 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Transformers with Approximate Computing for Faster, Smaller and more Accurate NLP Models
Oct 07, 2020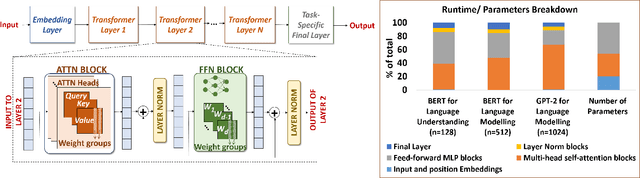
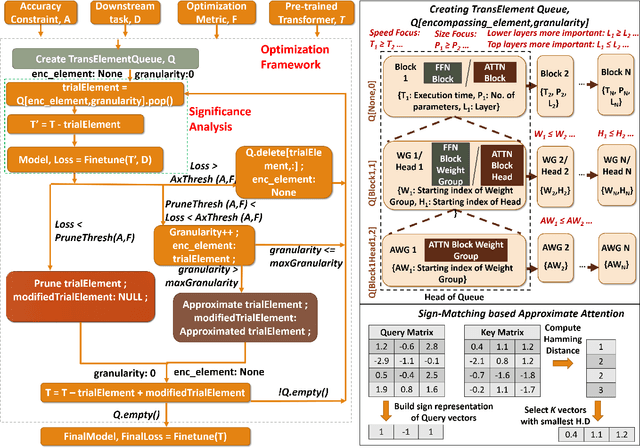

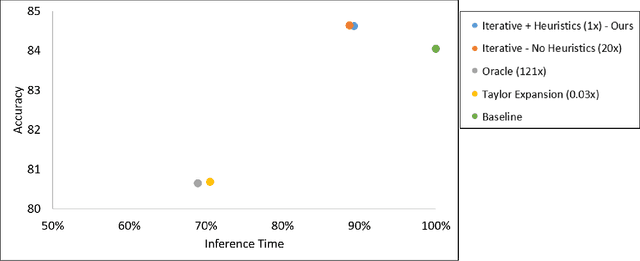
Transformer models have garnered a lot of interest in recent years by delivering state-of-the-art performance in a range of Natural Language Processing (NLP) tasks. However, these models can have over a hundred billion parameters, presenting very high computational and memory requirements. We address this challenge through Approximate Computing, specifically targeting the use of Transformers in NLP tasks. Transformers are typically pre-trained and subsequently specialized for specific tasks through transfer learning. Based on the observation that pre-trained Transformers are often over-parameterized for several downstream NLP tasks, we propose a framework to create smaller, faster and in some cases more accurate models. The key cornerstones of the framework are a Significance Analysis (SA) method that identifies components in a pre-trained Transformer that are less significant for a given task, and techniques to approximate the less significant components. Our approximations include pruning of blocks, attention heads and weight groups, quantization of less significant weights and a low-complexity sign-matching based attention mechanism. Our framework can be adapted to produce models that are faster, smaller and/or more accurate, depending on the user's constraints. We apply our framework to seven Transformer models, including optimized models like DistilBERT and Q8BERT, and three downstream tasks. We demonstrate that our framework produces models that are up to 4x faster and up to 14x smaller (with less than 0.5% relative accuracy degradation), or up to 5.5% more accurate with simultaneous improvements of up to 9.83x in model size or 2.94x in speed.
Adversarial Sparsity Attacks on Deep Neural Networks
Jun 18, 2020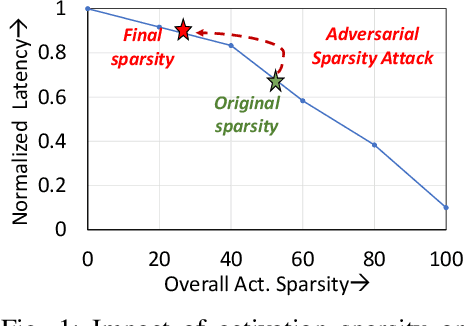

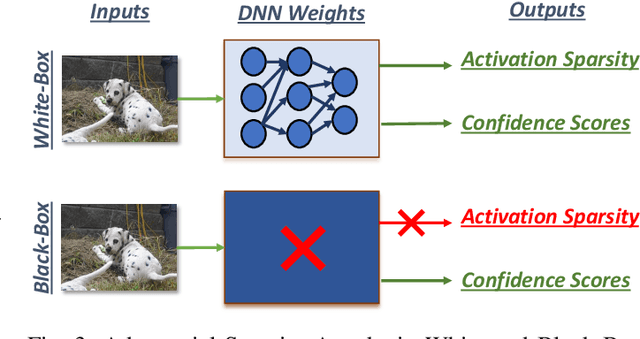
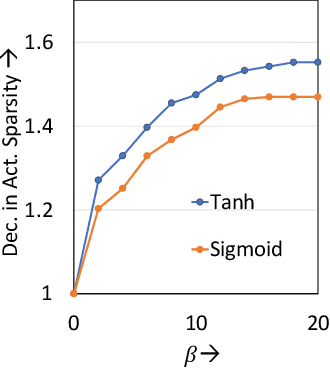
Adversarial attacks have exposed serious vulnerabilities in Deep Neural Networks (DNNs) through their ability to force misclassifications through human-imperceptible perturbations to DNN inputs. We explore a new direction in the field of adversarial attacks by suggesting attacks that aim to degrade the computational efficiency of DNNs rather than their classification accuracy. Specifically, we propose and demonstrate sparsity attacks, which adversarial modify a DNN's inputs so as to reduce sparsity (or the presence of zero values) in its internal activation values. In resource-constrained systems, a wide range of hardware and software techniques have been proposed that exploit sparsity to improve DNN efficiency. The proposed attack increases the execution time and energy consumption of sparsity-optimized DNN implementations, raising concern over their deployment in latency and energy-critical applications. We propose a systematic methodology to generate adversarial inputs for sparsity attacks by formulating an objective function that quantifies the network's activation sparsity, and minimizing this function using iterative gradient-descent techniques. We launch both white-box and black-box versions of adversarial sparsity attacks on image recognition DNNs and demonstrate that they decrease activation sparsity by up to 1.82x. We also evaluate the impact of the attack on a sparsity-optimized DNN accelerator and demonstrate degradations up to 1.59x in latency, and also study the performance of the attack on a sparsity-optimized general-purpose processor. Finally, we evaluate defense techniques such as activation thresholding and input quantization and demonstrate that the proposed attack is able to withstand them, highlighting the need for further efforts in this new direction within the field of adversarial machine learning.
EMPIR: Ensembles of Mixed Precision Deep Networks for Increased Robustness against Adversarial Attacks
Apr 21, 2020

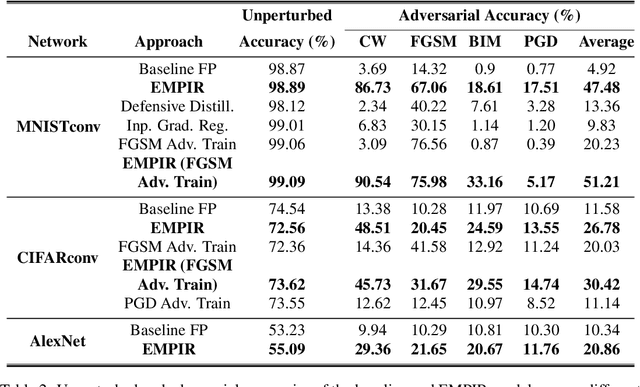
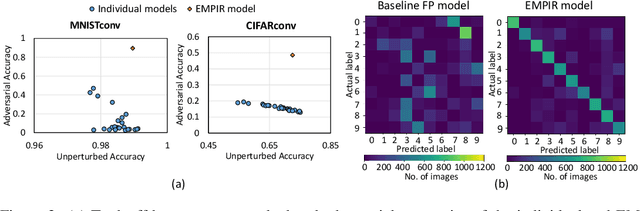
Ensuring robustness of Deep Neural Networks (DNNs) is crucial to their adoption in safety-critical applications such as self-driving cars, drones, and healthcare. Notably, DNNs are vulnerable to adversarial attacks in which small input perturbations can produce catastrophic misclassifications. In this work, we propose EMPIR, ensembles of quantized DNN models with different numerical precisions, as a new approach to increase robustness against adversarial attacks. EMPIR is based on the observation that quantized neural networks often demonstrate much higher robustness to adversarial attacks than full precision networks, but at the cost of a substantial loss in accuracy on the original (unperturbed) inputs. EMPIR overcomes this limitation to achieve the 'best of both worlds', i.e., the higher unperturbed accuracies of the full precision models combined with the higher robustness of the low precision models, by composing them in an ensemble. Further, as low precision DNN models have significantly lower computational and storage requirements than full precision models, EMPIR models only incur modest compute and memory overheads compared to a single full-precision model (<25% in our evaluations). We evaluate EMPIR across a suite of DNNs for 3 different image recognition tasks (MNIST, CIFAR-10 and ImageNet) and under 4 different adversarial attacks. Our results indicate that EMPIR boosts the average adversarial accuracies by 42.6%, 15.2% and 10.5% for the DNN models trained on the MNIST, CIFAR-10 and ImageNet datasets respectively, when compared to single full-precision models, without sacrificing accuracy on the unperturbed inputs.
SparCE: Sparsity aware General Purpose Core Extensions to Accelerate Deep Neural Networks
Nov 29, 2017



Deep Neural Networks (DNNs) have emerged as the method of choice for solving a wide range of machine learning tasks. The enormous computational demands posed by DNNs have most commonly been addressed through the design of custom accelerators. However, these accelerators are prohibitive in many design scenarios (e.g., wearable devices and IoT sensors), due to stringent area/cost constraints. Accelerating DNNs on these low-power systems, comprising of mainly the general-purpose processor (GPP) cores, requires new approaches. We improve the performance of DNNs on GPPs by exploiting a key attribute of DNNs, i.e., sparsity. We propose Sparsity aware Core Extensions (SparCE)- a set of micro-architectural and ISA extensions that leverage sparsity and are minimally intrusive and low-overhead. We dynamically detect zero operands and skip a set of future instructions that use it. Our design ensures that the instructions to be skipped are prevented from even being fetched, as squashing instructions comes with a penalty. SparCE consists of 2 key micro-architectural enhancements- a Sparsity Register File (SpRF) that tracks zero registers and a Sparsity aware Skip Address (SASA) table that indicates instructions to be skipped. When an instruction is fetched, SparCE dynamically pre-identifies whether the following instruction(s) can be skipped and appropriately modifies the program counter, thereby skipping the redundant instructions and improving performance. We model SparCE using the gem5 architectural simulator, and evaluate our approach on 6 image-recognition DNNs in the context of both training and inference using the Caffe framework. On a scalar microprocessor, SparCE achieves 19%-31% reduction in application-level. We also evaluate SparCE on a 4-way SIMD ARMv8 processor using the OpenBLAS library, and demonstrate that SparCE achieves 8%-15% reduction in the application-level execution time.