 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIMAC: In-memory multi-bit Multiplication andACcumulation in 6T SRAM Array
Paper and Code
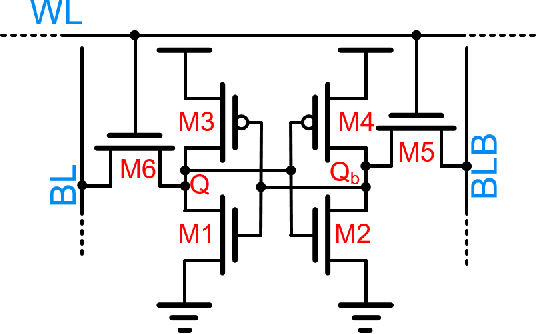
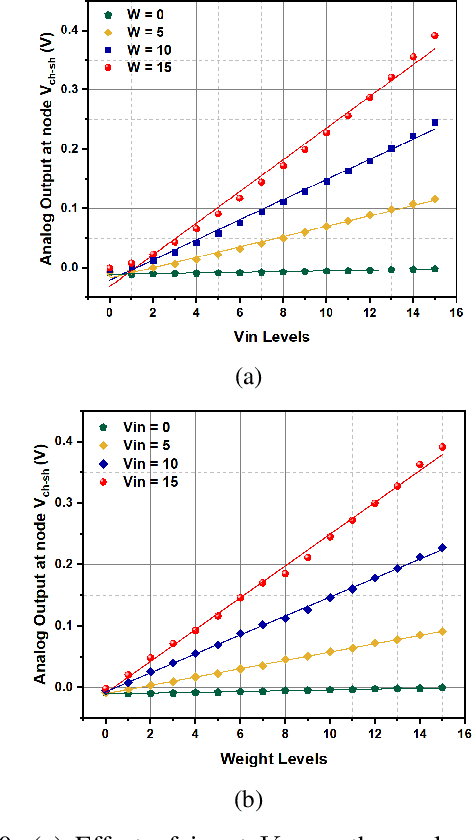

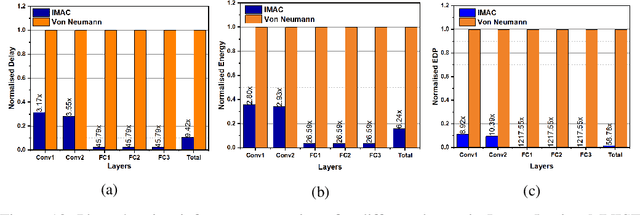
`In-memory computing' is being widely explored as a novel computing paradigm to mitigate the well known memory bottleneck. This emerging paradigm aims at embedding some aspects of computations inside the memory array, thereby avoiding frequent and expensive movement of data between the compute unit and the storage memory. In-memory computing with respect to Silicon memories has been widely explored on various memory bit-cells. Embedding computation inside the 6 transistor (6T) SRAM array is of special interest since it is the most widely used on-chip memory. In this paper, we present a novel in-memory multiplication followed by accumulation operation capable of performing parallel dot products within 6T SRAM without any changes to the standard bitcell. We, further, study the effect of circuit non-idealities and process variations on the accuracy of the LeNet-5 and VGG neural network architectures against the MNIST and CIFAR-10 datasets, respectively. The proposed in-memory dot-product mechanism achieves 88.8% and 99% accuracy for the CIFAR-10 and MNIST, respectively. Compared to the standard von Neumann system, the proposed system is 6.24x better in energy consumption and 9.42x better in delay.