 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivate Federated Learning In Real World Application -- A Case Study
Feb 10, 2025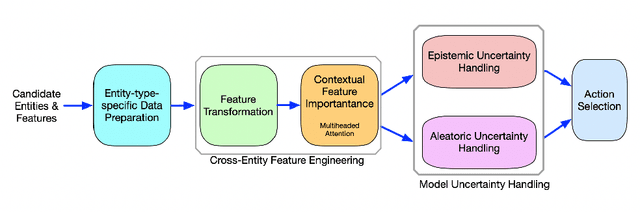

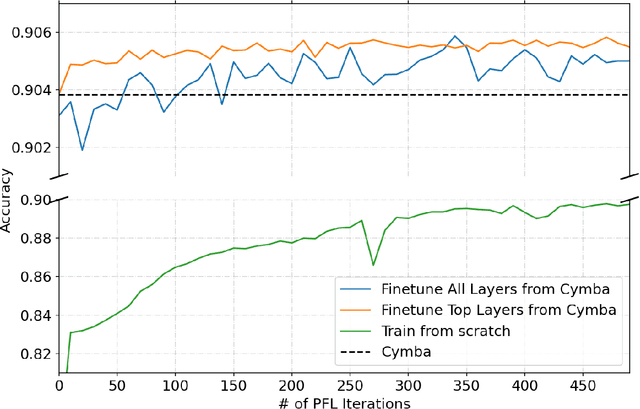
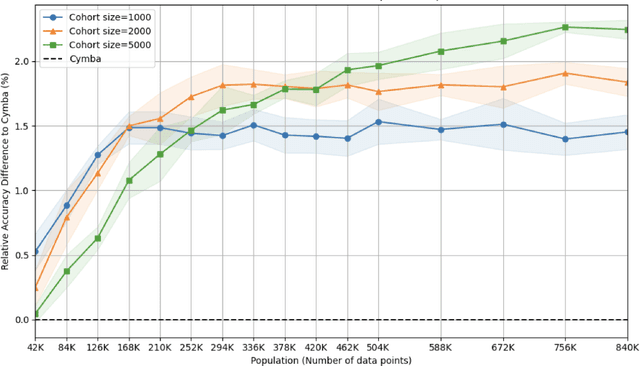
This paper presents an implementation of machine learning model training using private federated learning (PFL) on edge devices. We introduce a novel framework that uses PFL to address the challenge of training a model using users' private data. The framework ensures that user data remain on individual devices, with only essential model updates transmitted to a central server for aggregation with privacy guarantees. We detail the architecture of our app selection model, which incorporates a neural network with attention mechanisms and ambiguity handling through uncertainty management. Experiments conducted through off-line simulations and on device training demonstrate the feasibility of our approach in real-world scenarios. Our results show the potential of PFL to improve the accuracy of an app selection model by adapting to changes in user behavior over time, while adhering to privacy standards. The insights gained from this study are important for industries looking to implement PFL, offering a robust strategy for training a predictive model directly on edge devices while ensuring user data privacy.
UI-JEPA: Towards Active Perception of User Intent through Onscreen User Activity
Sep 06, 2024
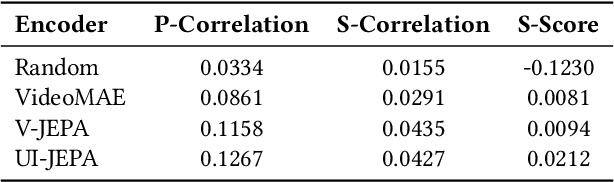


Generating user intent from a sequence of user interface (UI) actions is a core challenge in comprehensive UI understanding. Recent advancements in multimodal large language models (MLLMs) have led to substantial progress in this area, but their demands for extensive model parameters, computing power, and high latency makes them impractical for scenarios requiring lightweight, on-device solutions with low latency or heightened privacy. Additionally, the lack of high-quality datasets has hindered the development of such lightweight models. To address these challenges, we propose UI-JEPA, a novel framework that employs masking strategies to learn abstract UI embeddings from unlabeled data through self-supervised learning, combined with an LLM decoder fine-tuned for user intent prediction. We also introduce two new UI-grounded multimodal datasets, "Intent in the Wild" (IIW) and "Intent in the Tame" (IIT), designed for few-shot and zero-shot UI understanding tasks. IIW consists of 1.7K videos across 219 intent categories, while IIT contains 914 videos across 10 categories. We establish the first baselines for these datasets, showing that representations learned using a JEPA-style objective, combined with an LLM decoder, can achieve user intent predictions that match the performance of state-of-the-art large MLLMs, but with significantly reduced annotation and deployment resources. Measured by intent similarity scores, UI-JEPA outperforms GPT-4 Turbo and Claude 3.5 Sonnet by 10.0% and 7.2% respectively, averaged across two datasets. Notably, UI-JEPA accomplishes the performance with a 50.5x reduction in computational cost and a 6.6x improvement in latency in the IIW dataset. These results underscore the effectiveness of UI-JEPA, highlighting its potential for lightweight, high-performance UI understanding.
DTW-SiameseNet: Dynamic Time Warped Siamese Network for Mispronunciation Detection and Correction
Mar 01, 2023Personal Digital Assistants (PDAs) - such as Siri, Alexa and Google Assistant, to name a few - play an increasingly important role to access information and complete tasks spanning multiple domains, and by diverse groups of users. A text-to-speech (TTS) module allows PDAs to interact in a natural, human-like manner, and play a vital role when the interaction involves people with visual impairments or other disabilities. To cater to the needs of a diverse set of users, inclusive TTS is important to recognize and pronounce correctly text in different languages and dialects. Despite great progress in speech synthesis, the pronunciation accuracy of named entities in a multi-lingual setting still has a large room for improvement. Existing approaches to correct named entity (NE) mispronunciations, like retraining Grapheme-to-Phoneme (G2P) models, or maintaining a TTS pronunciation dictionary, require expensive annotation of the ground truth pronunciation, which is also time consuming. In this work, we present a highly-precise, PDA-compatible pronunciation learning framework for the task of TTS mispronunciation detection and correction. In addition, we also propose a novel mispronunciation detection model called DTW-SiameseNet, which employs metric learning with a Siamese architecture for Dynamic Time Warping (DTW) with triplet loss. We demonstrate that a locale-agnostic, privacy-preserving solution to the problem of TTS mispronunciation detection is feasible. We evaluate our approach on a real-world dataset, and a corpus of NE pronunciations of an anonymized audio dataset of person names recorded by participants from 10 different locales. Human evaluation shows our proposed approach improves pronunciation accuracy on average by ~6% compared to strong phoneme-based and audio-based baselines.