 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Dense to Dynamic: Token-Difficulty Driven MoEfication of Pre-Trained LLMs
Feb 17, 2025Training large language models (LLMs) for different inference constraints is computationally expensive, limiting control over efficiency-accuracy trade-offs. Moreover, once trained, these models typically process tokens uniformly, regardless of their complexity, leading to static and inflexible behavior. In this paper, we introduce a post-training optimization framework, DynaMoE, that adapts a pre-trained dense LLM to a token-difficulty-driven Mixture-of-Experts model with minimal fine-tuning cost. This adaptation makes the model dynamic, with sensitivity control to customize the balance between efficiency and accuracy. DynaMoE features a token-difficulty-aware router that predicts the difficulty of tokens and directs them to the appropriate sub-networks or experts, enabling larger experts to handle more complex tokens and smaller experts to process simpler ones. Our experiments demonstrate that DynaMoE can generate a range of adaptive model variants of the existing trained LLM with a single fine-tuning step, utilizing only $10B$ tokens, a minimal cost compared to the base model's training. Each variant offers distinct trade-offs between accuracy and performance. Compared to the baseline post-training optimization framework, Flextron, our method achieves similar aggregated accuracy across downstream tasks, despite using only $\frac{1}{9}\text{th}$ of their fine-tuning cost.
Parameters vs FLOPs: Scaling Laws for Optimal Sparsity for Mixture-of-Experts Language Models
Jan 21, 2025Scaling the capacity of language models has consistently proven to be a reliable approach for improving performance and unlocking new capabilities. Capacity can be primarily defined by two dimensions: the number of model parameters and the compute per example. While scaling typically involves increasing both, the precise interplay between these factors and their combined contribution to overall capacity remains not fully understood. We explore this relationship in the context of sparse Mixture-of-Expert models (MoEs), which allow scaling the number of parameters without proportionally increasing the FLOPs per example. We investigate how varying the sparsity level, i.e., the ratio of non-active to total parameters, affects model performance in terms of both pretraining and downstream performance. We find that under different constraints (e.g. parameter size and total training compute), there is an optimal level of sparsity that improves both training efficiency and model performance. These results provide a better understanding of the impact of sparsity in scaling laws for MoEs and complement existing works in this area, offering insights for designing more efficient architectures.
Aggregate-and-Adapt Natural Language Prompts for Downstream Generalization of CLIP
Oct 31, 2024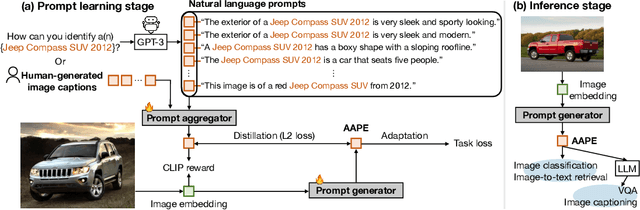
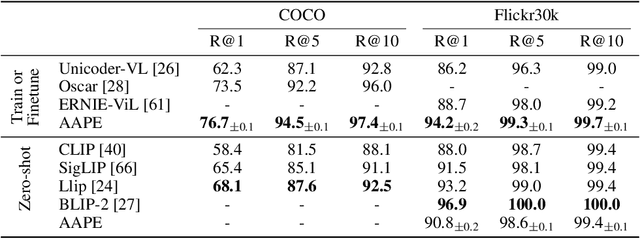

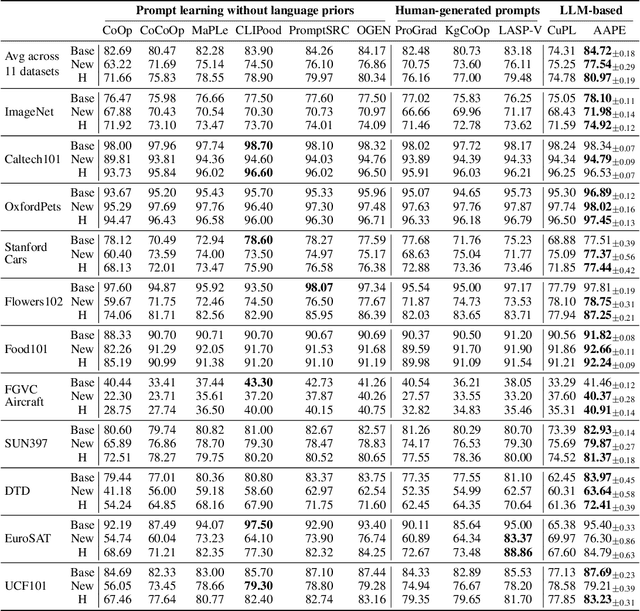
Large pretrained vision-language models like CLIP have shown promising generalization capability, but may struggle in specialized domains (e.g., satellite imagery) or fine-grained classification (e.g., car models) where the visual concepts are unseen or under-represented during pretraining. Prompt learning offers a parameter-efficient finetuning framework that can adapt CLIP to downstream tasks even when limited annotation data are available. In this paper, we improve prompt learning by distilling the textual knowledge from natural language prompts (either human- or LLM-generated) to provide rich priors for those under-represented concepts. We first obtain a prompt ``summary'' aligned to each input image via a learned prompt aggregator. Then we jointly train a prompt generator, optimized to produce a prompt embedding that stays close to the aggregated summary while minimizing task loss at the same time. We dub such prompt embedding as Aggregate-and-Adapted Prompt Embedding (AAPE). AAPE is shown to be able to generalize to different downstream data distributions and tasks, including vision-language understanding tasks (e.g., few-shot classification, VQA) and generation tasks (image captioning) where AAPE achieves competitive performance. We also show AAPE is particularly helpful to handle non-canonical and OOD examples. Furthermore, AAPE learning eliminates LLM-based inference cost as required by baselines, and scales better with data and LLM model size.
Adaptivity and Modularity for Efficient Generalization Over Task Complexity
Oct 13, 2023



Can transformers generalize efficiently on problems that require dealing with examples with different levels of difficulty? We introduce a new task tailored to assess generalization over different complexities and present results that indicate that standard transformers face challenges in solving these tasks. These tasks are variations of pointer value retrieval previously introduced by Zhang et al. (2021). We investigate how the use of a mechanism for adaptive and modular computation in transformers facilitates the learning of tasks that demand generalization over the number of sequential computation steps (i.e., the depth of the computation graph). Based on our observations, we propose a transformer-based architecture called Hyper-UT, which combines dynamic function generation from hyper networks with adaptive depth from Universal Transformers. This model demonstrates higher accuracy and a fairer allocation of computational resources when generalizing to higher numbers of computation steps. We conclude that mechanisms for adaptive depth and modularity complement each other in improving efficient generalization concerning example complexity. Additionally, to emphasize the broad applicability of our findings, we illustrate that in a standard image recognition task, Hyper- UT's performance matches that of a ViT model but with considerably reduced computational demands (achieving over 70\% average savings by effectively using fewer layers).
Diffusion Probabilistic Fields
Mar 01, 2023



Diffusion probabilistic models have quickly become a major approach for generative modeling of images, 3D geometry, video and other domains. However, to adapt diffusion generative modeling to these domains the denoising network needs to be carefully designed for each domain independently, oftentimes under the assumption that data lives in a Euclidean grid. In this paper we introduce Diffusion Probabilistic Fields (DPF), a diffusion model that can learn distributions over continuous functions defined over metric spaces, commonly known as fields. We extend the formulation of diffusion probabilistic models to deal with this field parametrization in an explicit way, enabling us to define an end-to-end learning algorithm that side-steps the requirement of representing fields with latent vectors as in previous approaches (Dupont et al., 2022a; Du et al., 2021). We empirically show that, while using the same denoising network, DPF effectively deals with different modalities like 2D images and 3D geometry, in addition to modeling distributions over fields defined on non-Euclidean metric spaces.
GAUDI: A Neural Architect for Immersive 3D Scene Generation
Jul 27, 2022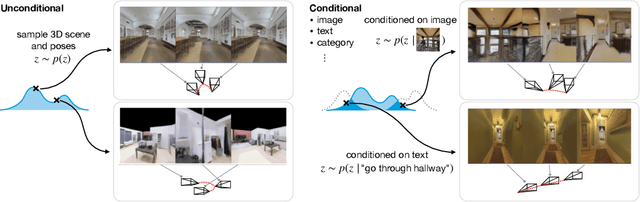
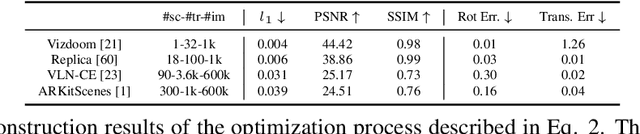
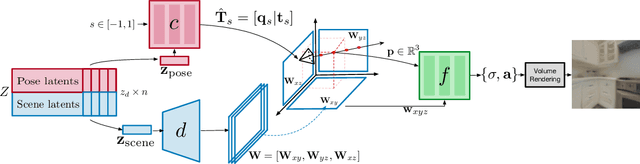

We introduce GAUDI, a generative model capable of capturing the distribution of complex and realistic 3D scenes that can be rendered immersively from a moving camera. We tackle this challenging problem with a scalable yet powerful approach, where we first optimize a latent representation that disentangles radiance fields and camera poses. This latent representation is then used to learn a generative model that enables both unconditional and conditional generation of 3D scenes. Our model generalizes previous works that focus on single objects by removing the assumption that the camera pose distribution can be shared across samples. We show that GAUDI obtains state-of-the-art performance in the unconditional generative setting across multiple datasets and allows for conditional generation of 3D scenes given conditioning variables like sparse image observations or text that describes the scene.
Scaling Laws vs Model Architectures: How does Inductive Bias Influence Scaling?
Jul 21, 2022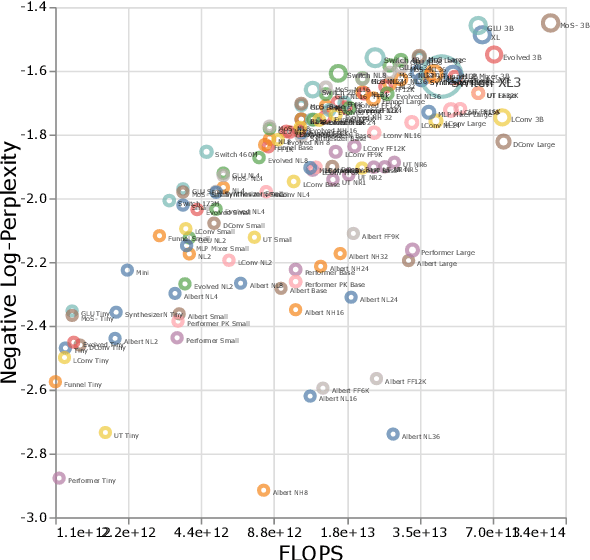
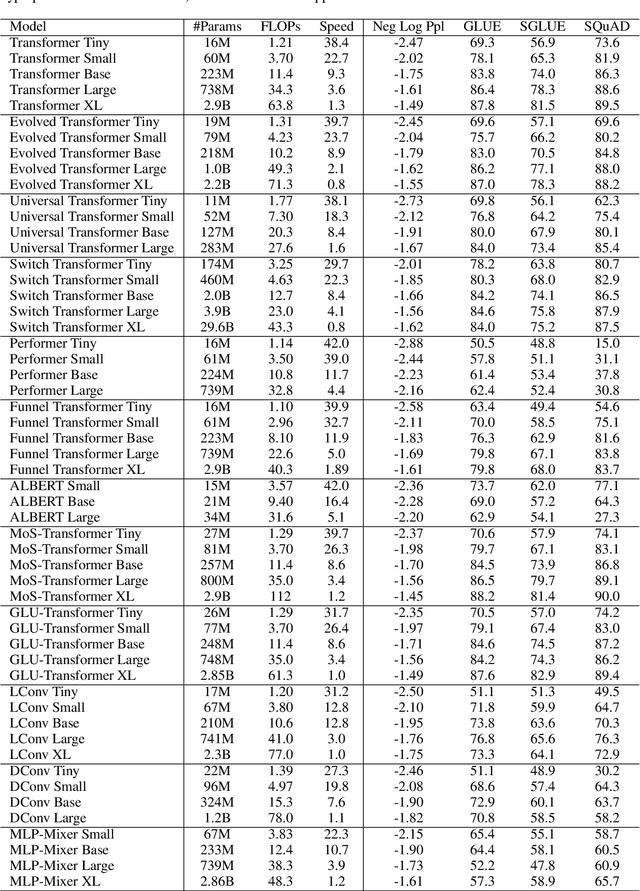
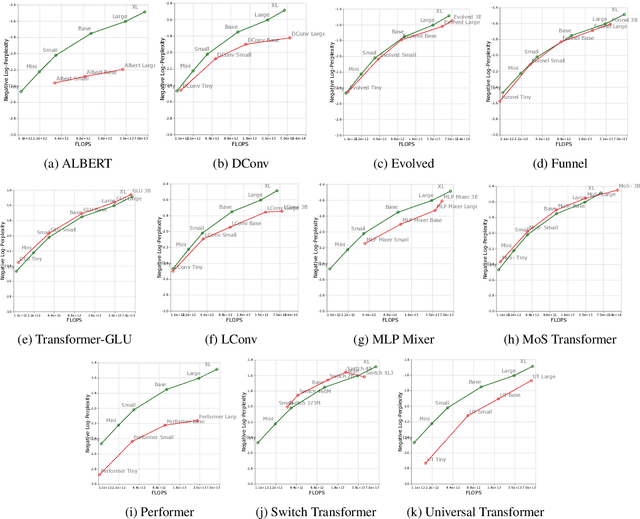
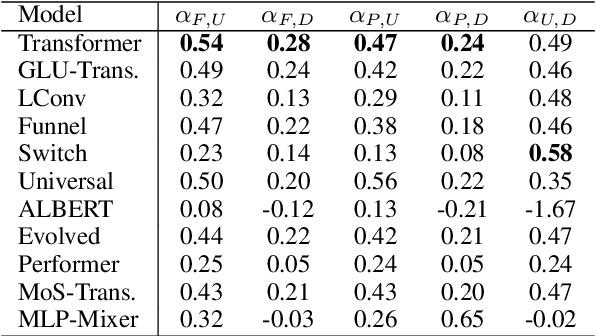
There have been a lot of interest in the scaling properties of Transformer models. However, not much has been done on the front of investigating the effect of scaling properties of different inductive biases and model architectures. Do model architectures scale differently? If so, how does inductive bias affect scaling behaviour? How does this influence upstream (pretraining) and downstream (transfer)? This paper conducts a systematic study of scaling behaviour of ten diverse model architectures such as Transformers, Switch Transformers, Universal Transformers, Dynamic convolutions, Performers, and recently proposed MLP-Mixers. Via extensive experiments, we show that (1) architecture is an indeed an important consideration when performing scaling and (2) the best performing model can fluctuate at different scales. We believe that the findings outlined in this work has significant implications to how model architectures are currently evaluated in the community.
Exploring the Limits of Large Scale Pre-training
Oct 05, 2021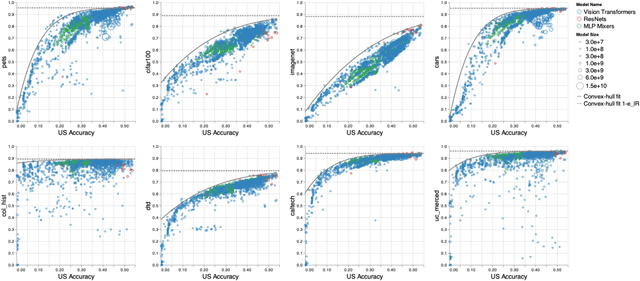
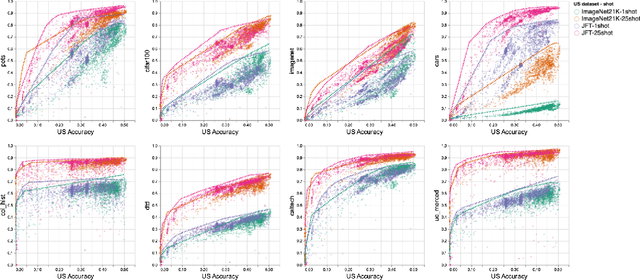
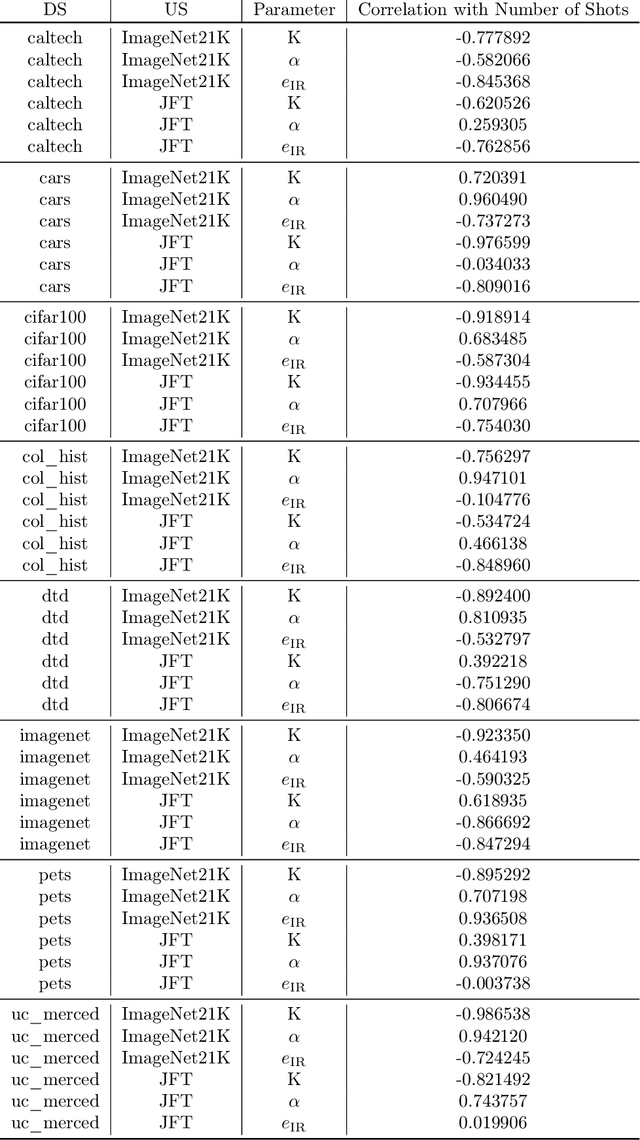
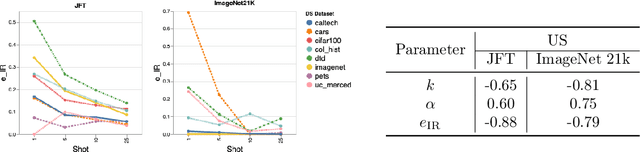
Recent developments in large-scale machine learning suggest that by scaling up data, model size and training time properly, one might observe that improvements in pre-training would transfer favorably to most downstream tasks. In this work, we systematically study this phenomena and establish that, as we increase the upstream accuracy, the performance of downstream tasks saturates. In particular, we investigate more than 4800 experiments on Vision Transformers, MLP-Mixers and ResNets with number of parameters ranging from ten million to ten billion, trained on the largest scale of available image data (JFT, ImageNet21K) and evaluated on more than 20 downstream image recognition tasks. We propose a model for downstream performance that reflects the saturation phenomena and captures the nonlinear relationship in performance of upstream and downstream tasks. Delving deeper to understand the reasons that give rise to these phenomena, we show that the saturation behavior we observe is closely related to the way that representations evolve through the layers of the models. We showcase an even more extreme scenario where performance on upstream and downstream are at odds with each other. That is, to have a better downstream performance, we need to hurt upstream accuracy.
Scale Efficiently: Insights from Pre-training and Fine-tuning Transformers
Sep 22, 2021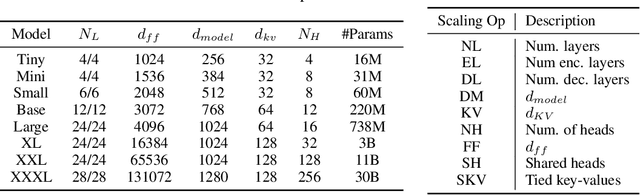
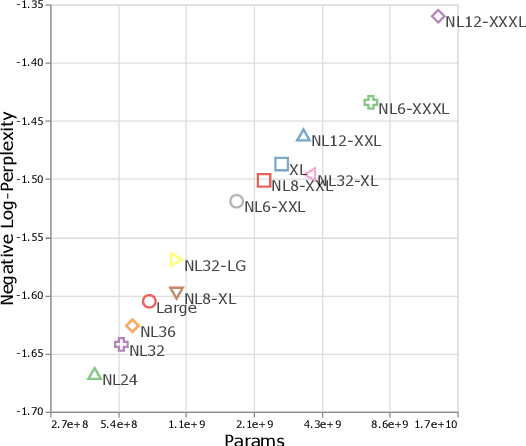
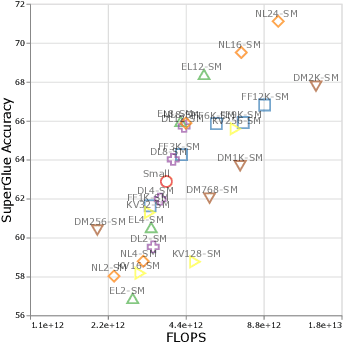
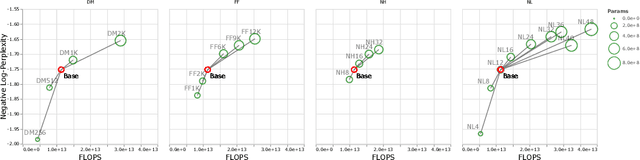
There remain many open questions pertaining to the scaling behaviour of Transformer architectures. These scaling decisions and findings can be critical, as training runs often come with an associated computational cost which have both financial and/or environmental impact. The goal of this paper is to present scaling insights from pretraining and finetuning Transformers. While Kaplan et al. presents a comprehensive study of the scaling behaviour of Transformer language models, the scope is only on the upstream (pretraining) loss. Therefore, it is still unclear if these set of findings transfer to downstream task within the context of the pretrain-finetune paradigm. The key findings of this paper are as follows: (1) we show that aside from only the model size, model shape matters for downstream fine-tuning, (2) scaling protocols operate differently at different compute regions, (3) widely adopted T5-base and T5-large sizes are Pareto-inefficient. To this end, we present improved scaling protocols whereby our redesigned models achieve similar downstream fine-tuning quality while having 50\% fewer parameters and training 40\% faster compared to the widely adopted T5-base model. We publicly release over 100 pretrained checkpoints of different T5 configurations to facilitate future research and analysis.
Gradual Domain Adaptation in the Wild:When Intermediate Distributions are Absent
Jun 10, 2021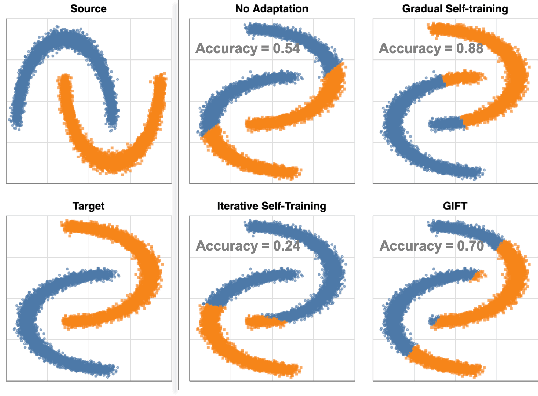
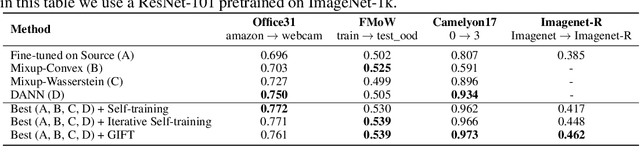

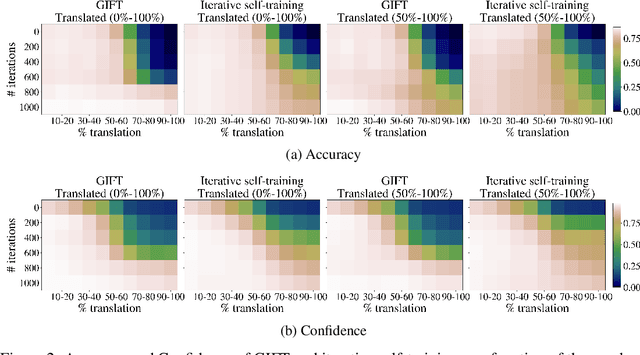
We focus on the problem of domain adaptation when the goal is shifting the model towards the target distribution, rather than learning domain invariant representations. It has been shown that under the following two assumptions: (a) access to samples from intermediate distributions, and (b) samples being annotated with the amount of change from the source distribution, self-training can be successfully applied on gradually shifted samples to adapt the model toward the target distribution. We hypothesize having (a) is enough to enable iterative self-training to slowly adapt the model to the target distribution, by making use of an implicit curriculum. In the case where (a) does not hold, we observe that iterative self-training falls short. We propose GIFT, a method that creates virtual samples from intermediate distributions by interpolating representations of examples from source and target domains. We evaluate an iterative-self-training method on datasets with natural distribution shifts, and show that when applied on top of other domain adaptation methods, it improves the performance of the model on the target dataset. We run an analysis on a synthetic dataset to show that in the presence of (a) iterative-self-training naturally forms a curriculum of samples. Furthermore, we show that when (a) does not hold, GIFT performs better than iterative self-training.