 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePanoptic Diffusion Models: co-generation of images and segmentation maps
Paper and Code
Dec 04, 2024
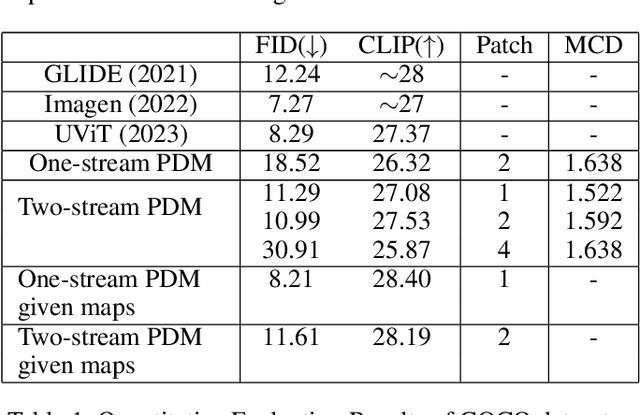
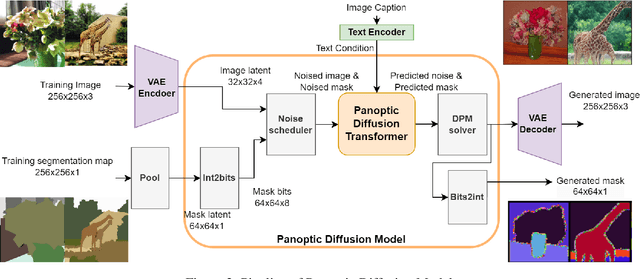
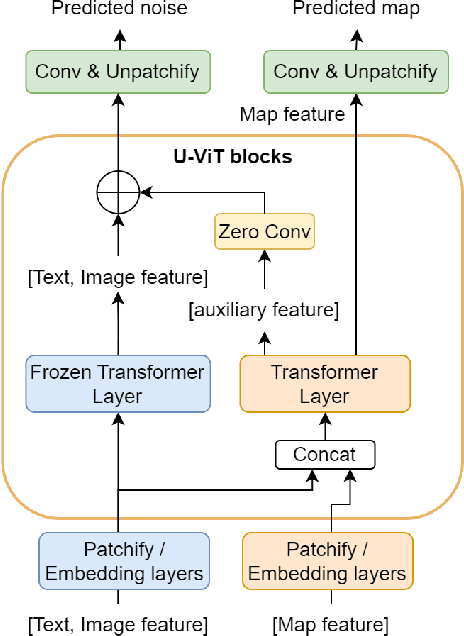
Recently, diffusion models have demonstrated impressive capabilities in text-guided and image-conditioned image generation. However, existing diffusion models cannot simultaneously generate a segmentation map of objects and a corresponding image from the prompt. Previous attempts either generate segmentation maps based on the images or provide maps as input conditions to control image generation, limiting their functionality to given inputs. Incorporating an inherent understanding of the scene layouts can improve the creativity and realism of diffusion models. To address this limitation, we present Panoptic Diffusion Model (PDM), the first model designed to generate both images and panoptic segmentation maps concurrently. PDM bridges the gap between image and text by constructing segmentation layouts that provide detailed, built-in guidance throughout the generation process. This ensures the inclusion of categories mentioned in text prompts and enriches the diversity of segments within the background. We demonstrate the effectiveness of PDM across two architectures: a unified diffusion transformer and a two-stream transformer with a pretrained backbone. To facilitate co-generation with fewer sampling steps, we incorporate a fast diffusion solver into PDM. Additionally, when ground-truth maps are available, PDM can function as a text-guided image-to-image generation model. Finally, we propose a novel metric for evaluating the quality of generated maps and show that PDM achieves state-of-the-art results in image generation with implicit scene control.