 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIA 2022 Shared Task Submission: Leveraging Entity Representations, Dense-Sparse Hybrids, and Fusion-in-Decoder for Cross-Lingual Question Answering
Jul 18, 2022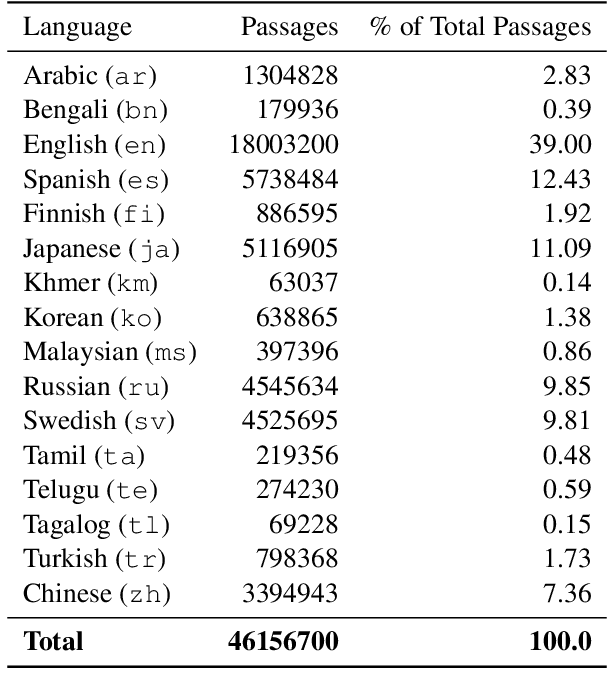


We describe our two-stage system for the Multilingual Information Access (MIA) 2022 Shared Task on Cross-Lingual Open-Retrieval Question Answering. The first stage consists of multilingual passage retrieval with a hybrid dense and sparse retrieval strategy. The second stage consists of a reader which outputs the answer from the top passages returned by the first stage. We show the efficacy of using a multilingual language model with entity representations in pretraining, sparse retrieval signals to help dense retrieval, and Fusion-in-Decoder. On the development set, we obtain 43.46 F1 on XOR-TyDi QA and 21.99 F1 on MKQA, for an average F1 score of 32.73. On the test set, we obtain 40.93 F1 on XOR-TyDi QA and 22.29 F1 on MKQA, for an average F1 score of 31.61. We improve over the official baseline by over 4 F1 points on both the development and test sets.
Leveraging Query Resolution and Reading Comprehension for Conversational Passage Retrieval
Feb 17, 2021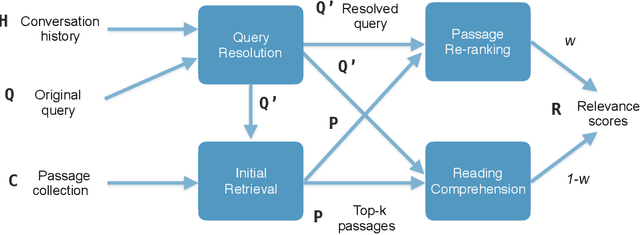
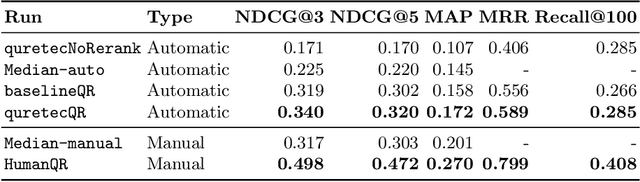

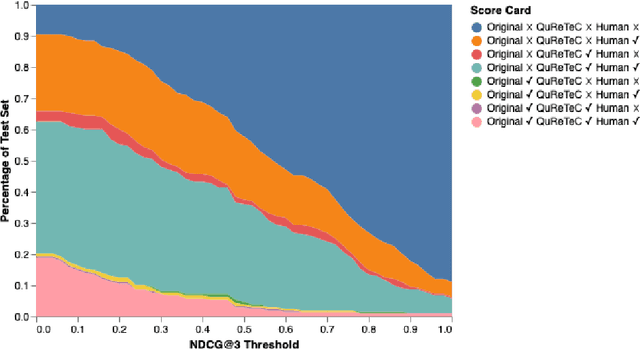
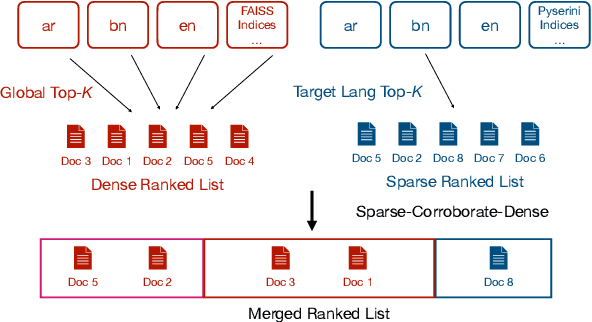
This paper describes the participation of UvA.ILPS group at the TREC CAsT 2020 track. Our passage retrieval pipeline consists of (i) an initial retrieval module that uses BM25, and (ii) a re-ranking module that combines the score of a BERT ranking model with the score of a machine comprehension model adjusted for passage retrieval. An important challenge in conversational passage retrieval is that queries are often under-specified. Thus, we perform query resolution, that is, add missing context from the conversation history to the current turn query using QuReTeC, a term classification query resolution model. We show that our best automatic and manual runs outperform the corresponding median runs by a large margin.
A Comparison of Question Rewriting Methods for Conversational Passage Retrieval
Jan 19, 2021
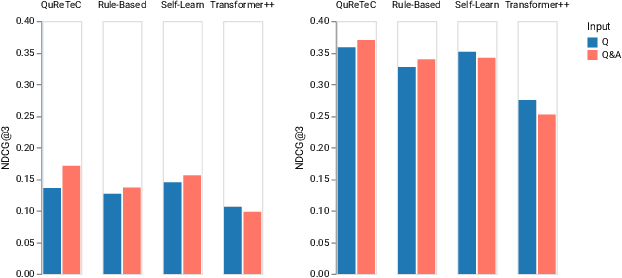
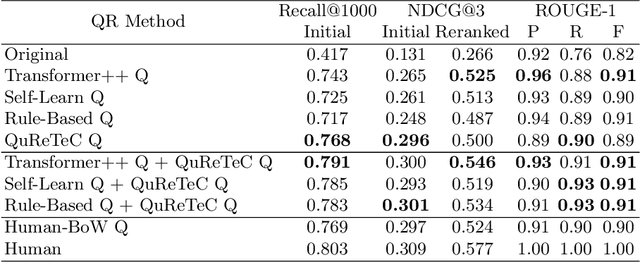
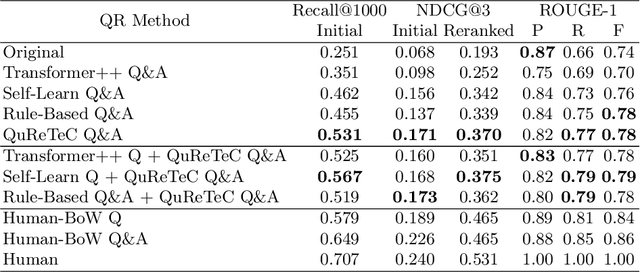
Conversational passage retrieval relies on question rewriting to modify the original question so that it no longer depends on the conversation history. Several methods for question rewriting have recently been proposed, but they were compared under different retrieval pipelines. We bridge this gap by thoroughly evaluating those question rewriting methods on the TREC CAsT 2019 and 2020 datasets under the same retrieval pipeline. We analyze the effect of different types of question rewriting methods on retrieval performance and show that by combining question rewriting methods of different types we can achieve state-of-the-art performance on both datasets.
A Wrong Answer or a Wrong Question? An Intricate Relationship between Question Reformulation and Answer Selection in Conversational Question Answering
Oct 13, 2020

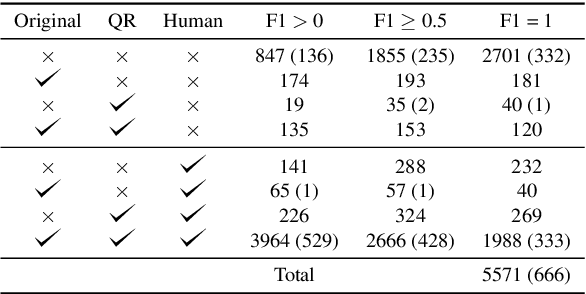

The dependency between an adequate question formulation and correct answer selection is a very intriguing but still underexplored area. In this paper, we show that question rewriting (QR) of the conversational context allows to shed more light on this phenomenon and also use it to evaluate robustness of different answer selection approaches. We introduce a simple framework that enables an automated analysis of the conversational question answering (QA) performance using question rewrites, and present the results of this analysis on the TREC CAsT and QuAC (CANARD) datasets. Our experiments uncover sensitivity to question formulation of the popular state-of-the-art models for reading comprehension and passage ranking. Our results demonstrate that the reading comprehension model is insensitive to question formulation, while the passage ranking changes dramatically with a little variation in the input question. The benefit of QR is that it allows us to pinpoint and group such cases automatically. We show how to use this methodology to verify whether QA models are really learning the task or just finding shortcuts in the dataset, and better understand the frequent types of error they make.
Open-Domain Question Answering Goes Conversational via Question Rewriting
Oct 10, 2020

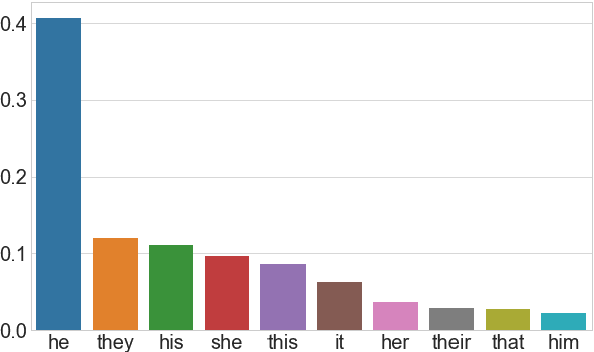
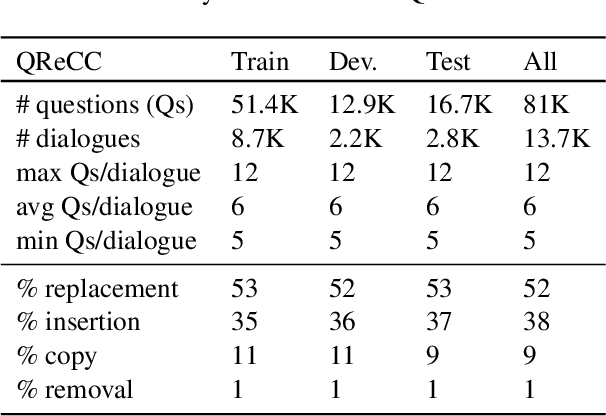
We introduce a new dataset for Question Rewriting in Conversational Context (QReCC), which contains 14K conversations with 81K question-answer pairs. The task in QReCC is to find answers to conversational questions within a collection of 10M web pages (split into 54M passages). Answers to questions in the same conversation may be distributed across several web pages. QReCC provides annotations that allow us to train and evaluate individual subtasks of question rewriting, passage retrieval and reading comprehension required for the end-to-end conversational question answering (QA) task. We report the effectiveness of a strong baseline approach that combines the state-of-the-art model for question rewriting, and competitive models for open-domain QA. Our results set the first baseline for the QReCC dataset with F1 of 19.07, compared to the human upper bound of 74.47, indicating the difficulty of the setup and a large room for improvement.
Question Rewriting for Conversational Question Answering
Apr 30, 2020



Conversational question answering (QA) requires answers conditioned on the previous turns of the conversation. We address the conversational QA task by decomposing it into question rewriting and question answering subtasks, and conduct a systematic evaluation of this approach on two publicly available datasets. Question rewriting is designed to reformulate ambiguous questions, dependent on the conversation context, into unambiguous questions that are fully interpretable outside of the conversation context. Thereby, standard QA components can consume such explicit questions directly. The main benefit of this approach is that the same questions can be used for querying different information sources, e.g., multiple 3rd-party QA services simultaneously, as well as provide a human-readable interpretation of the question in context. To the best of our knowledge, we are the first to evaluate question rewriting on the conversational question answering task and show its improvement over the end-to-end baselines. Moreover, our conversational QA architecture based on question rewriting sets the new state of the art on the TREC CAsT 2019 dataset with a 28% improvement in MAP and 21% in NDCG@3. Our detailed analysis of the evaluation results provide insights into the sensitivity of QA models to question reformulation, and demonstrates the strengths and weaknesses of the retrieval and extractive QA architectures, that should be reflected in their integration.
An Exploration of Data Augmentation and Sampling Techniques for Domain-Agnostic Question Answering
Dec 04, 2019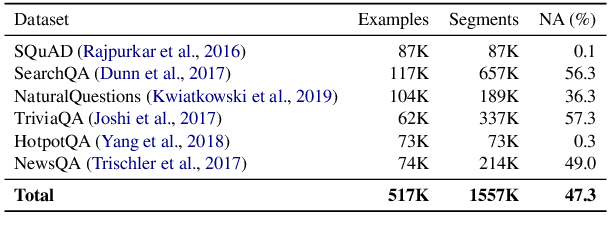
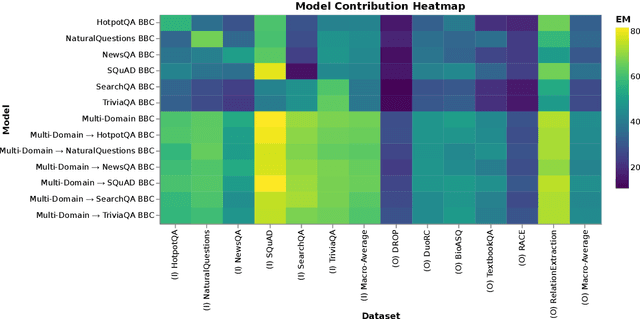
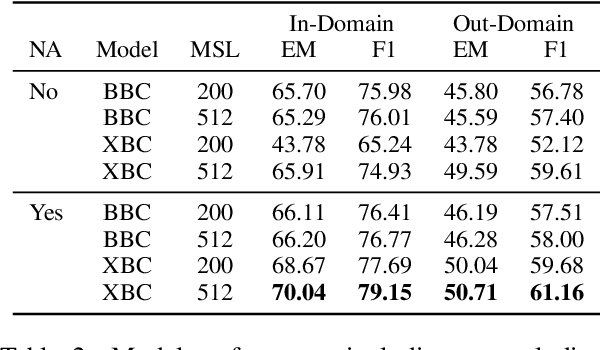
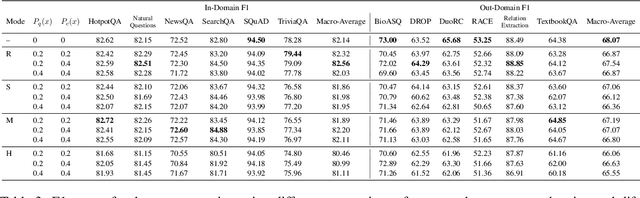
To produce a domain-agnostic question answering model for the Machine Reading Question Answering (MRQA) 2019 Shared Task, we investigate the relative benefits of large pre-trained language models, various data sampling strategies, as well as query and context paraphrases generated by back-translation. We find a simple negative sampling technique to be particularly effective, even though it is typically used for datasets that include unanswerable questions, such as SQuAD 2.0. When applied in conjunction with per-domain sampling, our XLNet (Yang et al., 2019)-based submission achieved the second best Exact Match and F1 in the MRQA leaderboard competition.
* Accepted at the 2nd Workshop on Machine Reading for Question Answering
Exploring the Effectiveness of Convolutional Neural Networks for Answer Selection in End-to-End Question Answering
Jul 25, 2017
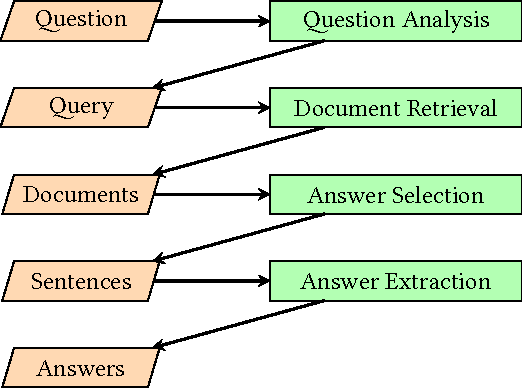

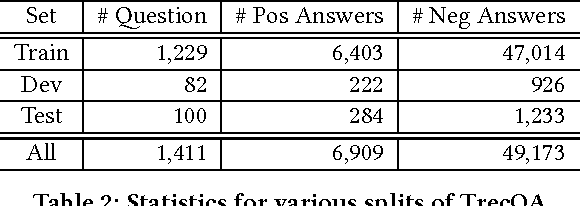
Most work on natural language question answering today focuses on answer selection: given a candidate list of sentences, determine which contains the answer. Although important, answer selection is only one stage in a standard end-to-end question answering pipeline. This paper explores the effectiveness of convolutional neural networks (CNNs) for answer selection in an end-to-end context using the standard TrecQA dataset. We observe that a simple idf-weighted word overlap algorithm forms a very strong baseline, and that despite substantial efforts by the community in applying deep learning to tackle answer selection, the gains are modest at best on this dataset. Furthermore, it is unclear if a CNN is more effective than the baseline in an end-to-end context based on standard retrieval metrics. To further explore this finding, we conducted a manual user evaluation, which confirms that answers from the CNN are detectably better than those from idf-weighted word overlap. This result suggests that users are sensitive to relatively small differences in answer selection quality.