 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopoPrune: Robust Data Pruning via Unified Latent Space Topology
Feb 02, 2026Geometric data pruning methods, while practical for leveraging pretrained models, are fundamentally unstable. Their reliance on extrinsic geometry renders them highly sensitive to latent space perturbations, causing performance to degrade during cross-architecture transfer or in the presence of feature noise. We introduce TopoPrune, a framework which resolves this challenge by leveraging topology to capture the stable, intrinsic structure of data. TopoPrune operates at two scales, (1) utilizing a topology-aware manifold approximation to establish a global low-dimensional embedding of the dataset. Subsequently, (2) it employs differentiable persistent homology to perform a local topological optimization on the manifold embeddings, ranking samples by their structural complexity. We demonstrate that our unified dual-scale topological approach ensures high accuracy and precision, particularly at significant dataset pruning rates (e.g., 90%). Furthermore, through the inherent stability properties of topology, TopoPrune is (a) exceptionally robust to noise perturbations of latent feature embeddings and (b) demonstrates superior transferability across diverse network architectures. This study demonstrates a promising avenue towards stable and principled topology-based frameworks for robust data-efficient learning.
TraceNAS: Zero-shot LLM Pruning via Gradient Trace Correlation
Feb 02, 2026Structured pruning is essential for efficient deployment of Large Language Models (LLMs). The varying sensitivity of LLM sub-blocks to pruning necessitates the identification of optimal non-uniformly pruned models. Existing methods evaluate the importance of layers, attention heads, or weight channels in isolation. Such localized focus ignores the complex global structural dependencies that exist across the model. Training-aware structured pruning addresses global dependencies, but its computational cost can be just as expensive as post-pruning training. To alleviate the computational burden of training-aware pruning and capture global structural dependencies, we propose TraceNAS, a training-free Neural Architecture Search (NAS) framework that jointly explores structured pruning of LLM depth and width. TraceNAS identifies pruned models that maintain a high degree of loss landscape alignment with the pretrained model using a scale-invariant zero-shot proxy, effectively selecting models that exhibit maximal performance potential during post-pruning training. TraceNAS is highly efficient, enabling high-fidelity discovery of pruned models on a single GPU in 8.5 hours, yielding a 10$\times$ reduction in GPU-hours compared to training-aware methods. Evaluations on the Llama and Qwen families demonstrate that TraceNAS is competitive with training-aware baselines across commonsense and reasoning benchmarks.
TRIM: Token-wise Attention-Derived Saliency for Data-Efficient Instruction Tuning
Oct 08, 2025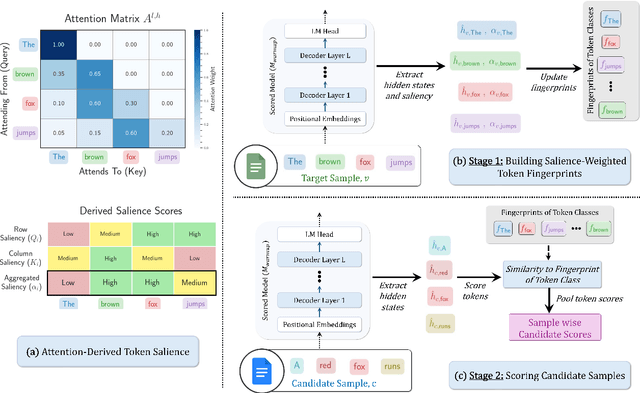
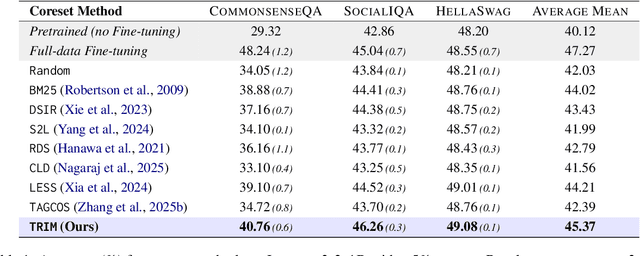
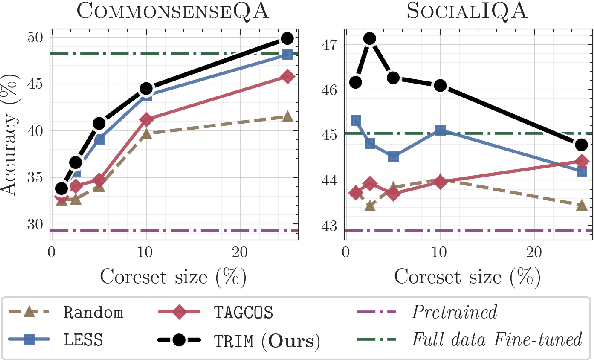

Instruction tuning is essential for aligning large language models (LLMs) to downstream tasks and commonly relies on large, diverse corpora. However, small, high-quality subsets, known as coresets, can deliver comparable or superior results, though curating them remains challenging. Existing methods often rely on coarse, sample-level signals like gradients, an approach that is computationally expensive and overlooks fine-grained features. To address this, we introduce TRIM (Token Relevance via Interpretable Multi-layer Attention), a forward-only, token-centric framework. Instead of using gradients, TRIM operates by matching underlying representational patterns identified via attention-based "fingerprints" from a handful of target samples. Such an approach makes TRIM highly efficient and uniquely sensitive to the structural features that define a task. Coresets selected by our method consistently outperform state-of-the-art baselines by up to 9% on downstream tasks and even surpass the performance of full-data fine-tuning in some settings. By avoiding expensive backward passes, TRIM achieves this at a fraction of the computational cost. These findings establish TRIM as a scalable and efficient alternative for building high-quality instruction-tuning datasets.
Finding the Muses: Identifying Coresets through Loss Trajectories
Mar 12, 2025Deep learning models achieve state-of-the-art performance across domains but face scalability challenges in real-time or resource-constrained scenarios. To address this, we propose Loss Trajectory Correlation (LTC), a novel metric for coreset selection that identifies critical training samples driving generalization. $LTC$ quantifies the alignment between training sample loss trajectories and validation set loss trajectories, enabling the construction of compact, representative subsets. Unlike traditional methods with computational and storage overheads that are infeasible to scale to large datasets, $LTC$ achieves superior efficiency as it can be computed as a byproduct of training. Our results on CIFAR-100 and ImageNet-1k show that $LTC$ consistently achieves accuracy on par with or surpassing state-of-the-art coreset selection methods, with any differences remaining under 1%. LTC also effectively transfers across various architectures, including ResNet, VGG, DenseNet, and Swin Transformer, with minimal performance degradation (<2%). Additionally, LTC offers insights into training dynamics, such as identifying aligned and conflicting sample behaviors, at a fraction of the computational cost of traditional methods. This framework paves the way for scalable coreset selection and efficient dataset optimization.
Energy-Efficient Autonomous Aerial Navigation with Dynamic Vision Sensors: A Physics-Guided Neuromorphic Approach
Feb 09, 2025



Vision-based object tracking is a critical component for achieving autonomous aerial navigation, particularly for obstacle avoidance. Neuromorphic Dynamic Vision Sensors (DVS) or event cameras, inspired by biological vision, offer a promising alternative to conventional frame-based cameras. These cameras can detect changes in intensity asynchronously, even in challenging lighting conditions, with a high dynamic range and resistance to motion blur. Spiking neural networks (SNNs) are increasingly used to process these event-based signals efficiently and asynchronously. Meanwhile, physics-based artificial intelligence (AI) provides a means to incorporate system-level knowledge into neural networks via physical modeling. This enhances robustness, energy efficiency, and provides symbolic explainability. In this work, we present a neuromorphic navigation framework for autonomous drone navigation. The focus is on detecting and navigating through moving gates while avoiding collisions. We use event cameras for detecting moving objects through a shallow SNN architecture in an unsupervised manner. This is combined with a lightweight energy-aware physics-guided neural network (PgNN) trained with depth inputs to predict optimal flight times, generating near-minimum energy paths. The system is implemented in the Gazebo simulator and integrates a sensor-fused vision-to-planning neuro-symbolic framework built with the Robot Operating System (ROS) middleware. This work highlights the future potential of integrating event-based vision with physics-guided planning for energy-efficient autonomous navigation, particularly for low-latency decision-making.
FEDORA: Flying Event Dataset fOr Reactive behAvior
May 22, 2023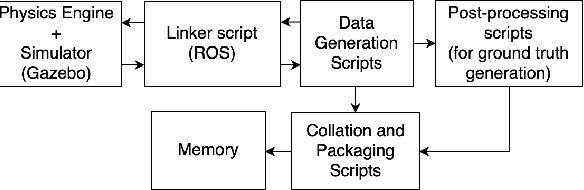
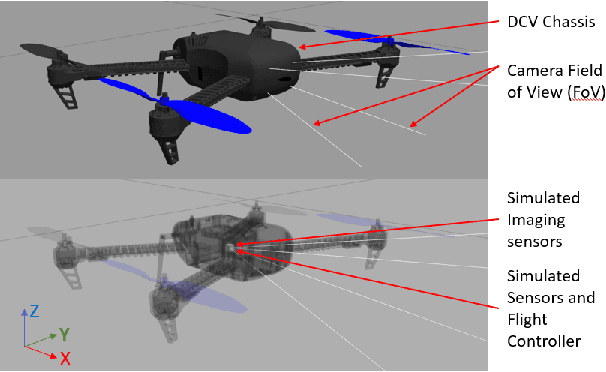


The ability of living organisms to perform complex high speed manoeuvers in flight with a very small number of neurons and an incredibly low failure rate highlights the efficacy of these resource-constrained biological systems. Event-driven hardware has emerged, in recent years, as a promising avenue for implementing complex vision tasks in resource-constrained environments. Vision-based autonomous navigation and obstacle avoidance consists of several independent but related tasks such as optical flow estimation, depth estimation, Simultaneous Localization and Mapping (SLAM), object detection, and recognition. To ensure coherence between these tasks, it is imperative that they be trained on a single dataset. However, most existing datasets provide only a selected subset of the required data. This makes inter-network coherence difficult to achieve. Another limitation of existing datasets is the limited temporal resolution they provide. To address these limitations, we present FEDORA, a first-of-its-kind fully synthetic dataset for vision-based tasks, with ground truths for depth, pose, ego-motion, and optical flow. FEDORA is the first dataset to provide optical flow at three different frequencies - 10Hz, 25Hz, and 50Hz
DOTIE -- Detecting Objects through Temporal Isolation of Events using a Spiking Architecture
Oct 03, 2022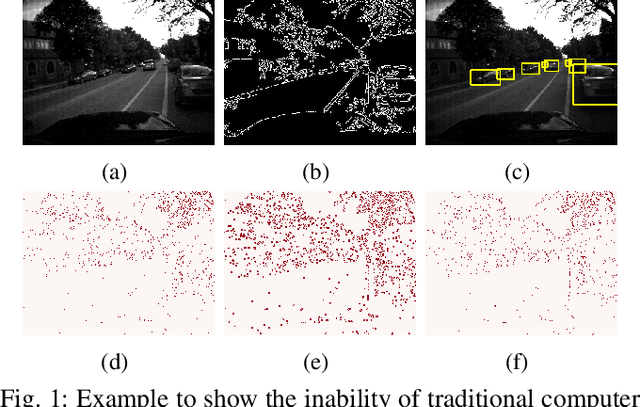
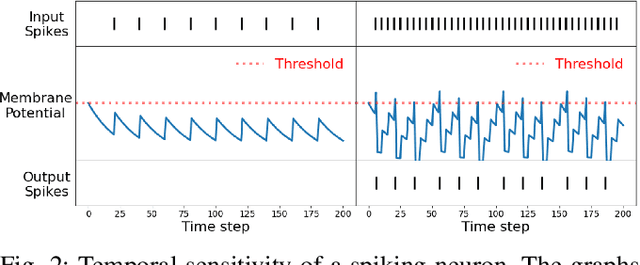
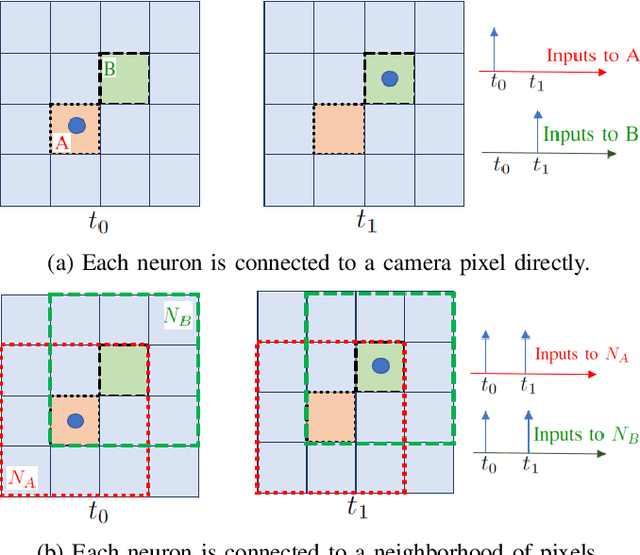
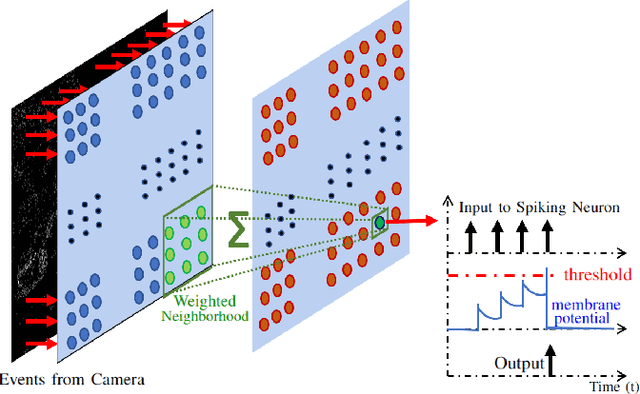
Vision-based autonomous navigation systems rely on fast and accurate object detection algorithms to avoid obstacles. Algorithms and sensors designed for such systems need to be computationally efficient, due to the limited energy of the hardware used for deployment. Biologically inspired event cameras are a good candidate as a vision sensor for such systems due to their speed, energy efficiency, and robustness to varying lighting conditions. However, traditional computer vision algorithms fail to work on event-based outputs, as they lack photometric features such as light intensity and texture. In this work, we propose a novel technique that utilizes the temporal information inherently present in the events to efficiently detect moving objects. Our technique consists of a lightweight spiking neural architecture that is able to separate events based on the speed of the corresponding objects. These separated events are then further grouped spatially to determine object boundaries. This method of object detection is both asynchronous and robust to camera noise. In addition, it shows good performance in scenarios with events generated by static objects in the background, where existing event-based algorithms fail. We show that by utilizing our architecture, autonomous navigation systems can have minimal latency and energy overheads for performing object detection.
TOFU: Towards Obfuscated Federated Updates by Encoding Weight Updates into Gradients from Proxy Data
Jan 21, 2022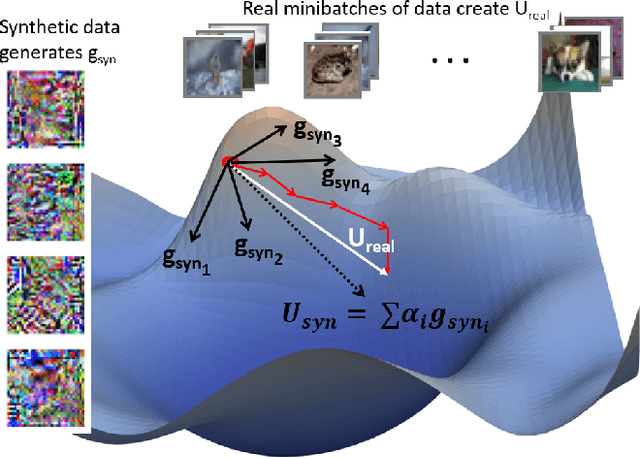
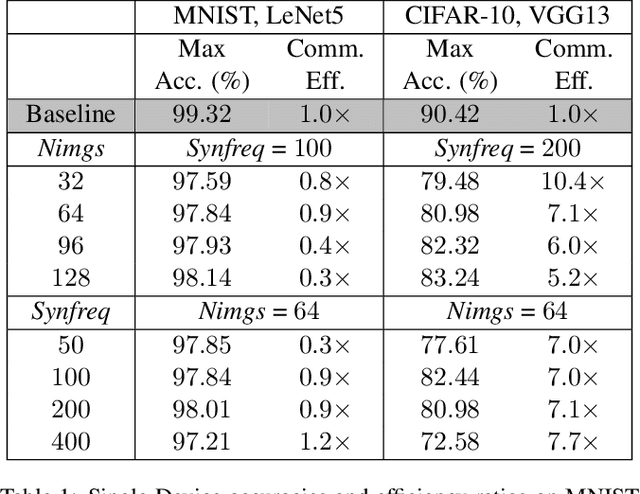

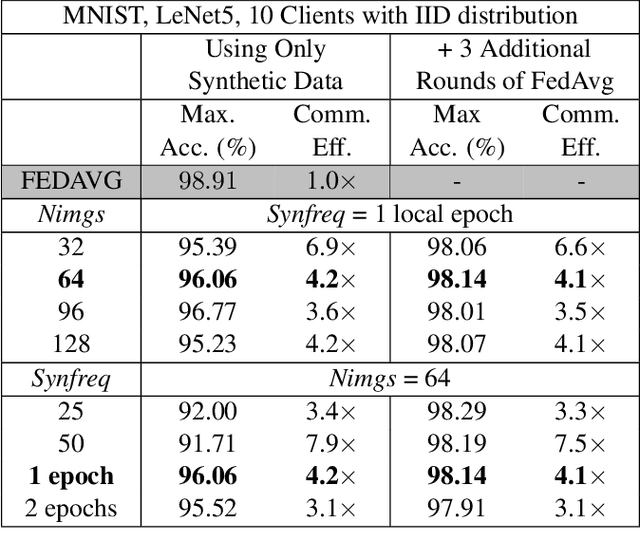
Advances in Federated Learning and an abundance of user data have enabled rich collaborative learning between multiple clients, without sharing user data. This is done via a central server that aggregates learning in the form of weight updates. However, this comes at the cost of repeated expensive communication between the clients and the server, and concerns about compromised user privacy. The inversion of gradients into the data that generated them is termed data leakage. Encryption techniques can be used to counter this leakage, but at added expense. To address these challenges of communication efficiency and privacy, we propose TOFU, a novel algorithm which generates proxy data that encodes the weight updates for each client in its gradients. Instead of weight updates, this proxy data is now shared. Since input data is far lower in dimensional complexity than weights, this encoding allows us to send much lesser data per communication round. Additionally, the proxy data resembles noise, and even perfect reconstruction from data leakage attacks would invert the decoded gradients into unrecognizable noise, enhancing privacy. We show that TOFU enables learning with less than 1% and 7% accuracy drops on MNIST and on CIFAR-10 datasets, respectively. This drop can be recovered via a few rounds of expensive encrypted gradient exchange. This enables us to learn to near-full accuracy in a federated setup, while being 4x and 6.6x more communication efficient than the standard Federated Averaging algorithm on MNIST and CIFAR-10, respectively.