 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVanishing Gradients in Reinforcement Finetuning of Language Models
Paper and Code
Oct 31, 2023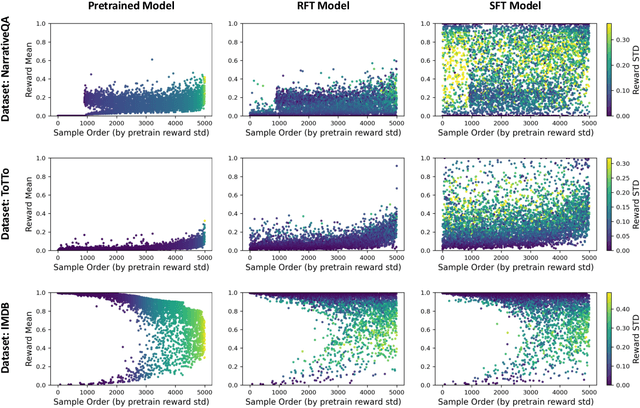
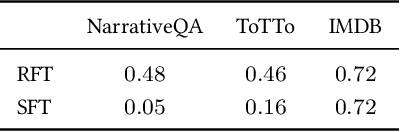
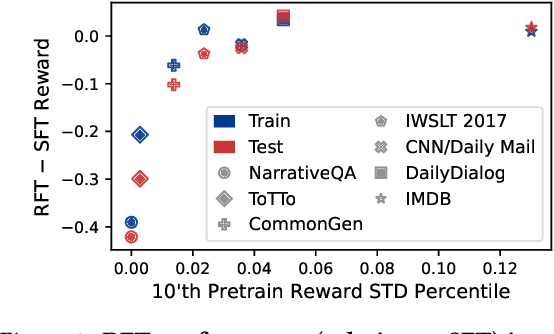
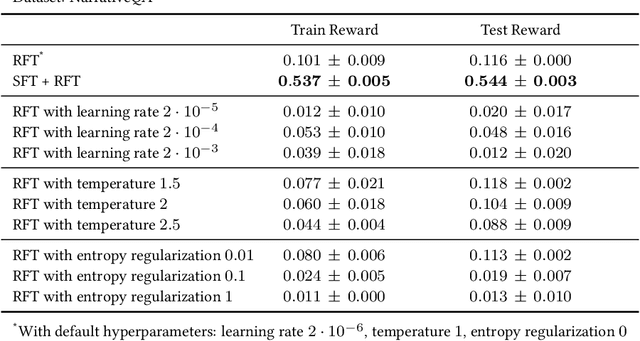
Pretrained language models are commonly aligned with human preferences and downstream tasks via reinforcement finetuning (RFT), which entails maximizing a (possibly learned) reward function using policy gradient algorithms. This work highlights a fundamental optimization obstacle in RFT: we prove that the expected gradient for an input vanishes when its reward standard deviation under the model is small, even if the expected reward is far from optimal. Through experiments on an RFT benchmark and controlled environments, as well as a theoretical analysis, we then demonstrate that vanishing gradients due to small reward standard deviation are prevalent and detrimental, leading to extremely slow reward maximization. Lastly, we explore ways to overcome vanishing gradients in RFT. We find the common practice of an initial supervised finetuning (SFT) phase to be the most promising candidate, which sheds light on its importance in an RFT pipeline. Moreover, we show that a relatively small number of SFT optimization steps on as few as 1% of the input samples can suffice, indicating that the initial SFT phase need not be expensive in terms of compute and data labeling efforts. Overall, our results emphasize that being mindful for inputs whose expected gradient vanishes, as measured by the reward standard deviation, is crucial for successful execution of RFT.