 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoc-to-Atom: Learning to Compile and Compose Memory Atoms
Jun 10, 2026Long input sequences are central to document understanding and multi-step reasoning in Large Language Models, yet the quadratic cost of attention makes inference both memory-intensive and slow. Context distillation mitigates this by compressing contextual information into model parameters, and recent work such as Doc-to-LoRA amortizes context distillation into a single forward pass that generates one LoRA adapter per document. However, producing a single monolithic adapter for all queries leads to irrelevant-query interference, limited compositional recall, and poor scalability to long-document reasoning. To address these challenges, we propose Doc-to-Atom (Doc2Atom), a compositional parametric memory framework that decomposes each document into semantically typed knowledge atoms. Each atom is compiled into an independent micro-LoRA adapter and a provenance retrieval key. At inference time, a lightweight query router selects and assembles only the relevant atoms into a query-specific adapter, which is then injected into a frozen base model. The entire system is trained end-to-end through a multi-objective distillation framework. Experiments on six diverse QA benchmarks demonstrate that Doc2Atom outperforms Doc-to-LoRA baselines while reducing the memory cost of document internalization.
VOYAGER: A Training Free Approach for Generating Diverse Datasets using LLMs
Dec 12, 2025Large language models (LLMs) are increasingly being used to generate synthetic datasets for the evaluation and training of downstream models. However, prior work has noted that such generated data lacks diversity. In this paper, we propose Voyager, a novel principled approach to generate diverse datasets. Our approach is iterative and directly optimizes a mathematical quantity that optimizes the diversity of the dataset using the machinery of determinantal point processes. Furthermore, our approach is training-free, applicable to closed-source models, and scalable. In addition to providing theoretical justification for the working of our method, we also demonstrate through comprehensive experiments that Voyager significantly outperforms popular baseline approaches by providing a 1.5-3x improvement in diversity.
ProTIP: Progressive Tool Retrieval Improves Planning
Dec 16, 2023Large language models (LLMs) are increasingly employed for complex multi-step planning tasks, where the tool retrieval (TR) step is crucial for achieving successful outcomes. Two prevalent approaches for TR are single-step retrieval, which utilizes the complete query, and sequential retrieval using task decomposition (TD), where a full query is segmented into discrete atomic subtasks. While single-step retrieval lacks the flexibility to handle "inter-tool dependency," the TD approach necessitates maintaining "subtask-tool atomicity alignment," as the toolbox can evolve dynamically. To address these limitations, we introduce the Progressive Tool retrieval to Improve Planning (ProTIP) framework. ProTIP is a lightweight, contrastive learning-based framework that implicitly performs TD without the explicit requirement of subtask labels, while simultaneously maintaining subtask-tool atomicity. On the ToolBench dataset, ProTIP outperforms the ChatGPT task decomposition-based approach by a remarkable margin, achieving a 24% improvement in Recall@K=10 for TR and a 41% enhancement in tool accuracy for plan generation.
Context Tuning for Retrieval Augmented Generation
Dec 09, 2023Large language models (LLMs) have the remarkable ability to solve new tasks with just a few examples, but they need access to the right tools. Retrieval Augmented Generation (RAG) addresses this problem by retrieving a list of relevant tools for a given task. However, RAG's tool retrieval step requires all the required information to be explicitly present in the query. This is a limitation, as semantic search, the widely adopted tool retrieval method, can fail when the query is incomplete or lacks context. To address this limitation, we propose Context Tuning for RAG, which employs a smart context retrieval system to fetch relevant information that improves both tool retrieval and plan generation. Our lightweight context retrieval model uses numerical, categorical, and habitual usage signals to retrieve and rank context items. Our empirical results demonstrate that context tuning significantly enhances semantic search, achieving a 3.5-fold and 1.5-fold improvement in Recall@K for context retrieval and tool retrieval tasks respectively, and resulting in an 11.6% increase in LLM-based planner accuracy. Additionally, we show that our proposed lightweight model using Reciprocal Rank Fusion (RRF) with LambdaMART outperforms GPT-4 based retrieval. Moreover, we observe context augmentation at plan generation, even after tool retrieval, reduces hallucination.
DTW-SiameseNet: Dynamic Time Warped Siamese Network for Mispronunciation Detection and Correction
Mar 01, 2023Personal Digital Assistants (PDAs) - such as Siri, Alexa and Google Assistant, to name a few - play an increasingly important role to access information and complete tasks spanning multiple domains, and by diverse groups of users. A text-to-speech (TTS) module allows PDAs to interact in a natural, human-like manner, and play a vital role when the interaction involves people with visual impairments or other disabilities. To cater to the needs of a diverse set of users, inclusive TTS is important to recognize and pronounce correctly text in different languages and dialects. Despite great progress in speech synthesis, the pronunciation accuracy of named entities in a multi-lingual setting still has a large room for improvement. Existing approaches to correct named entity (NE) mispronunciations, like retraining Grapheme-to-Phoneme (G2P) models, or maintaining a TTS pronunciation dictionary, require expensive annotation of the ground truth pronunciation, which is also time consuming. In this work, we present a highly-precise, PDA-compatible pronunciation learning framework for the task of TTS mispronunciation detection and correction. In addition, we also propose a novel mispronunciation detection model called DTW-SiameseNet, which employs metric learning with a Siamese architecture for Dynamic Time Warping (DTW) with triplet loss. We demonstrate that a locale-agnostic, privacy-preserving solution to the problem of TTS mispronunciation detection is feasible. We evaluate our approach on a real-world dataset, and a corpus of NE pronunciations of an anonymized audio dataset of person names recorded by participants from 10 different locales. Human evaluation shows our proposed approach improves pronunciation accuracy on average by ~6% compared to strong phoneme-based and audio-based baselines.
Low-Resource Adaptation of Open-Domain Generative Chatbots
Aug 13, 2021
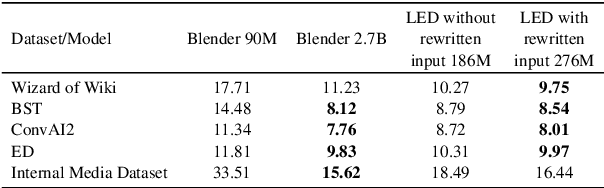
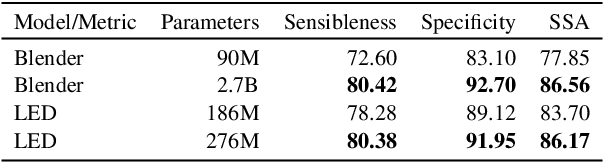
Recent work building open-domain chatbots has demonstrated that increasing model size improves performance. On the other hand, latency and connectivity considerations dictate the move of digital assistants on the device. Giving a digital assistant like Siri, Alexa, or Google Assistant the ability to discuss just about anything leads to the need for reducing the chatbot model size such that it fits on the user's device. We demonstrate that low parameter models can simultaneously retain their general knowledge conversational abilities while improving in a specific domain. Additionally, we propose a generic framework that accounts for variety in question types, tracks reference throughout multi-turn conversations, and removes inconsistent and potentially toxic responses. Our framework seamlessly transitions between chatting and performing transactional tasks, which will ultimately make interactions with digital assistants more human-like. We evaluate our framework on 1 internal and 4 public benchmark datasets using both automatic (Perplexity) and human (SSA - Sensibleness and Specificity Average) evaluation metrics and establish comparable performance while reducing model parameters by 90%.
Open-Domain Question Answering Goes Conversational via Question Rewriting
Oct 10, 2020

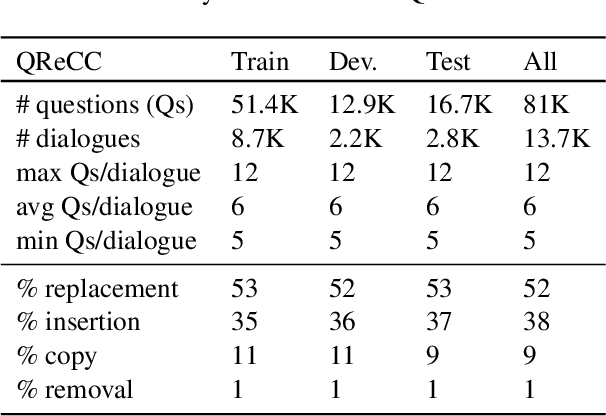
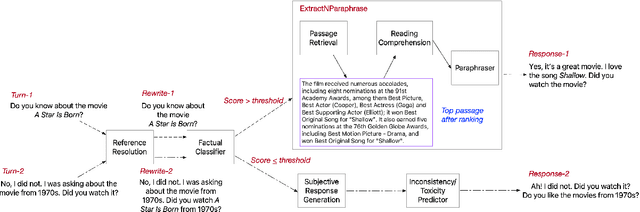
We introduce a new dataset for Question Rewriting in Conversational Context (QReCC), which contains 14K conversations with 81K question-answer pairs. The task in QReCC is to find answers to conversational questions within a collection of 10M web pages (split into 54M passages). Answers to questions in the same conversation may be distributed across several web pages. QReCC provides annotations that allow us to train and evaluate individual subtasks of question rewriting, passage retrieval and reading comprehension required for the end-to-end conversational question answering (QA) task. We report the effectiveness of a strong baseline approach that combines the state-of-the-art model for question rewriting, and competitive models for open-domain QA. Our results set the first baseline for the QReCC dataset with F1 of 19.07, compared to the human upper bound of 74.47, indicating the difficulty of the setup and a large room for improvement.
Generalized Reinforcement Meta Learning for Few-Shot Optimization
May 04, 2020
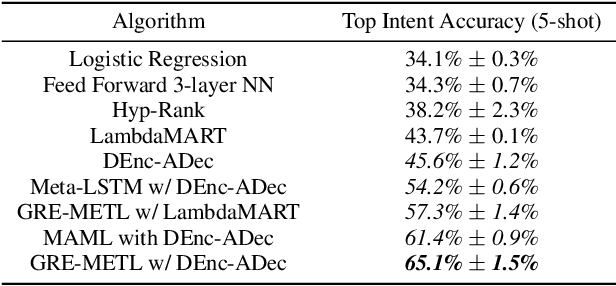
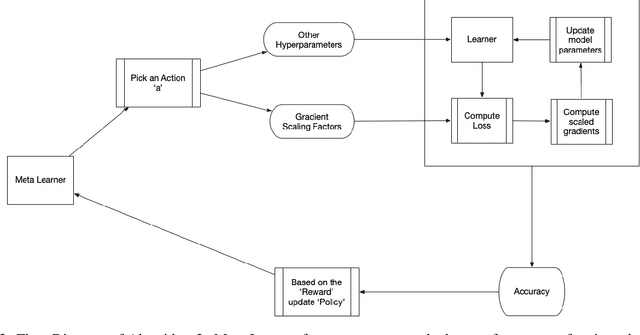

We present a generic and flexible Reinforcement Learning (RL) based meta-learning framework for the problem of few-shot learning. During training, it learns the best optimization algorithm to produce a learner (ranker/classifier, etc) by exploiting stable patterns in loss surfaces. Our method implicitly estimates the gradients of a scaled loss function while retaining the general properties intact for parameter updates. Besides providing improved performance on few-shot tasks, our framework could be easily extended to do network architecture search. We further propose a novel dual encoder, affinity-score based decoder topology that achieves additional improvements to performance. Experiments on an internal dataset, MQ2007, and AwA2 show our approach outperforms existing alternative approaches by 21%, 8%, and 4% respectively on accuracy and NDCG metrics. On Mini-ImageNet dataset our approach achieves comparable results with Prototypical Networks. Empirical evaluations demonstrate that our approach provides a unified and effective framework.
Learning to Rank Intents in Voice Assistants
May 04, 2020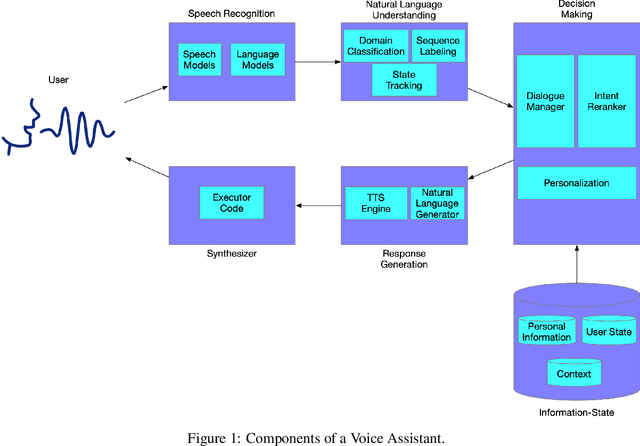

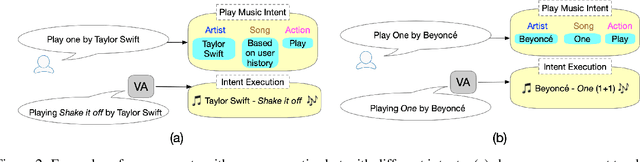
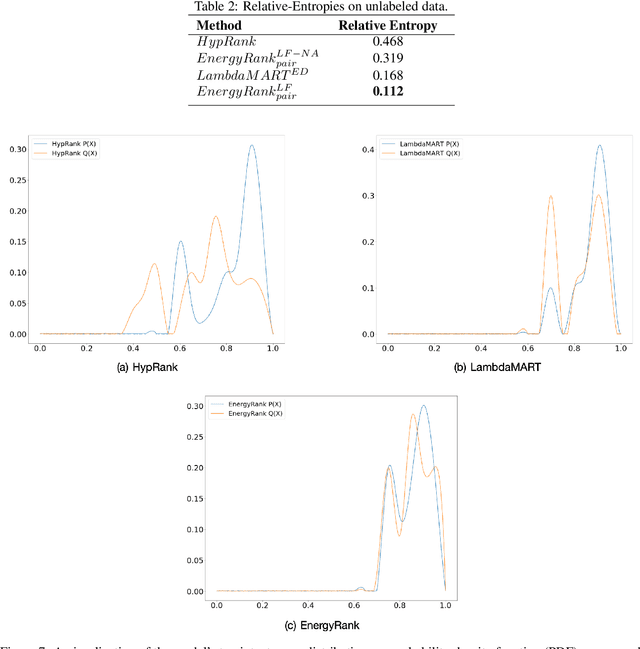
Voice Assistants aim to fulfill user requests by choosing the best intent from multiple options generated by its Automated Speech Recognition and Natural Language Understanding sub-systems. However, voice assistants do not always produce the expected results. This can happen because voice assistants choose from ambiguous intents - user-specific or domain-specific contextual information reduces the ambiguity of the user request. Additionally the user information-state can be leveraged to understand how relevant/executable a specific intent is for a user request. In this work, we propose a novel Energy-based model for the intent ranking task, where we learn an affinity metric and model the trade-off between extracted meaning from speech utterances and relevance/executability aspects of the intent. Furthermore we present a Multisource Denoising Autoencoder based pretraining that is capable of learning fused representations of data from multiple sources. We empirically show our approach outperforms existing state of the art methods by reducing the error-rate by 3.8%, which in turn reduces ambiguity and eliminates undesired dead-ends leading to better user experience. Finally, we evaluate the robustness of our algorithm on the intent ranking task and show our algorithm improves the robustness by 33.3%.