 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIA 2022 Shared Task Submission: Leveraging Entity Representations, Dense-Sparse Hybrids, and Fusion-in-Decoder for Cross-Lingual Question Answering
Jul 18, 2022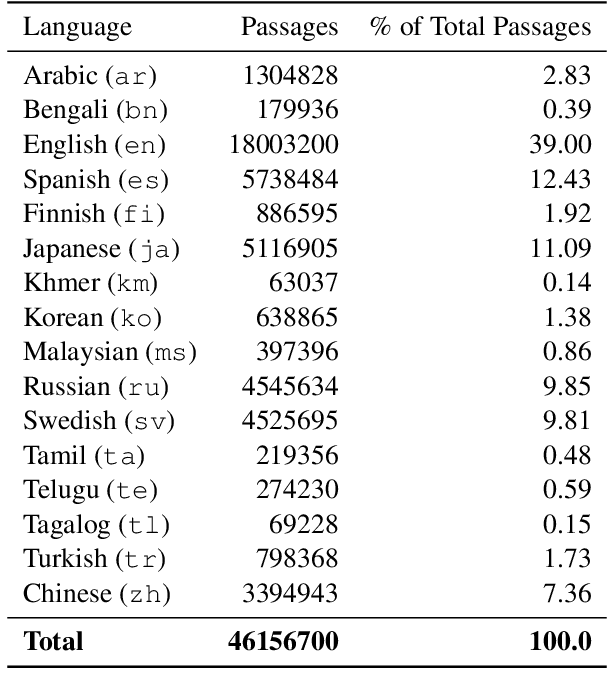
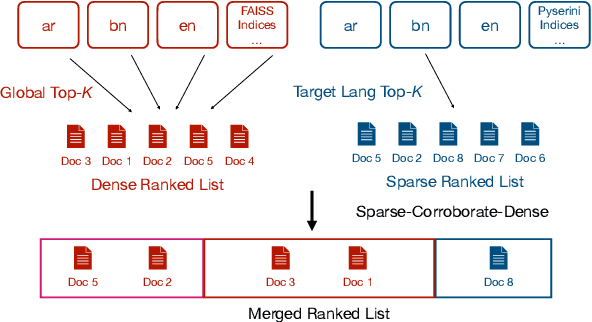


We describe our two-stage system for the Multilingual Information Access (MIA) 2022 Shared Task on Cross-Lingual Open-Retrieval Question Answering. The first stage consists of multilingual passage retrieval with a hybrid dense and sparse retrieval strategy. The second stage consists of a reader which outputs the answer from the top passages returned by the first stage. We show the efficacy of using a multilingual language model with entity representations in pretraining, sparse retrieval signals to help dense retrieval, and Fusion-in-Decoder. On the development set, we obtain 43.46 F1 on XOR-TyDi QA and 21.99 F1 on MKQA, for an average F1 score of 32.73. On the test set, we obtain 40.93 F1 on XOR-TyDi QA and 22.29 F1 on MKQA, for an average F1 score of 31.61. We improve over the official baseline by over 4 F1 points on both the development and test sets.
Resolving Implicit Coordination in Multi-Agent Deep Reinforcement Learning with Deep Q-Networks & Game Theory
Dec 08, 2020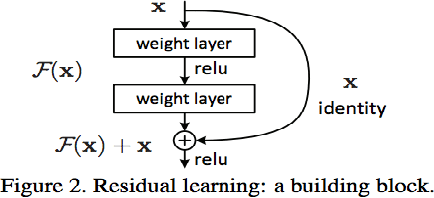



We address two major challenges of implicit coordination in multi-agent deep reinforcement learning: non-stationarity and exponential growth of state-action space, by combining Deep-Q Networks for policy learning with Nash equilibrium for action selection. Q-values proxy as payoffs in Nash settings, and mutual best responses define joint action selection. Coordination is implicit because multiple/no Nash equilibria are resolved deterministically. We demonstrate that knowledge of game type leads to an assumption of mirrored best responses and faster convergence than Nash-Q. Specifically, the Friend-or-Foe algorithm demonstrates signs of convergence to a Set Controller which jointly chooses actions for two agents. This encouraging given the highly unstable nature of decentralized coordination over joint actions. Inspired by the dueling network architecture, which decouples the Q-function into state and advantage streams, as well as residual networks, we learn both a single and joint agent representation, and merge them via element-wise addition. This simplifies coordination by recasting it is as learning a residual function. We also draw high level comparative insights on key MADRL and game theoretic variables: competitive vs. cooperative, asynchronous vs. parallel learning, greedy versus socially optimal Nash equilibria tie breaking, and strategies for the no Nash equilibrium case. We evaluate on 3 custom environments written in Python using OpenAI Gym: a Predator Prey environment, an alternating Warehouse environment, and a Synchronization environment. Each environment requires successively more coordination to achieve positive rewards.
When and Why are Pre-trained Word Embeddings Useful for Neural Machine Translation?
Apr 18, 2018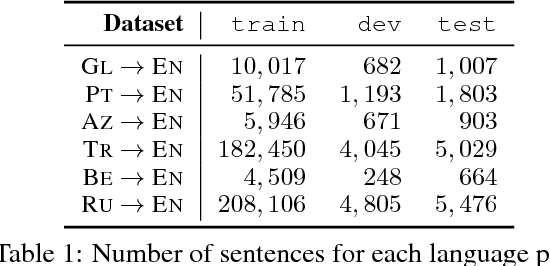
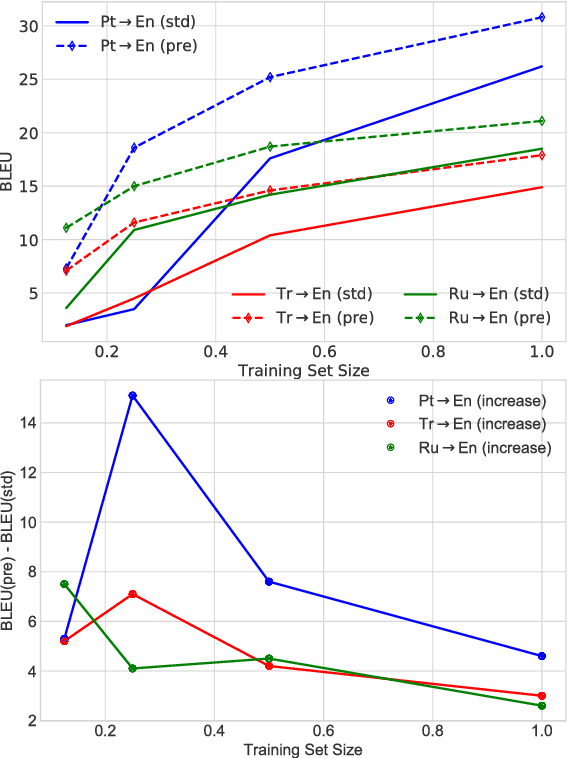
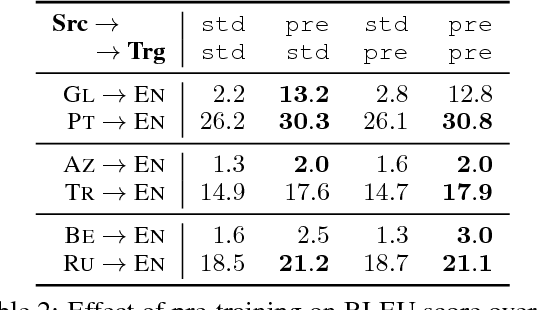
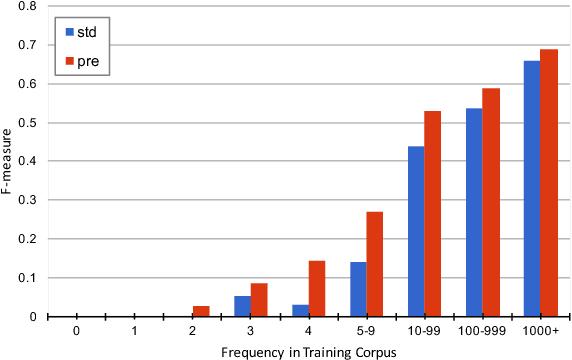
The performance of Neural Machine Translation (NMT) systems often suffers in low-resource scenarios where sufficiently large-scale parallel corpora cannot be obtained. Pre-trained word embeddings have proven to be invaluable for improving performance in natural language analysis tasks, which often suffer from paucity of data. However, their utility for NMT has not been extensively explored. In this work, we perform five sets of experiments that analyze when we can expect pre-trained word embeddings to help in NMT tasks. We show that such embeddings can be surprisingly effective in some cases -- providing gains of up to 20 BLEU points in the most favorable setting.