets (89.8% and 66.1% accuracy, respectively), validating its effectiveness.
Towards Visual Syntactical Understanding
Jan 30, 2024Syntax is usually studied in the realm of linguistics and refers to the arrangement of words in a sentence. Similarly, an image can be considered as a visual 'sentence', with the semantic parts of the image acting as 'words'. While visual syntactic understanding occurs naturally to humans, it is interesting to explore whether deep neural networks (DNNs) are equipped with such reasoning. To that end, we alter the syntax of natural images (e.g. swapping the eye and nose of a face), referred to as 'incorrect' images, to investigate the sensitivity of DNNs to such syntactic anomaly. Through our experiments, we discover an intriguing property of DNNs where we observe that state-of-the-art convolutional neural networks, as well as vision transformers, fail to discriminate between syntactically correct and incorrect images when trained on only correct ones. To counter this issue and enable visual syntactic understanding with DNNs, we propose a three-stage framework- (i) the 'words' (or the sub-features) in the image are detected, (ii) the detected words are sequentially masked and reconstructed using an autoencoder, (iii) the original and reconstructed parts are compared at each location to determine syntactic correctness. The reconstruction module is trained with BERT-like masked autoencoding for images, with the motivation to leverage language model inspired training to better capture the syntax. Note, our proposed approach is unsupervised in the sense that the incorrect images are only used during testing and the correct versus incorrect labels are never used for training. We perform experiments on CelebA, and AFHQ datasets and obtain classification accuracy of 92.10%, and 90.89%, respectively. Notably, the approach generalizes well to ImageNet samples which share common classes with CelebA and AFHQ without explicitly training on them.
Segmented Recurrent Transformer: An Efficient Sequence-to-Sequence Model
May 24, 2023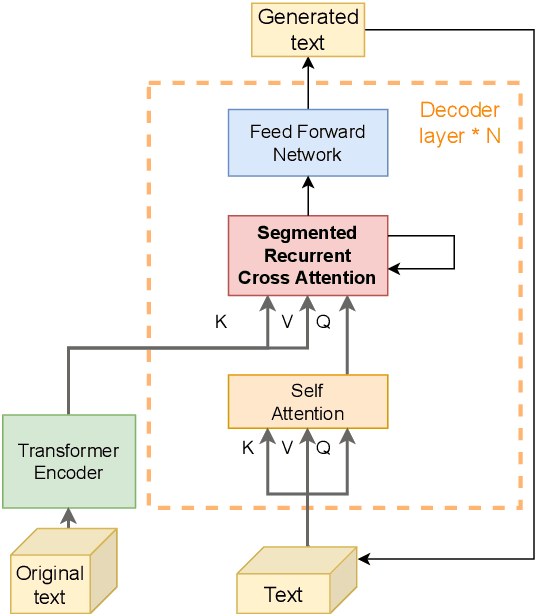

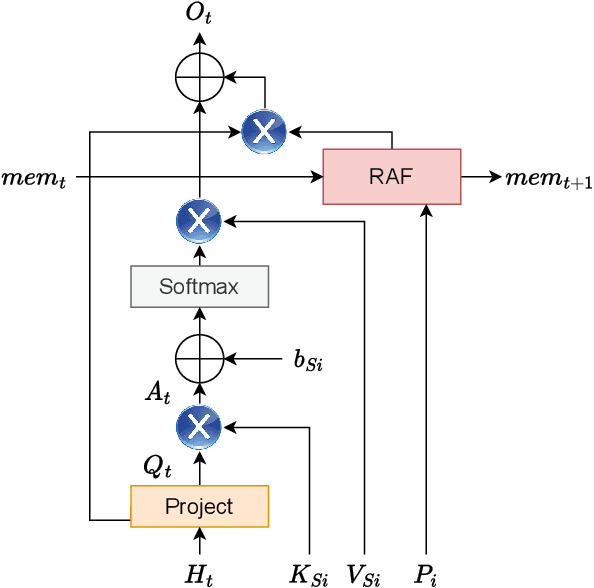
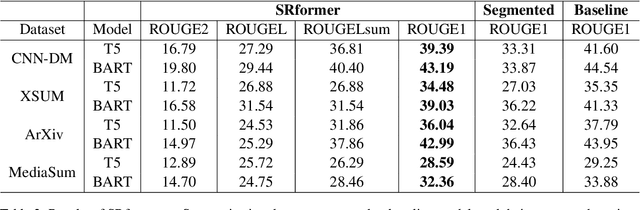
Transformers have shown dominant performance across a range of domains including language and vision. However, their computational cost grows quadratically with the sequence length, making their usage prohibitive for resource-constrained applications. To counter this, our approach is to divide the whole sequence into segments. The information across segments can then be aggregated using neurons with recurrence leveraging their inherent memory. Such an approach leads to models with sequential processing capability at a lower computation/memory cost. To investigate this idea, first, we examine the effects of using local attention mechanism on the individual segments. Then we propose a segmented recurrent transformer (SRformer) that combines segmented attention with recurrent attention. It uses recurrent accumulate and fire (RAF) layers to process information between consecutive segments. The loss caused by reducing the attention window length is compensated by updating the product of keys and values with RAF neurons' inherent recurrence. The segmented attention and lightweight RAF gates ensure the efficiency of the proposed transformer. We apply the proposed method to T5 and BART transformers. The modified models are tested on summarization datasets including CNN-dailymail and XSUM. Notably, using segmented inputs of different sizes, the proposed model achieves 4-19% higher ROUGE1 scores than the segmented transformer baseline. Compared to full attention, the proposed model largely reduces the complexity of cross attention and results in around 40% reduction in computation cost.
Implementation of MPPT Technique of Solar Module with Supervised Machine Learning
Oct 02, 2021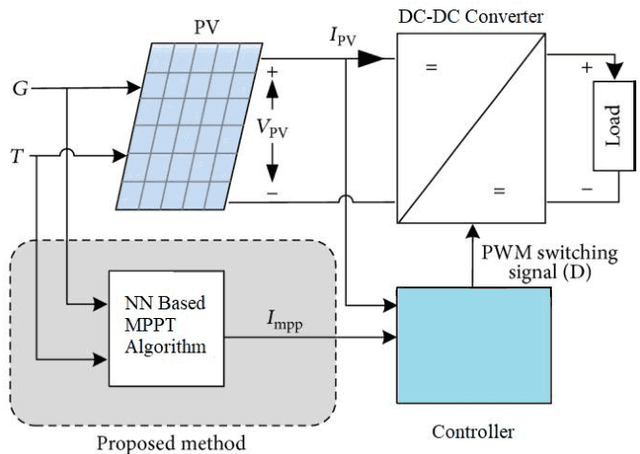

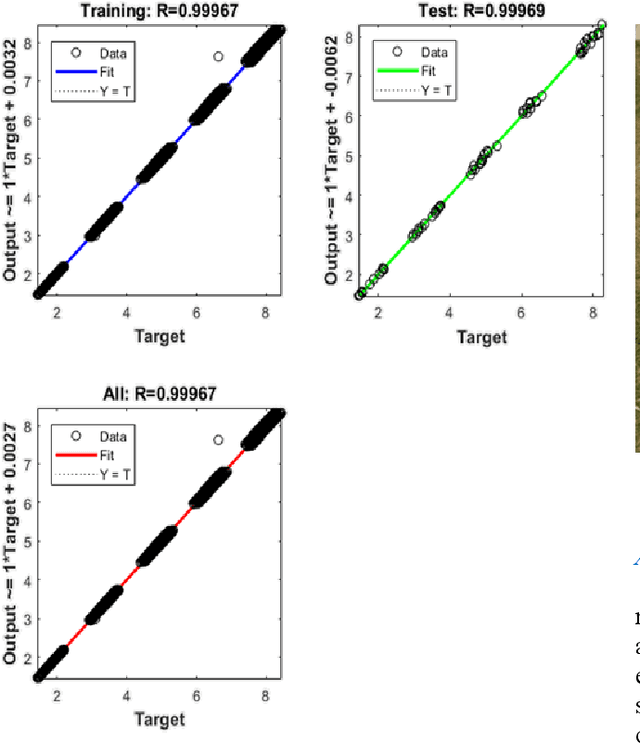

In this paper, we proposed a method using supervised ML in solar PV system for MPPT analysis. For this purpose, an overall schematic diagram of a PV system is designed and simulated to create a dataset in MATLAB/ Simulink. Thus, by analyzing the output characteristics of a solar cell, an improved MPPT algorithm on the basis of neural network (NN) method is put forward to track the maximum power point (MPP) of solar cell modules. To perform the task, Bayesian Regularization method was chosen as the training algorithm as it works best even for smaller data supporting the wide range of the train data set. The theoretical results show that the improved NN MPPT algorithm has higher efficiency compared with the Perturb and Observe method in the same environment, and the PV system can keep working at MPP without oscillation and probability of any kind of misjudgment. So it can not only reduce misjudgment, but also avoid power loss around the MPP. Moreover, we implemented the algorithm in a hardware set-up and verified the theoretical result comparing it with the empirical data.
One Timestep is All You Need: Training Spiking Neural Networks with Ultra Low Latency
Oct 01, 2021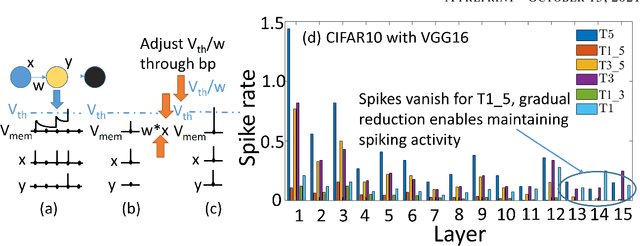
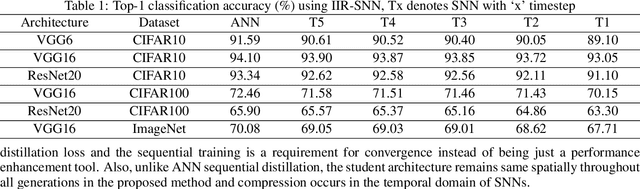
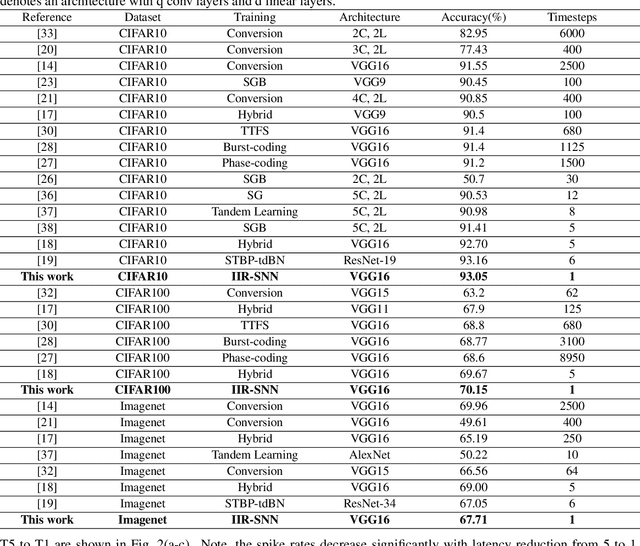
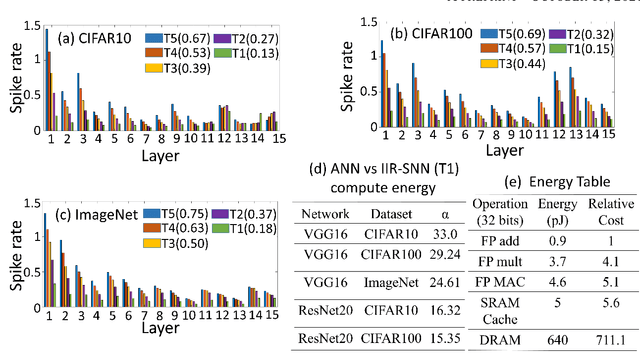
Spiking Neural Networks (SNNs) are energy efficient alternatives to commonly used deep neural networks (DNNs). Through event-driven information processing, SNNs can reduce the expensive compute requirements of DNNs considerably, while achieving comparable performance. However, high inference latency is a significant hindrance to the edge deployment of deep SNNs. Computation over multiple timesteps not only increases latency as well as overall energy budget due to higher number of operations, but also incurs memory access overhead of fetching membrane potentials, both of which lessen the energy benefits of SNNs. To overcome this bottleneck and leverage the full potential of SNNs, we propose an Iterative Initialization and Retraining method for SNNs (IIR-SNN) to perform single shot inference in the temporal axis. The method starts with an SNN trained with T timesteps (T>1). Then at each stage of latency reduction, the network trained at previous stage with higher timestep is utilized as initialization for subsequent training with lower timestep. This acts as a compression method, as the network is gradually shrunk in the temporal domain. In this paper, we use direct input encoding and choose T=5, since as per literature, it is the minimum required latency to achieve satisfactory performance on ImageNet. The proposed scheme allows us to obtain SNNs with up to unit latency, requiring a single forward pass during inference. We achieve top-1 accuracy of 93.05%, 70.15% and 67.71% on CIFAR-10, CIFAR-100 and ImageNet, respectively using VGG16, with just 1 timestep. In addition, IIR-SNNs perform inference with 5-2500X reduced latency compared to other state-of-the-art SNNs, maintaining comparable or even better accuracy. Furthermore, in comparison with standard DNNs, the proposed IIR-SNNs provide25-33X higher energy efficiency, while being comparable to them in classification performance.
Spatio-Temporal Pruning and Quantization for Low-latency Spiking Neural Networks
Apr 29, 2021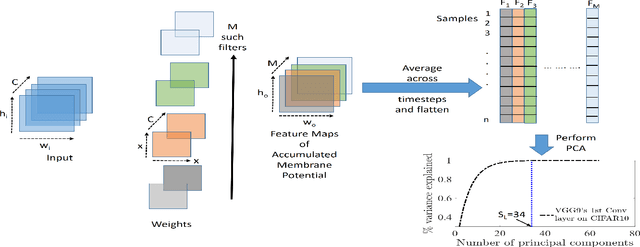
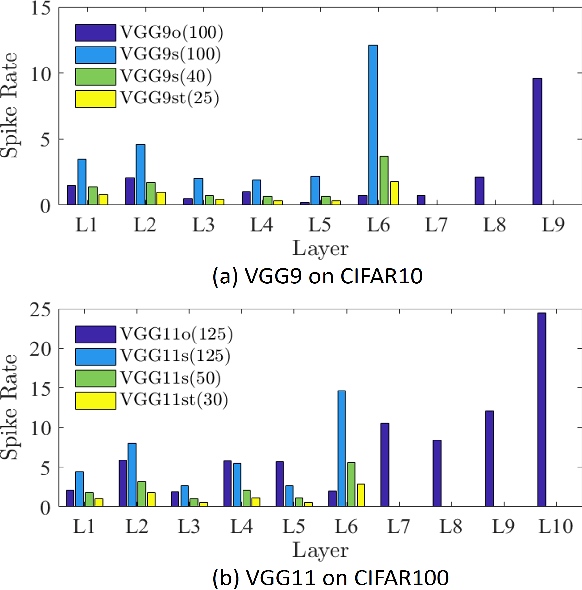
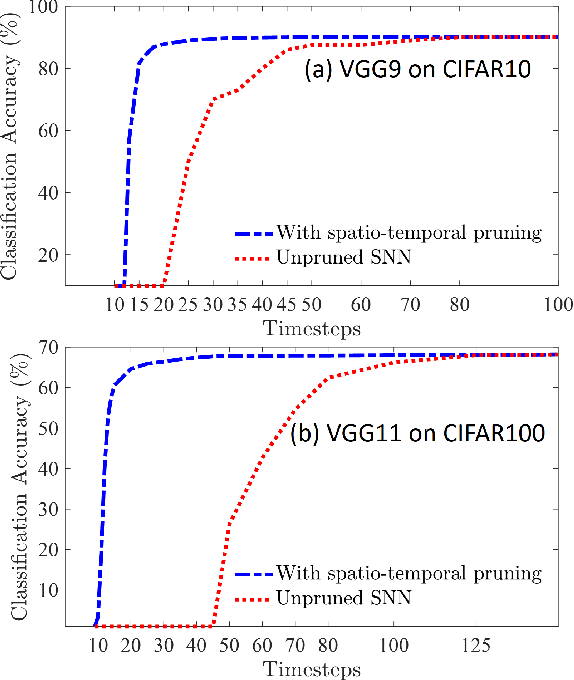
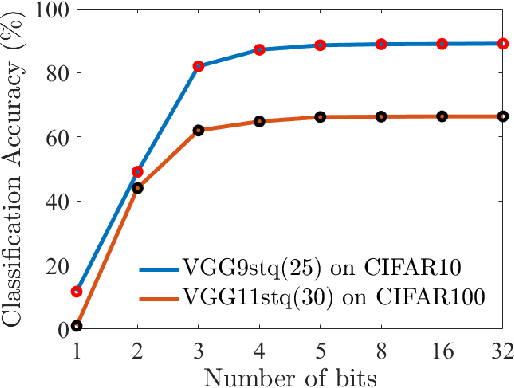
Spiking Neural Networks (SNNs) are a promising alternative to traditional deep learning methods since they perform event-driven information processing. However, a major drawback of SNNs is high inference latency. The efficiency of SNNs could be enhanced using compression methods such as pruning and quantization. Notably, SNNs, unlike their non-spiking counterparts, consist of a temporal dimension, the compression of which can lead to latency reduction. In this paper, we propose spatial and temporal pruning of SNNs. First, structured spatial pruning is performed by determining the layer-wise significant dimensions using principal component analysis of the average accumulated membrane potential of the neurons. This step leads to 10-14X model compression. Additionally, it enables inference with lower latency and decreases the spike count per inference. To further reduce latency, temporal pruning is performed by gradually reducing the timesteps while training. The networks are trained using surrogate gradient descent based backpropagation and we validate the results on CIFAR10 and CIFAR100, using VGG architectures. The spatiotemporally pruned SNNs achieve 89.04% and 66.4% accuracy on CIFAR10 and CIFAR100, respectively, while performing inference with 3-30X reduced latency compared to state-of-the-art SNNs. Moreover, they require 8-14X lesser compute energy compared to their unpruned standard deep learning counterparts. The energy numbers are obtained by multiplying the number of operations with energy per operation. These SNNs also provide 1-4% higher robustness against Gaussian noise corrupted inputs. Furthermore, we perform weight quantization and find that performance remains reasonably stable up to 5-bit quantization.