 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePanoptic Diffusion Models: co-generation of images and segmentation maps
Dec 04, 2024
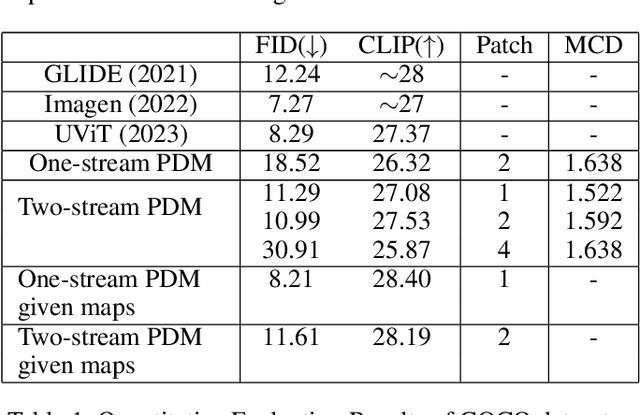
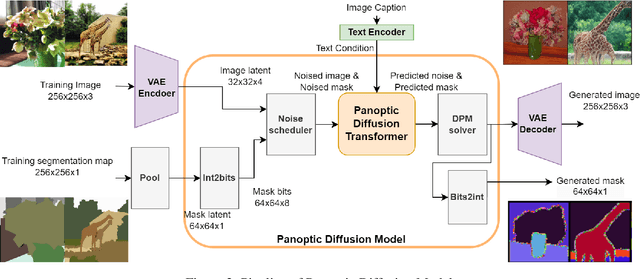
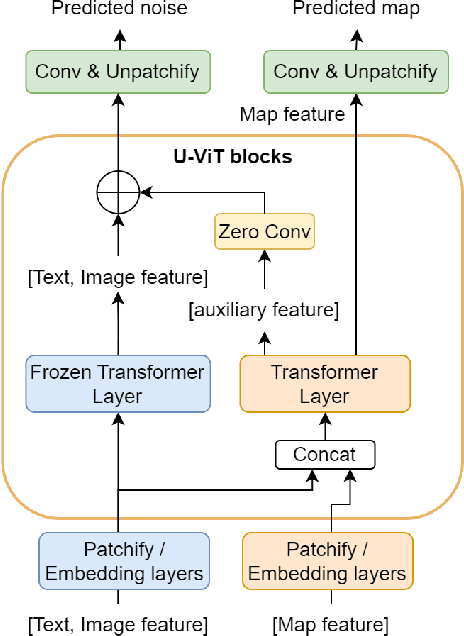
Recently, diffusion models have demonstrated impressive capabilities in text-guided and image-conditioned image generation. However, existing diffusion models cannot simultaneously generate a segmentation map of objects and a corresponding image from the prompt. Previous attempts either generate segmentation maps based on the images or provide maps as input conditions to control image generation, limiting their functionality to given inputs. Incorporating an inherent understanding of the scene layouts can improve the creativity and realism of diffusion models. To address this limitation, we present Panoptic Diffusion Model (PDM), the first model designed to generate both images and panoptic segmentation maps concurrently. PDM bridges the gap between image and text by constructing segmentation layouts that provide detailed, built-in guidance throughout the generation process. This ensures the inclusion of categories mentioned in text prompts and enriches the diversity of segments within the background. We demonstrate the effectiveness of PDM across two architectures: a unified diffusion transformer and a two-stream transformer with a pretrained backbone. To facilitate co-generation with fewer sampling steps, we incorporate a fast diffusion solver into PDM. Additionally, when ground-truth maps are available, PDM can function as a text-guided image-to-image generation model. Finally, we propose a novel metric for evaluating the quality of generated maps and show that PDM achieves state-of-the-art results in image generation with implicit scene control.
Prompt-Based Bias Calibration for Better Zero/Few-Shot Learning of Language Models
Feb 15, 2024Prompt learning is susceptible to intrinsic bias present in pre-trained language models (LMs), resulting in sub-optimal performance of prompt-based zero/few-shot learning. In this work, we propose a null-input prompting method to calibrate intrinsic bias encoded in pre-trained LMs. Different from prior efforts that address intrinsic bias primarily for social fairness and often involve excessive computational cost, our objective is to explore enhancing LMs' performance in downstream zero/few-shot learning while emphasizing the efficiency of intrinsic bias calibration. Specifically, we leverage a diverse set of auto-selected null-meaning inputs generated from GPT-4 to prompt pre-trained LMs for intrinsic bias probing. Utilizing the bias-reflected probability distribution, we formulate a distribution disparity loss for bias calibration, where we exclusively update bias parameters ($0.1\%$ of total parameters) of LMs towards equal probability distribution. Experimental results show that the calibration promotes an equitable starting point for LMs while preserving language modeling abilities. Across a wide range of datasets, including sentiment analysis and topic classification, our method significantly improves zero/few-shot learning performance of LMs for both in-context learning and prompt-based fine-tuning (on average $9\%$ and $2\%$, respectively).
Segmented Recurrent Transformer: An Efficient Sequence-to-Sequence Model
May 24, 2023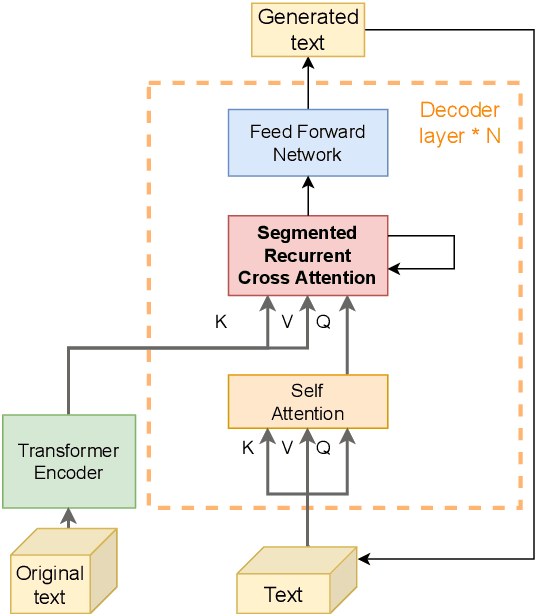

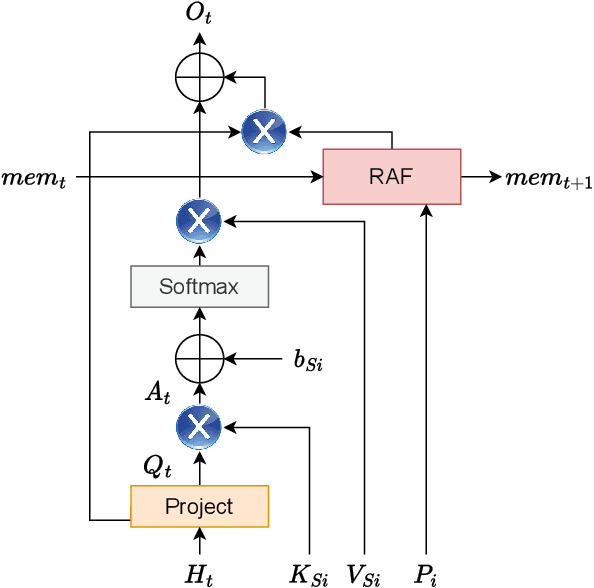
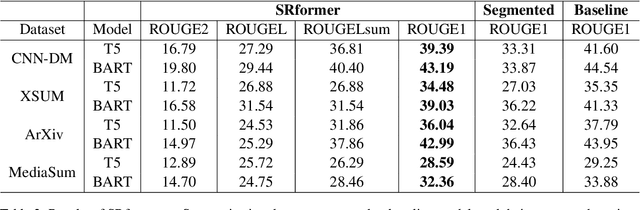
Transformers have shown dominant performance across a range of domains including language and vision. However, their computational cost grows quadratically with the sequence length, making their usage prohibitive for resource-constrained applications. To counter this, our approach is to divide the whole sequence into segments. The information across segments can then be aggregated using neurons with recurrence leveraging their inherent memory. Such an approach leads to models with sequential processing capability at a lower computation/memory cost. To investigate this idea, first, we examine the effects of using local attention mechanism on the individual segments. Then we propose a segmented recurrent transformer (SRformer) that combines segmented attention with recurrent attention. It uses recurrent accumulate and fire (RAF) layers to process information between consecutive segments. The loss caused by reducing the attention window length is compensated by updating the product of keys and values with RAF neurons' inherent recurrence. The segmented attention and lightweight RAF gates ensure the efficiency of the proposed transformer. We apply the proposed method to T5 and BART transformers. The modified models are tested on summarization datasets including CNN-dailymail and XSUM. Notably, using segmented inputs of different sizes, the proposed model achieves 4-19% higher ROUGE1 scores than the segmented transformer baseline. Compared to full attention, the proposed model largely reduces the complexity of cross attention and results in around 40% reduction in computation cost.
Complexity-aware Adaptive Training and Inference for Edge-Cloud Distributed AI Systems
Sep 14, 2021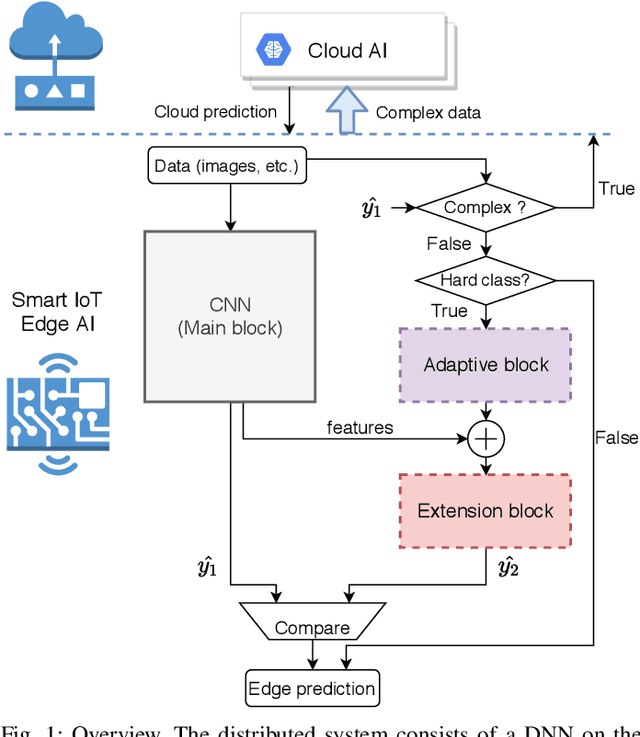
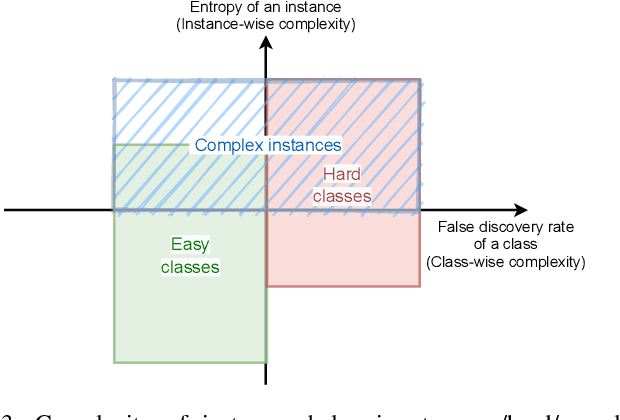
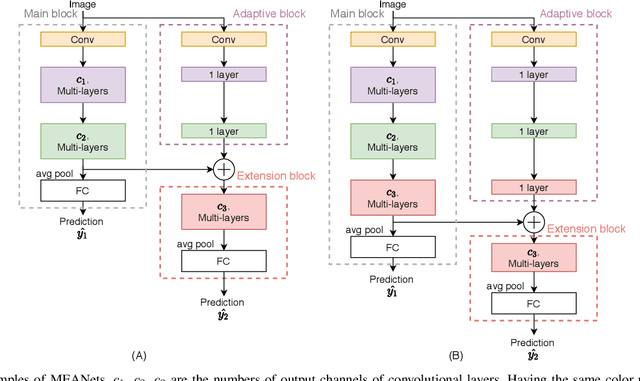
The ubiquitous use of IoT and machine learning applications is creating large amounts of data that require accurate and real-time processing. Although edge-based smart data processing can be enabled by deploying pretrained models, the energy and memory constraints of edge devices necessitate distributed deep learning between the edge and the cloud for complex data. In this paper, we propose a distributed AI system to exploit both the edge and the cloud for training and inference. We propose a new architecture, MEANet, with a main block, an extension block, and an adaptive block for the edge. The inference process can terminate at either the main block, the extension block, or the cloud. The MEANet is trained to categorize inputs into easy/hard/complex classes. The main block identifies instances of easy/hard classes and classifies easy classes with high confidence. Only data with high probabilities of belonging to hard classes would be sent to the extension block for prediction. Further, only if the neural network at the edge shows low confidence in the prediction, the instance is considered complex and sent to the cloud for further processing. The training technique lends to the majority of inference on edge devices while going to the cloud only for a small set of complex jobs, as determined by the edge. The performance of the proposed system is evaluated via extensive experiments using modified models of ResNets and MobileNetV2 on CIFAR-100 and ImageNet datasets. The results show that the proposed distributed model has improved accuracy and energy consumption, indicating its capacity to adapt.
Conditionally Deep Hybrid Neural Networks Across Edge and Cloud
May 21, 2020

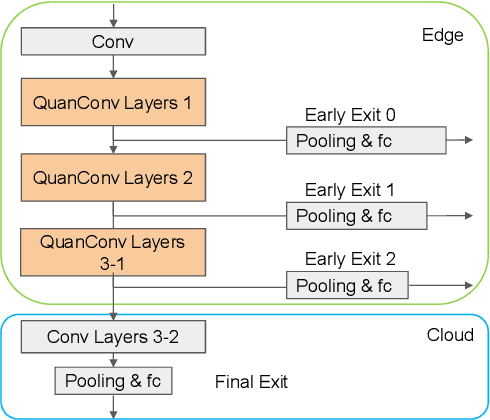

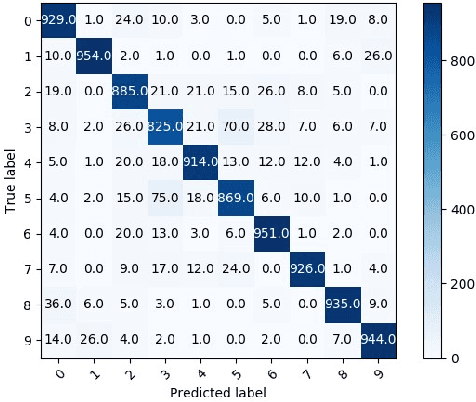
The pervasiveness of "Internet-of-Things" in our daily life has led to a recent surge in fog computing, encompassing a collaboration of cloud computing and edge intelligence. To that effect, deep learning has been a major driving force towards enabling such intelligent systems. However, growing model sizes in deep learning pose a significant challenge towards deployment in resource-constrained edge devices. Moreover, in a distributed intelligence environment, efficient workload distribution is necessary between edge and cloud systems. To address these challenges, we propose a conditionally deep hybrid neural network for enabling AI-based fog computing. The proposed network can be deployed in a distributed manner, consisting of quantized layers and early exits at the edge and full-precision layers on the cloud. During inference, if an early exit has high confidence in the classification results, it would allow samples to exit at the edge, and the deeper layers on the cloud are activated conditionally, which can lead to improved energy efficiency and inference latency. We perform an extensive design space exploration with the goal of minimizing energy consumption at the edge while achieving state-of-the-art classification accuracies on image classification tasks. We show that with binarized layers at the edge, the proposed conditional hybrid network can process 65% of inferences at the edge, leading to 5.5x computational energy reduction with minimal accuracy degradation on CIFAR-10 dataset. For the more complex dataset CIFAR-100, we observe that the proposed network with 4-bit quantization at the edge achieves 52% early classification at the edge with 4.8x energy reduction. The analysis gives us insights on designing efficient hybrid networks which achieve significantly higher energy efficiency than full-precision networks for edge-cloud based distributed intelligence systems.