 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTSkips: Efficiency Through Explicit Temporal Delay Connections in Spiking Neural Networks
Nov 22, 2024



Spiking Neural Networks (SNNs) with their bio-inspired Leaky Integrate-and-Fire (LIF) neurons inherently capture temporal information. This makes them well-suited for sequential tasks like processing event-based data from Dynamic Vision Sensors (DVS) and event-based speech tasks. Harnessing the temporal capabilities of SNNs requires mitigating vanishing spikes during training, capturing spatio-temporal patterns and enhancing precise spike timing. To address these challenges, we propose TSkips, augmenting SNN architectures with forward and backward skip connections that incorporate explicit temporal delays. These connections capture long-term spatio-temporal dependencies and facilitate better spike flow over long sequences. The introduction of TSkips creates a vast search space of possible configurations, encompassing skip positions and time delay values. To efficiently navigate this search space, this work leverages training-free Neural Architecture Search (NAS) to identify optimal network structures and corresponding delays. We demonstrate the effectiveness of our approach on four event-based datasets: DSEC-flow for optical flow estimation, DVS128 Gesture for hand gesture recognition and Spiking Heidelberg Digits (SHD) and Spiking Speech Commands (SSC) for speech recognition. Our method achieves significant improvements across these datasets: up to 18% reduction in Average Endpoint Error (AEE) on DSEC-flow, 8% increase in classification accuracy on DVS128 Gesture, and up to 8% and 16% higher classification accuracy on SHD and SSC, respectively.
FEDORA: Flying Event Dataset fOr Reactive behAvior
May 22, 2023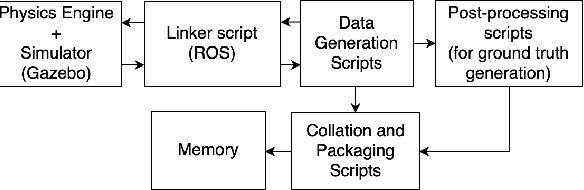
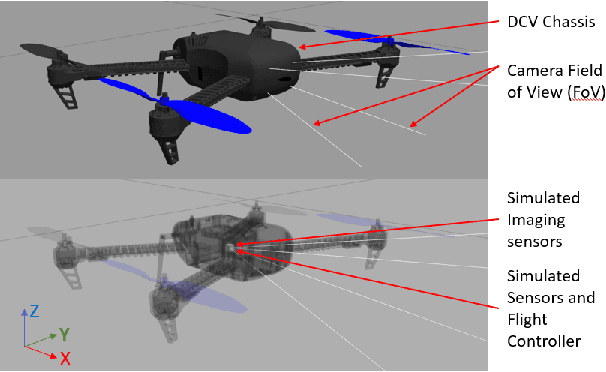


The ability of living organisms to perform complex high speed manoeuvers in flight with a very small number of neurons and an incredibly low failure rate highlights the efficacy of these resource-constrained biological systems. Event-driven hardware has emerged, in recent years, as a promising avenue for implementing complex vision tasks in resource-constrained environments. Vision-based autonomous navigation and obstacle avoidance consists of several independent but related tasks such as optical flow estimation, depth estimation, Simultaneous Localization and Mapping (SLAM), object detection, and recognition. To ensure coherence between these tasks, it is imperative that they be trained on a single dataset. However, most existing datasets provide only a selected subset of the required data. This makes inter-network coherence difficult to achieve. Another limitation of existing datasets is the limited temporal resolution they provide. To address these limitations, we present FEDORA, a first-of-its-kind fully synthetic dataset for vision-based tasks, with ground truths for depth, pose, ego-motion, and optical flow. FEDORA is the first dataset to provide optical flow at three different frequencies - 10Hz, 25Hz, and 50Hz
Event-based Temporally Dense Optical Flow Estimation with Sequential Neural Networks
Oct 03, 2022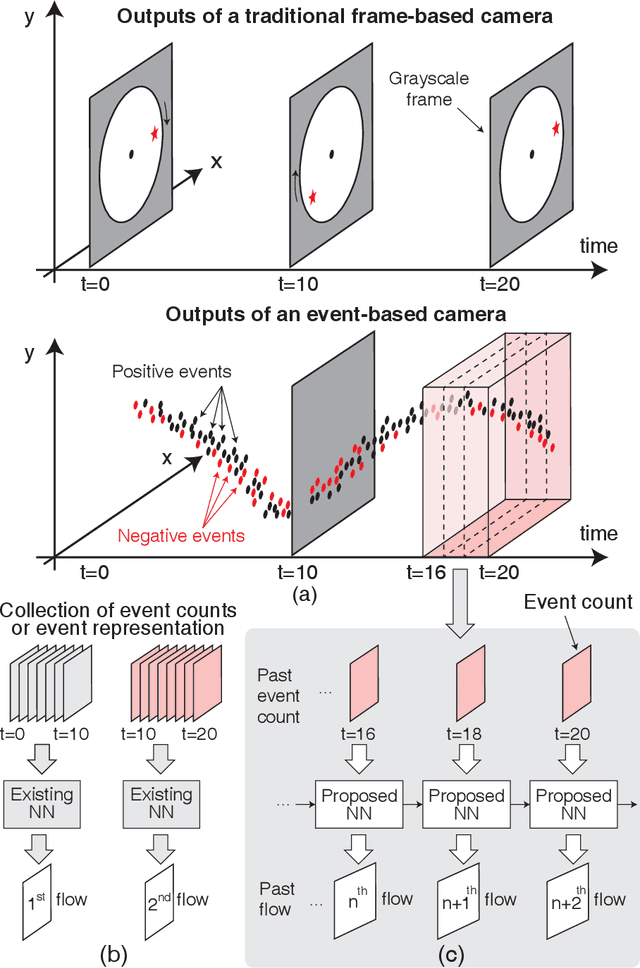
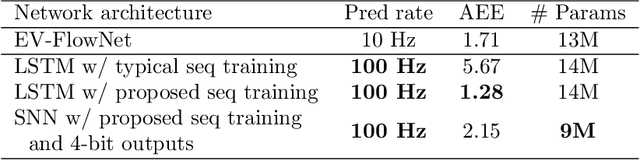
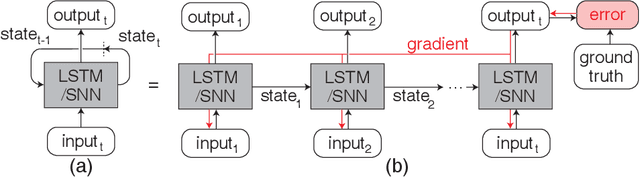
Prior works on event-based optical flow estimation have investigated several gradient-based learning methods to train neural networks for predicting optical flow. However, they do not utilize the fast data rate of event data streams and rely on a spatio-temporal representation constructed from a collection of events over a fixed period of time (often between two grayscale frames). As a result, optical flow is only evaluated at a frequency much lower than the rate data is produced by an event-based camera, leading to a temporally sparse optical flow estimation. To predict temporally dense optical flow, we cast the problem as a sequential learning task and propose a training methodology to train sequential networks for continuous prediction on an event stream. We propose two types of networks: one focused on performance and another focused on compute efficiency. We first train long-short term memory networks (LSTMs) on the DSEC dataset and demonstrated 10x temporally dense optical flow estimation over existing flow estimation approaches. The additional benefit of having a memory to draw long temporal correlations back in time results in a 19.7% improvement in flow prediction accuracy of LSTMs over similar networks with no memory elements. We subsequently show that the inherent recurrence of spiking neural networks (SNNs) enables them to learn and estimate temporally dense optical flow with 31.8% lesser parameters than LSTM, but with a slightly increased error. This demonstrates potential for energy-efficient implementation of fast optical flow prediction using SNNs.
Spiking Neural Networks with Improved Inherent Recurrence Dynamics for Sequential Learning
Sep 04, 2021
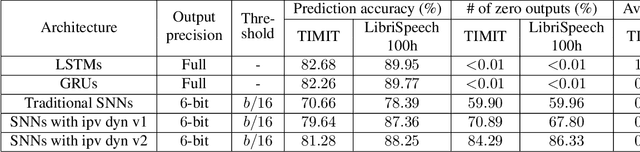
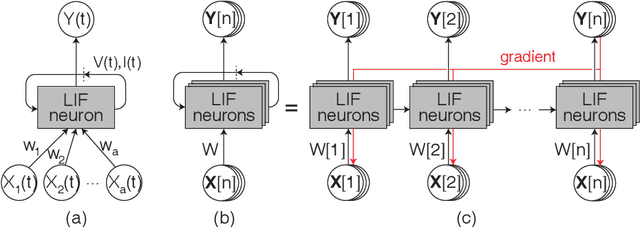

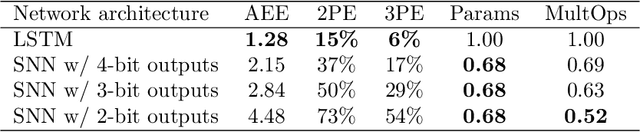
Spiking neural networks (SNNs) with leaky integrate and fire (LIF) neurons, can be operated in an event-driven manner and have internal states to retain information over time, providing opportunities for energy-efficient neuromorphic computing, especially on edge devices. Note, however, many representative works on SNNs do not fully demonstrate the usefulness of their inherent recurrence (membrane potentials retaining information about the past) for sequential learning. Most of the works train SNNs to recognize static images by artificially expanded input representation in time through rate coding. We show that SNNs can be trained for sequential tasks and propose modifications to a network of LIF neurons that enable internal states to learn long sequences and make their inherent recurrence resilient to the vanishing gradient problem. We then develop a training scheme to train the proposed SNNs with improved inherent recurrence dynamics. Our training scheme allows spiking neurons to produce multi-bit outputs (as opposed to binary spikes) which help mitigate the mismatch between a derivative of spiking neurons' activation function and a surrogate derivative used to overcome spiking neurons' non-differentiability. Our experimental results indicate that the proposed SNN architecture on TIMIT and LibriSpeech 100h dataset yields accuracy comparable to that of LSTMs (within 1.10% and 0.36%, respectively), but with 2x fewer parameters than LSTMs. The sparse SNN outputs also lead to 10.13x and 11.14x savings in multiplication operations compared to GRUs, which is generally con-sidered as a lightweight alternative to LSTMs, on TIMIT and LibriSpeech 100h datasets, respectively.
Reinforcement Learning with Low-Complexity Liquid State Machines
Jun 04, 2019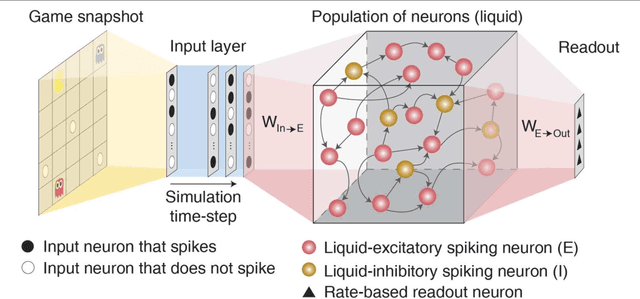


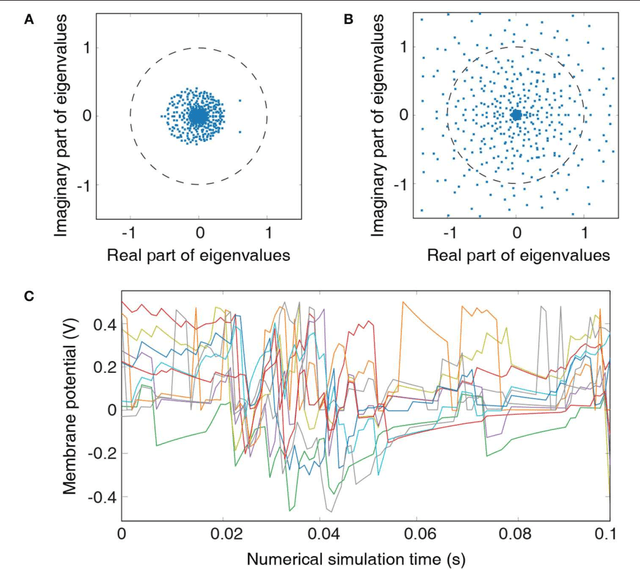
We propose reinforcement learning on simple networks consisting of random connections of spiking neurons (both recurrent and feed-forward) that can learn complex tasks with very little trainable parameters. Such sparse and randomly interconnected recurrent spiking networks exhibit highly non-linear dynamics that transform the inputs into rich high-dimensional representations based on past context. The random input representations can be efficiently interpreted by an output (or readout) layer with trainable parameters. Systematic initialization of the random connections and training of the readout layer using Q-learning algorithm enable such small random spiking networks to learn optimally and achieve the same learning efficiency as humans on complex reinforcement learning tasks like Atari games. The spike-based approach using small random recurrent networks provides a computationally efficient alternative to state-of-the-art deep reinforcement learning networks with several layers of trainable parameters. The low-complexity spiking networks can lead to improved energy efficiency in event-driven neuromorphic hardware for complex reinforcement learning tasks.
A Comprehensive Analysis on Adversarial Robustness of Spiking Neural Networks
May 07, 2019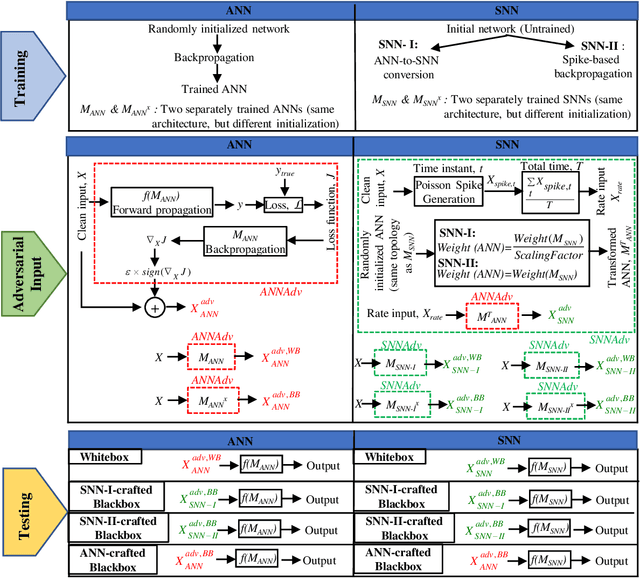
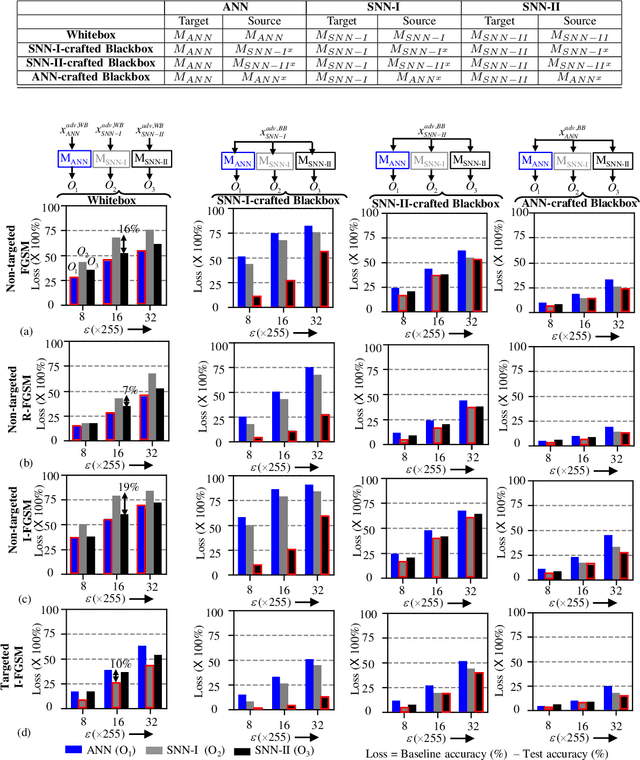
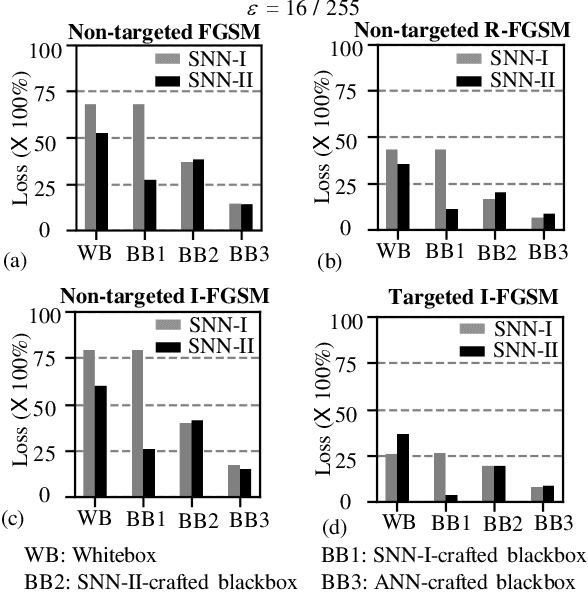
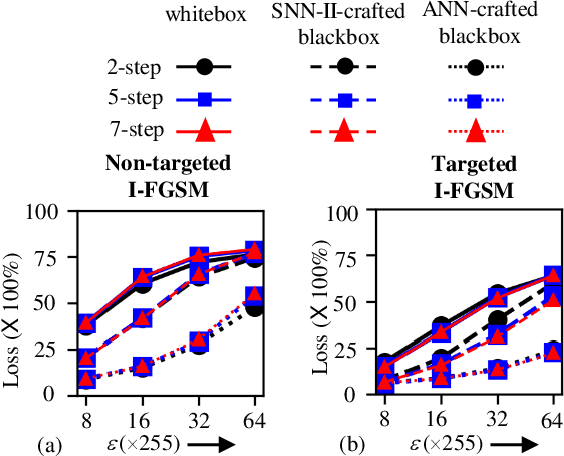
In this era of machine learning models, their functionality is being threatened by adversarial attacks. In the face of this struggle for making artificial neural networks robust, finding a model, resilient to these attacks, is very important. In this work, we present, for the first time, a comprehensive analysis of the behavior of more bio-plausible networks, namely Spiking Neural Network (SNN) under state-of-the-art adversarial tests. We perform a comparative study of the accuracy degradation between conventional VGG-9 Artificial Neural Network (ANN) and equivalent spiking network with CIFAR-10 dataset in both whitebox and blackbox setting for different types of single-step and multi-step FGSM (Fast Gradient Sign Method) attacks. We demonstrate that SNNs tend to show more resiliency compared to ANN under black-box attack scenario. Additionally, we find that SNN robustness is largely dependent on the corresponding training mechanism. We observe that SNNs trained by spike-based backpropagation are more adversarially robust than the ones obtained by ANN-to-SNN conversion rules in several whitebox and blackbox scenarios. Finally, we also propose a simple, yet, effective framework for crafting adversarial attacks from SNNs. Our results suggest that attacks crafted from SNNs following our proposed method are much stronger than those crafted from ANNs.