 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory Is All You Need: An Overview of Compute-in-Memory Architectures for Accelerating Large Language Model Inference
Jun 12, 2024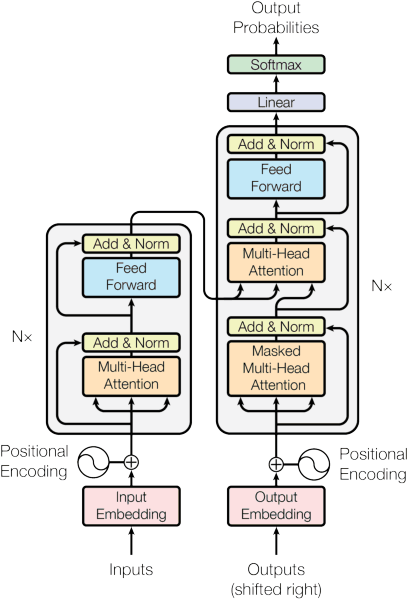
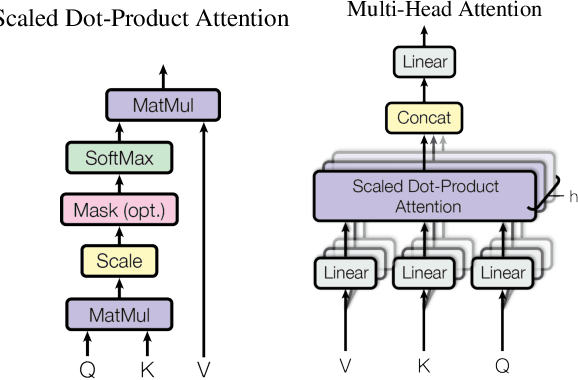
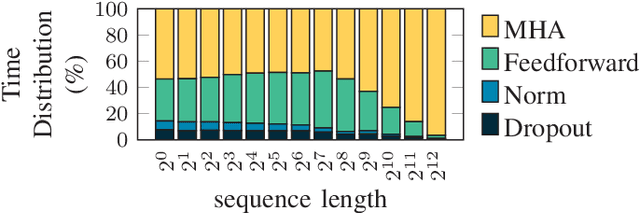
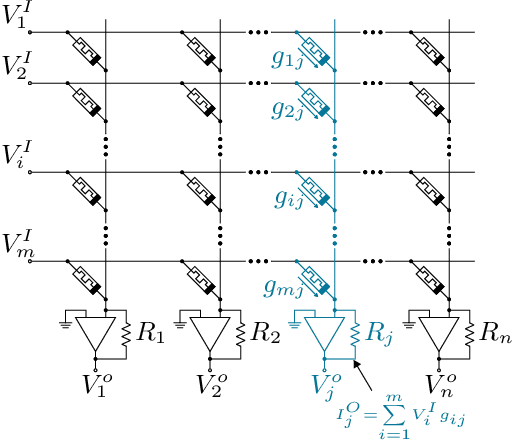
Large language models (LLMs) have recently transformed natural language processing, enabling machines to generate human-like text and engage in meaningful conversations. This development necessitates speed, efficiency, and accessibility in LLM inference as the computational and memory requirements of these systems grow exponentially. Meanwhile, advancements in computing and memory capabilities are lagging behind, exacerbated by the discontinuation of Moore's law. With LLMs exceeding the capacity of single GPUs, they require complex, expert-level configurations for parallel processing. Memory accesses become significantly more expensive than computation, posing a challenge for efficient scaling, known as the memory wall. Here, compute-in-memory (CIM) technologies offer a promising solution for accelerating AI inference by directly performing analog computations in memory, potentially reducing latency and power consumption. By closely integrating memory and compute elements, CIM eliminates the von Neumann bottleneck, reducing data movement and improving energy efficiency. This survey paper provides an overview and analysis of transformer-based models, reviewing various CIM architectures and exploring how they can address the imminent challenges of modern AI computing systems. We discuss transformer-related operators and their hardware acceleration schemes and highlight challenges, trends, and insights in corresponding CIM designs.
Biologically Plausible Learning on Neuromorphic Hardware Architectures
Dec 29, 2022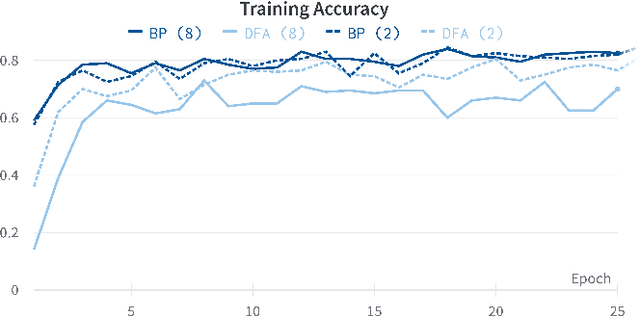
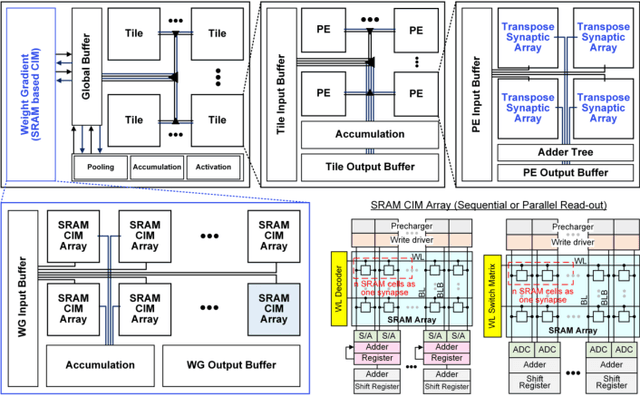
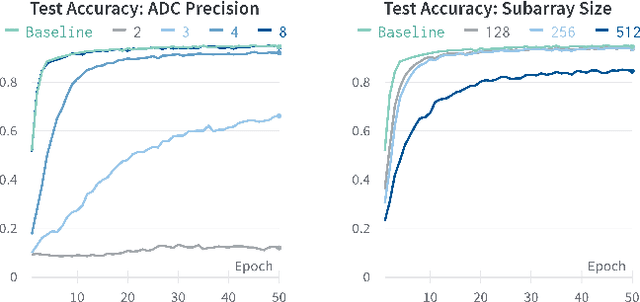
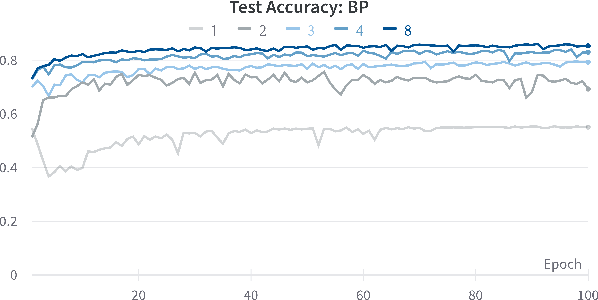
With an ever-growing number of parameters defining increasingly complex networks, Deep Learning has led to several breakthroughs surpassing human performance. As a result, data movement for these millions of model parameters causes a growing imbalance known as the memory wall. Neuromorphic computing is an emerging paradigm that confronts this imbalance by performing computations directly in analog memories. On the software side, the sequential Backpropagation algorithm prevents efficient parallelization and thus fast convergence. A novel method, Direct Feedback Alignment, resolves inherent layer dependencies by directly passing the error from the output to each layer. At the intersection of hardware/software co-design, there is a demand for developing algorithms that are tolerable to hardware nonidealities. Therefore, this work explores the interrelationship of implementing bio-plausible learning in-situ on neuromorphic hardware, emphasizing energy, area, and latency constraints. Using the benchmarking framework DNN+NeuroSim, we investigate the impact of hardware nonidealities and quantization on algorithm performance, as well as how network topologies and algorithm-level design choices can scale latency, energy and area consumption of a chip. To the best of our knowledge, this work is the first to compare the impact of different learning algorithms on Compute-In-Memory-based hardware and vice versa. The best results achieved for accuracy remain Backpropagation-based, notably when facing hardware imperfections. Direct Feedback Alignment, on the other hand, allows for significant speedup due to parallelization, reducing training time by a factor approaching N for N-layered networks.
Approximate Computing and the Efficient Machine Learning Expedition
Oct 02, 2022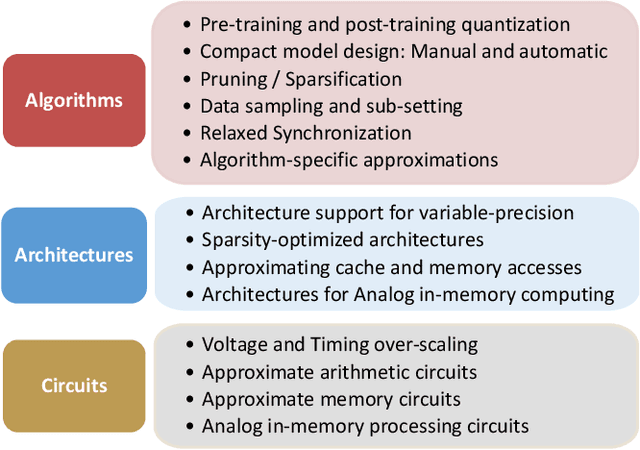
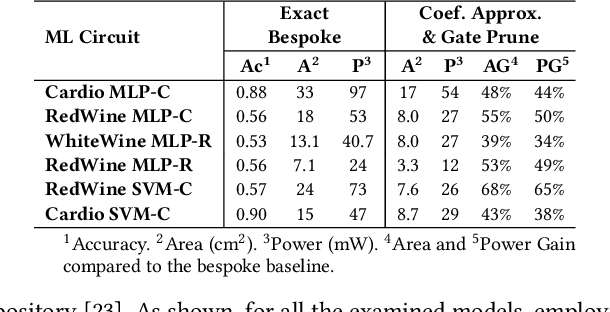
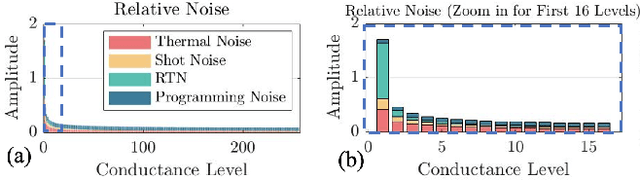
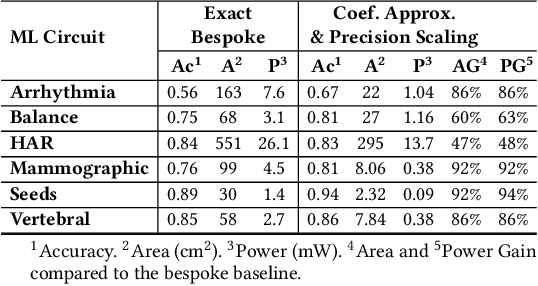
Approximate computing (AxC) has been long accepted as a design alternative for efficient system implementation at the cost of relaxed accuracy requirements. Despite the AxC research activities in various application domains, AxC thrived the past decade when it was applied in Machine Learning (ML). The by definition approximate notion of ML models but also the increased computational overheads associated with ML applications-that were effectively mitigated by corresponding approximations-led to a perfect matching and a fruitful synergy. AxC for AI/ML has transcended beyond academic prototypes. In this work, we enlighten the synergistic nature of AxC and ML and elucidate the impact of AxC in designing efficient ML systems. To that end, we present an overview and taxonomy of AxC for ML and use two descriptive application scenarios to demonstrate how AxC boosts the efficiency of ML systems.
HERO: Hessian-Enhanced Robust Optimization for Unifying and Improving Generalization and Quantization Performance
Nov 23, 2021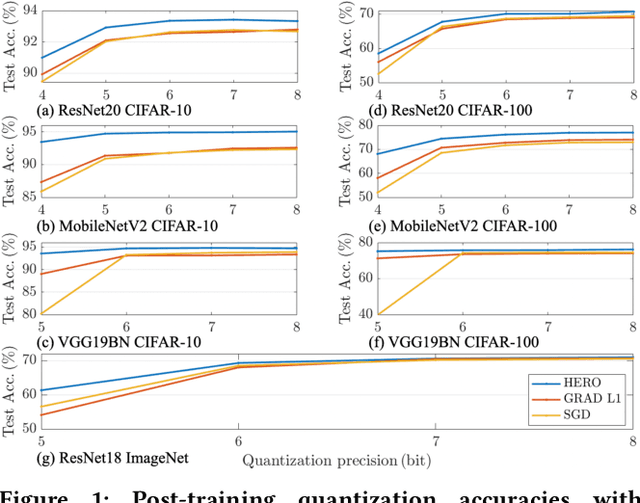
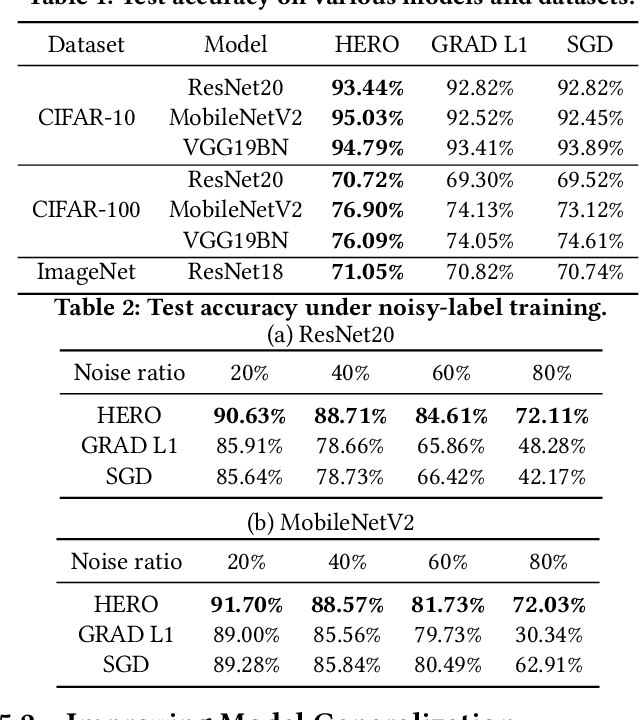
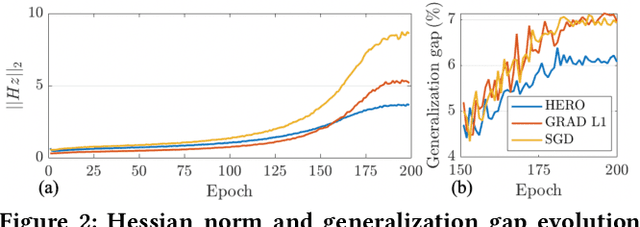
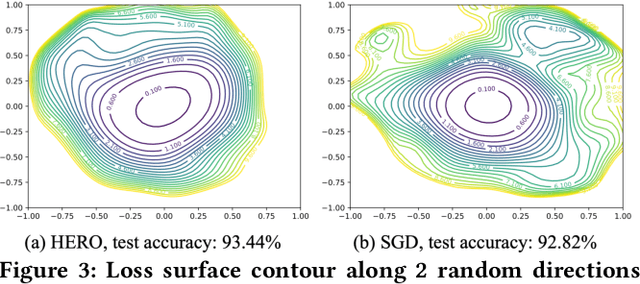
With the recent demand of deploying neural network models on mobile and edge devices, it is desired to improve the model's generalizability on unseen testing data, as well as enhance the model's robustness under fixed-point quantization for efficient deployment. Minimizing the training loss, however, provides few guarantees on the generalization and quantization performance. In this work, we fulfill the need of improving generalization and quantization performance simultaneously by theoretically unifying them under the framework of improving the model's robustness against bounded weight perturbation and minimizing the eigenvalues of the Hessian matrix with respect to model weights. We therefore propose HERO, a Hessian-enhanced robust optimization method, to minimize the Hessian eigenvalues through a gradient-based training process, simultaneously improving the generalization and quantization performance. HERO enables up to a 3.8% gain on test accuracy, up to 30% higher accuracy under 80% training label perturbation, and the best post-training quantization accuracy across a wide range of precision, including a >10% accuracy improvement over SGD-trained models for common model architectures on various datasets.