 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnnotations Mitigate Post-Training Mode Collapse
May 11, 2026Post-training (via supervised fine-tuning) improves instruction-following, but often induces semantic mode collapse by biasing models toward low-entropy fine-tuning data at the expense of the high-entropy pretraining distribution. Crucially, we find this trade-off worsens with scale. To close this semantic diversity gap, we propose annotation-anchored training, a principled method that enables models to adopt the preference-following behaviors of post-training without sacrificing the inherent diversity of pretraining. Our approach is simple: we pretrain on documents paired with semantic annotations, inducing a rich annotation distribution that reflects the full breadth of pretraining data, and we preserve this distribution during post-training. This lets us sample diverse annotations at inference time and use them as anchors to guide generation, effectively transferring pretraining's semantic richness into post-trained models. We find that models trained with annotation-anchored training can attain $6 \times$ less diversity collapse than models trained with SFT, and improve with scale.
Text-Conditional JEPA for Learning Semantically Rich Visual Representations
May 05, 2026Image-based Joint-Embedding Predictive Architecture (I-JEPA) offers a promising approach to visual self-supervised learning through masked feature prediction. However with the inherent visual uncertainty at masked positions, feature prediction remains challenging and may fail to learn semantic representations. In this work, we propose Text-Conditional JEPA (TC-JEPA) that uses image captions to reduce the prediction uncertainty. Specifically, we modulate the predicted patch features using a fine-grained text conditioner that computes sparse cross-attention over input text tokens. With such conditioning, patch features become predictable as a function of text, thus are more semantically meaningful. We show TC-JEPA improves downstream performance and training stability, with promising scaling properties. TC-JEPA also offers a new vision-language pretraining paradigm based on feature prediction only, outperforming contrastive methods on diverse tasks, especially those requiring fine-grained visual understanding and reasoning.
Distillation Scaling Laws
Feb 12, 2025We provide a distillation scaling law that estimates distilled model performance based on a compute budget and its allocation between the student and teacher. Our findings reduce the risks associated with using distillation at scale; compute allocation for both the teacher and student models can now be done to maximize student performance. We provide compute optimal distillation recipes for when 1) a teacher exists, or 2) a teacher needs training. If many students are to be distilled, or a teacher already exists, distillation outperforms supervised pretraining until a compute level which grows predictably with student size. If one student is to be distilled and a teacher also needs training, supervised learning should be done instead. Additionally, we provide insights across our large scale study of distillation, which increase our understanding of distillation and inform experimental design.
Enhancing JEPAs with Spatial Conditioning: Robust and Efficient Representation Learning
Oct 14, 2024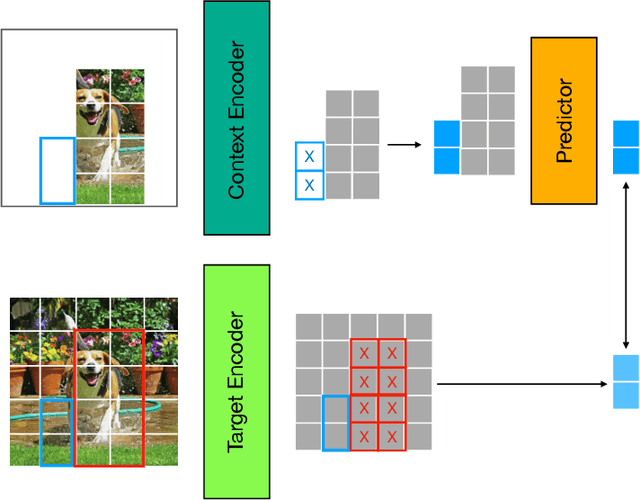
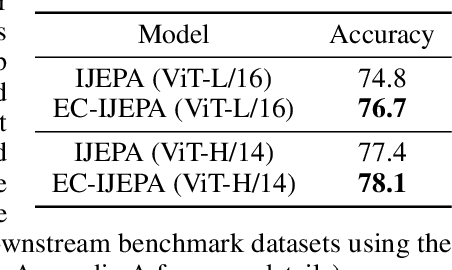
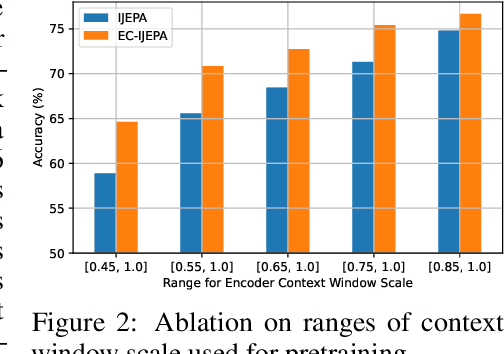
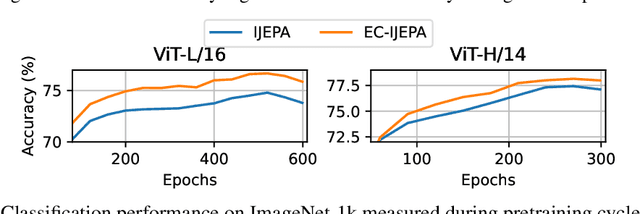
Image-based Joint-Embedding Predictive Architecture (IJEPA) offers an attractive alternative to Masked Autoencoder (MAE) for representation learning using the Masked Image Modeling framework. IJEPA drives representations to capture useful semantic information by predicting in latent rather than input space. However, IJEPA relies on carefully designed context and target windows to avoid representational collapse. The encoder modules in IJEPA cannot adaptively modulate the type of predicted and/or target features based on the feasibility of the masked prediction task as they are not given sufficient information of both context and targets. Based on the intuition that in natural images, information has a strong spatial bias with spatially local regions being highly predictive of one another compared to distant ones. We condition the target encoder and context encoder modules in IJEPA with positions of context and target windows respectively. Our "conditional" encoders show performance gains on several image classification benchmark datasets, improved robustness to context window size and sample-efficiency during pretraining.
UI-JEPA: Towards Active Perception of User Intent through Onscreen User Activity
Sep 06, 2024
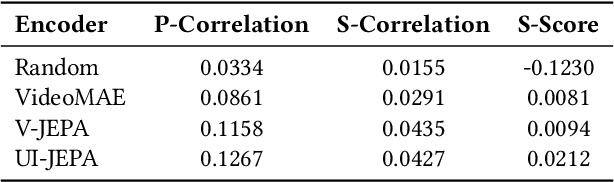


Generating user intent from a sequence of user interface (UI) actions is a core challenge in comprehensive UI understanding. Recent advancements in multimodal large language models (MLLMs) have led to substantial progress in this area, but their demands for extensive model parameters, computing power, and high latency makes them impractical for scenarios requiring lightweight, on-device solutions with low latency or heightened privacy. Additionally, the lack of high-quality datasets has hindered the development of such lightweight models. To address these challenges, we propose UI-JEPA, a novel framework that employs masking strategies to learn abstract UI embeddings from unlabeled data through self-supervised learning, combined with an LLM decoder fine-tuned for user intent prediction. We also introduce two new UI-grounded multimodal datasets, "Intent in the Wild" (IIW) and "Intent in the Tame" (IIT), designed for few-shot and zero-shot UI understanding tasks. IIW consists of 1.7K videos across 219 intent categories, while IIT contains 914 videos across 10 categories. We establish the first baselines for these datasets, showing that representations learned using a JEPA-style objective, combined with an LLM decoder, can achieve user intent predictions that match the performance of state-of-the-art large MLLMs, but with significantly reduced annotation and deployment resources. Measured by intent similarity scores, UI-JEPA outperforms GPT-4 Turbo and Claude 3.5 Sonnet by 10.0% and 7.2% respectively, averaged across two datasets. Notably, UI-JEPA accomplishes the performance with a 50.5x reduction in computational cost and a 6.6x improvement in latency in the IIW dataset. These results underscore the effectiveness of UI-JEPA, highlighting its potential for lightweight, high-performance UI understanding.
How JEPA Avoids Noisy Features: The Implicit Bias of Deep Linear Self Distillation Networks
Jul 03, 2024



Two competing paradigms exist for self-supervised learning of data representations. Joint Embedding Predictive Architecture (JEPA) is a class of architectures in which semantically similar inputs are encoded into representations that are predictive of each other. A recent successful approach that falls under the JEPA framework is self-distillation, where an online encoder is trained to predict the output of the target encoder, sometimes using a lightweight predictor network. This is contrasted with the Masked AutoEncoder (MAE) paradigm, where an encoder and decoder are trained to reconstruct missing parts of the input in the data space rather, than its latent representation. A common motivation for using the JEPA approach over MAE is that the JEPA objective prioritizes abstract features over fine-grained pixel information (which can be unpredictable and uninformative). In this work, we seek to understand the mechanism behind this empirical observation by analyzing the training dynamics of deep linear models. We uncover a surprising mechanism: in a simplified linear setting where both approaches learn similar representations, JEPAs are biased to learn high-influence features, i.e., features characterized by having high regression coefficients. Our results point to a distinct implicit bias of predicting in latent space that may shed light on its success in practice.
LiDAR: Sensing Linear Probing Performance in Joint Embedding SSL Architectures
Dec 07, 2023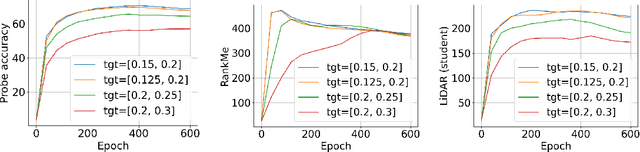
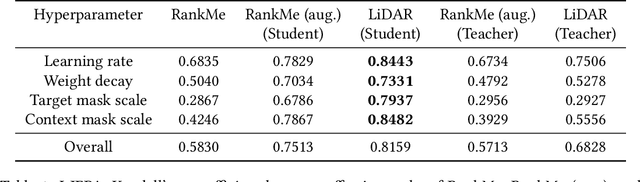

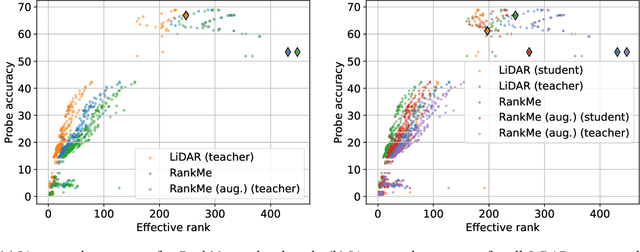
Joint embedding (JE) architectures have emerged as a promising avenue for acquiring transferable data representations. A key obstacle to using JE methods, however, is the inherent challenge of evaluating learned representations without access to a downstream task, and an annotated dataset. Without efficient and reliable evaluation, it is difficult to iterate on architectural and training choices for JE methods. In this paper, we introduce LiDAR (Linear Discriminant Analysis Rank), a metric designed to measure the quality of representations within JE architectures. Our metric addresses several shortcomings of recent approaches based on feature covariance rank by discriminating between informative and uninformative features. In essence, LiDAR quantifies the rank of the Linear Discriminant Analysis (LDA) matrix associated with the surrogate SSL task -- a measure that intuitively captures the information content as it pertains to solving the SSL task. We empirically demonstrate that LiDAR significantly surpasses naive rank based approaches in its predictive power of optimal hyperparameters. Our proposed criterion presents a more robust and intuitive means of assessing the quality of representations within JE architectures, which we hope facilitates broader adoption of these powerful techniques in various domains.
Vanishing Gradients in Reinforcement Finetuning of Language Models
Oct 31, 2023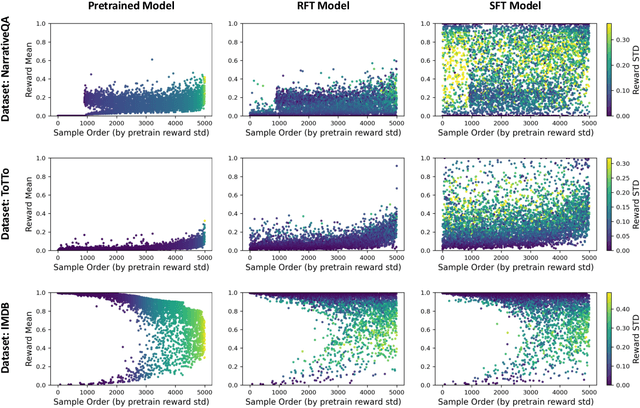
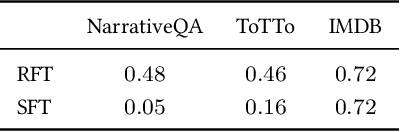
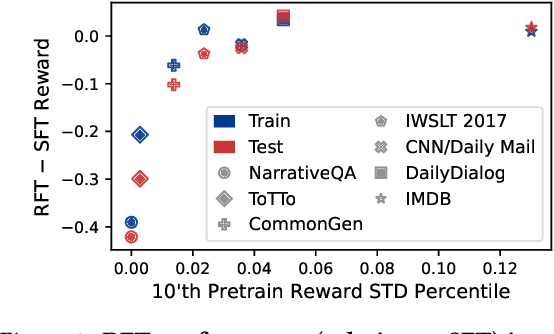
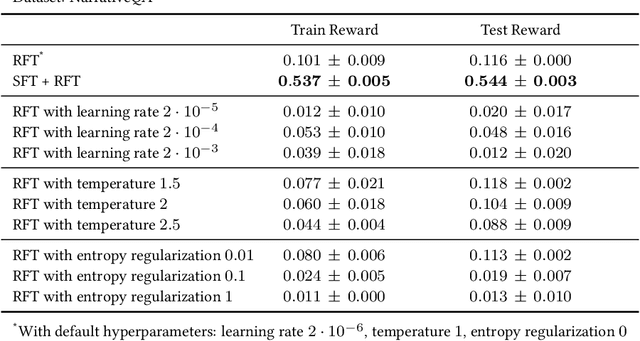
Pretrained language models are commonly aligned with human preferences and downstream tasks via reinforcement finetuning (RFT), which entails maximizing a (possibly learned) reward function using policy gradient algorithms. This work highlights a fundamental optimization obstacle in RFT: we prove that the expected gradient for an input vanishes when its reward standard deviation under the model is small, even if the expected reward is far from optimal. Through experiments on an RFT benchmark and controlled environments, as well as a theoretical analysis, we then demonstrate that vanishing gradients due to small reward standard deviation are prevalent and detrimental, leading to extremely slow reward maximization. Lastly, we explore ways to overcome vanishing gradients in RFT. We find the common practice of an initial supervised finetuning (SFT) phase to be the most promising candidate, which sheds light on its importance in an RFT pipeline. Moreover, we show that a relatively small number of SFT optimization steps on as few as 1% of the input samples can suffice, indicating that the initial SFT phase need not be expensive in terms of compute and data labeling efforts. Overall, our results emphasize that being mindful for inputs whose expected gradient vanishes, as measured by the reward standard deviation, is crucial for successful execution of RFT.
What Algorithms can Transformers Learn? A Study in Length Generalization
Oct 24, 2023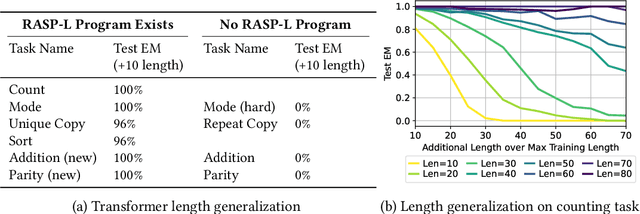
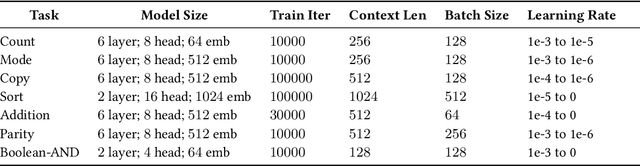

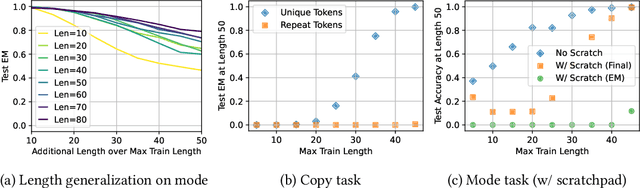
Large language models exhibit surprising emergent generalization properties, yet also struggle on many simple reasoning tasks such as arithmetic and parity. This raises the question of if and when Transformer models can learn the true algorithm for solving a task. We study the scope of Transformers' abilities in the specific setting of length generalization on algorithmic tasks. Here, we propose a unifying framework to understand when and how Transformers can exhibit strong length generalization on a given task. Specifically, we leverage RASP (Weiss et al., 2021) -- a programming language designed for the computational model of a Transformer -- and introduce the RASP-Generalization Conjecture: Transformers tend to length generalize on a task if the task can be solved by a short RASP program which works for all input lengths. This simple conjecture remarkably captures most known instances of length generalization on algorithmic tasks. Moreover, we leverage our insights to drastically improve generalization performance on traditionally hard tasks (such as parity and addition). On the theoretical side, we give a simple example where the "min-degree-interpolator" model of learning from Abbe et al. (2023) does not correctly predict Transformers' out-of-distribution behavior, but our conjecture does. Overall, our work provides a novel perspective on the mechanisms of compositional generalization and the algorithmic capabilities of Transformers.
When can transformers reason with abstract symbols?
Oct 15, 2023

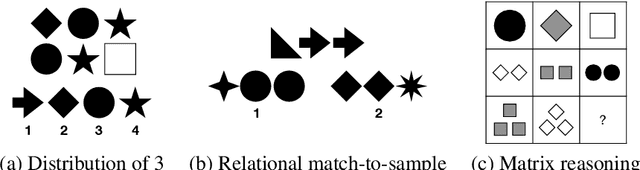
We investigate the capabilities of transformer large language models (LLMs) on relational reasoning tasks involving abstract symbols. Such tasks have long been studied in the neuroscience literature as fundamental building blocks for more complex abilities in programming, mathematics, and verbal reasoning. For (i) regression tasks, we prove that transformers generalize when trained, but require astonishingly large quantities of training data. For (ii) next-token-prediction tasks with symbolic labels, we show an "inverse scaling law": transformers fail to generalize as their embedding dimension increases. For both settings (i) and (ii), we propose subtle transformer modifications which can reduce the amount of data needed by adding two trainable parameters per head.