 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResolving Implicit Coordination in Multi-Agent Deep Reinforcement Learning with Deep Q-Networks & Game Theory
Dec 08, 2020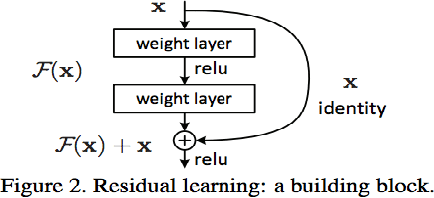



We address two major challenges of implicit coordination in multi-agent deep reinforcement learning: non-stationarity and exponential growth of state-action space, by combining Deep-Q Networks for policy learning with Nash equilibrium for action selection. Q-values proxy as payoffs in Nash settings, and mutual best responses define joint action selection. Coordination is implicit because multiple/no Nash equilibria are resolved deterministically. We demonstrate that knowledge of game type leads to an assumption of mirrored best responses and faster convergence than Nash-Q. Specifically, the Friend-or-Foe algorithm demonstrates signs of convergence to a Set Controller which jointly chooses actions for two agents. This encouraging given the highly unstable nature of decentralized coordination over joint actions. Inspired by the dueling network architecture, which decouples the Q-function into state and advantage streams, as well as residual networks, we learn both a single and joint agent representation, and merge them via element-wise addition. This simplifies coordination by recasting it is as learning a residual function. We also draw high level comparative insights on key MADRL and game theoretic variables: competitive vs. cooperative, asynchronous vs. parallel learning, greedy versus socially optimal Nash equilibria tie breaking, and strategies for the no Nash equilibrium case. We evaluate on 3 custom environments written in Python using OpenAI Gym: a Predator Prey environment, an alternating Warehouse environment, and a Synchronization environment. Each environment requires successively more coordination to achieve positive rewards.