 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTDP Based Pruning of Connections and Weight Quantization in Spiking Neural Networks for Energy Efficient Recognition
Paper and Code
Oct 12, 2017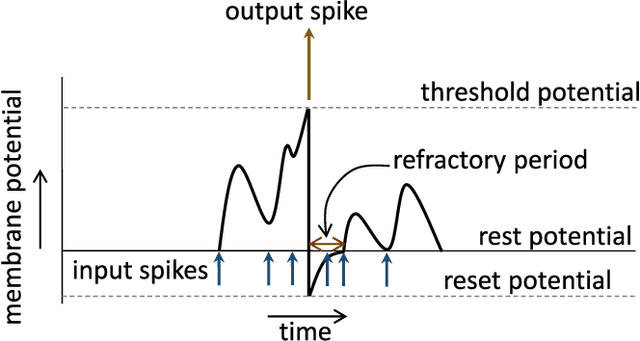
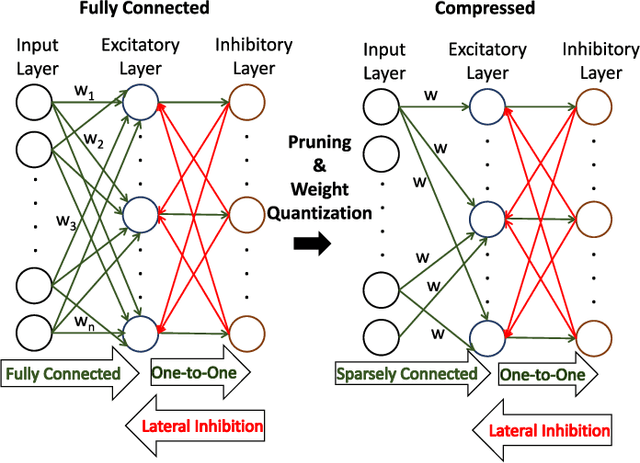
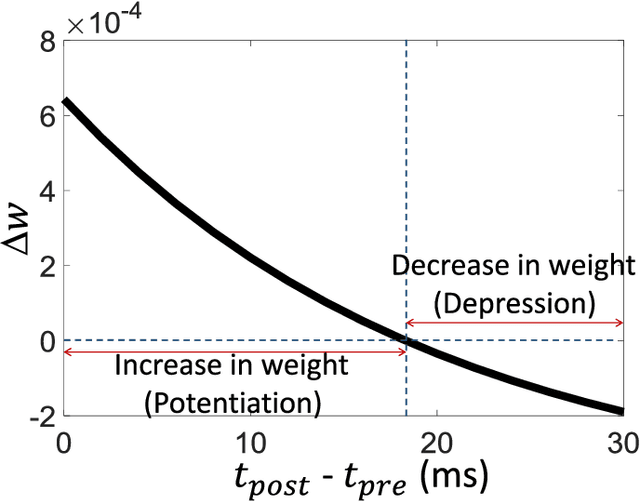
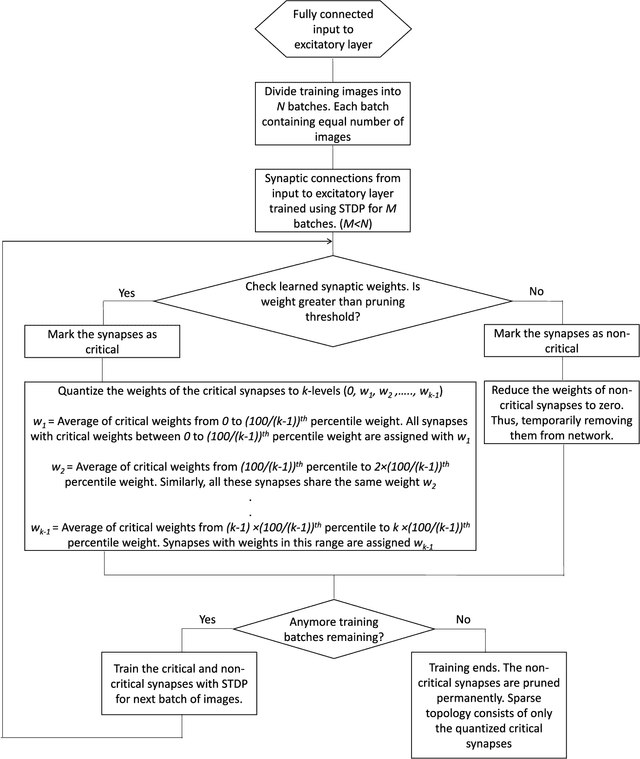
Spiking Neural Networks (SNNs) with a large number of weights and varied weight distribution can be difficult to implement in emerging in-memory computing hardware due to the limitations on crossbar size (implementing dot product), the constrained number of conductance levels in non-CMOS devices and the power budget. We present a sparse SNN topology where non-critical connections are pruned to reduce the network size and the remaining critical synapses are weight quantized to accommodate for limited conductance levels. Pruning is based on the power law weight-dependent Spike Timing Dependent Plasticity (STDP) model; synapses between pre- and post-neuron with high spike correlation are retained, whereas synapses with low correlation or uncorrelated spiking activity are pruned. The weights of the retained connections are quantized to the available number of conductance levels. The process of pruning non-critical connections and quantizing the weights of critical synapses is performed at regular intervals during training. We evaluated our sparse and quantized network on MNIST dataset and on a subset of images from Caltech-101 dataset. The compressed topology achieved a classification accuracy of 90.1% (91.6%) on the MNIST (Caltech-101) dataset with 3.1x (2.2x) and 4x (2.6x) improvement in energy and area, respectively. The compressed topology is energy and area efficient while maintaining the same classification accuracy of a 2-layer fully connected SNN topology.